 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePairwise Matching of Intermediate Representations for Fine-grained Explainability
Mar 28, 2025



The differences between images belonging to fine-grained categories are often subtle and highly localized, and existing explainability techniques for deep learning models are often too diffuse to provide useful and interpretable explanations. We propose a new explainability method (PAIR-X) that leverages both intermediate model activations and backpropagated relevance scores to generate fine-grained, highly-localized pairwise visual explanations. We use animal and building re-identification (re-ID) as a primary case study of our method, and we demonstrate qualitatively improved results over a diverse set of explainability baselines on 35 public re-ID datasets. In interviews, animal re-ID experts were in unanimous agreement that PAIR-X was an improvement over existing baselines for deep model explainability, and suggested that its visualizations would be directly applicable to their work. We also propose a novel quantitative evaluation metric for our method, and demonstrate that PAIR-X visualizations appear more plausible for correct image matches than incorrect ones even when the model similarity score for the pairs is the same. By improving interpretability, PAIR-X enables humans to better distinguish correct and incorrect matches. Our code is available at: https://github.com/pairx-explains/pairx
Gaussian Processes for Monitoring Air-Quality in Kampala
Nov 28, 2023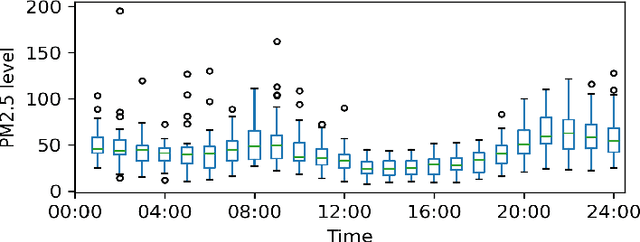
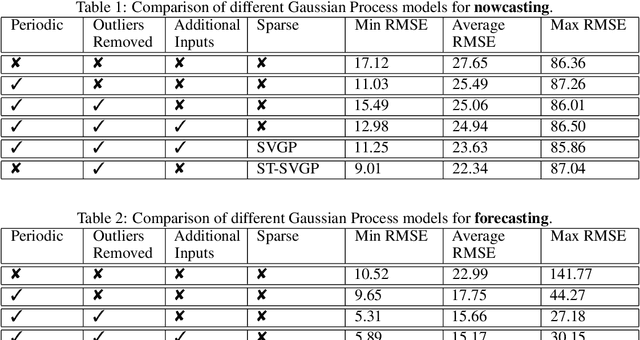
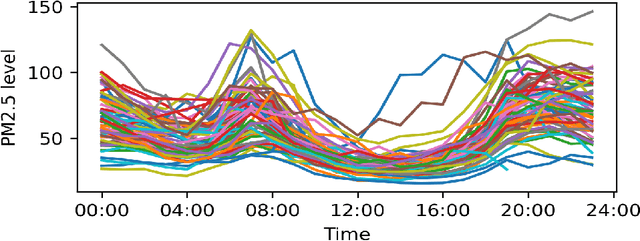
Monitoring air pollution is of vital importance to the overall health of the population. Unfortunately, devices that can measure air quality can be expensive, and many cities in low and middle-income countries have to rely on a sparse allocation of them. In this paper, we investigate the use of Gaussian Processes for both nowcasting the current air-pollution in places where there are no sensors and forecasting the air-pollution in the future at the sensor locations. In particular, we focus on the city of Kampala in Uganda, using data from AirQo's network of sensors. We demonstrate the advantage of removing outliers, compare different kernel functions and additional inputs. We also compare two sparse approximations to allow for the large amounts of temporal data in the dataset.