 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOpen-Set Recognition of Novel Species in Biodiversity Monitoring
Mar 03, 2025Machine learning is increasingly being applied to facilitate long-term, large-scale biodiversity monitoring. With most species on Earth still undiscovered or poorly documented, species-recognition models are expected to encounter new species during deployment. We introduce Open-Insects, a fine-grained image recognition benchmark dataset for open-set recognition and out-of-distribution detection in biodiversity monitoring. Open-Insects makes it possible to evaluate algorithms for new species detection on several geographical open-set splits with varying difficulty. Furthermore, we present a test set recently collected in the wild with 59 species that are likely new to science. We evaluate a variety of open-set recognition algorithms, including post-hoc methods, training-time regularization, and training with auxiliary data, finding that the simple post-hoc approach of utilizing softmax scores remains a strong baseline. We also demonstrate how to leverage auxiliary data to improve the detection performance when the training dataset is limited. Our results provide timely insights to guide the development of computer vision methods for biodiversity monitoring and species discovery.
VLDBench: Vision Language Models Disinformation Detection Benchmark
Feb 17, 2025



The rapid rise of AI-generated content has made detecting disinformation increasingly challenging. In particular, multimodal disinformation, i.e., online posts-articles that contain images and texts with fabricated information are specially designed to deceive. While existing AI safety benchmarks primarily address bias and toxicity, multimodal disinformation detection remains largely underexplored. To address this challenge, we present the Vision-Language Disinformation Detection Benchmark VLDBench, the first comprehensive benchmark for detecting disinformation across both unimodal (text-only) and multimodal (text and image) content, comprising 31,000} news article-image pairs, spanning 13 distinct categories, for robust evaluation. VLDBench features a rigorous semi-automated data curation pipeline, with 22 domain experts dedicating 300 plus hours} to annotation, achieving a strong inter-annotator agreement (Cohen kappa = 0.78). We extensively evaluate state-of-the-art Large Language Models (LLMs) and Vision-Language Models (VLMs), demonstrating that integrating textual and visual cues in multimodal news posts improves disinformation detection accuracy by 5 - 35 % compared to unimodal models. Developed in alignment with AI governance frameworks such as the EU AI Act, NIST guidelines, and the MIT AI Risk Repository 2024, VLDBench is expected to become a benchmark for detecting disinformation in online multi-modal contents. Our code and data will be publicly available.
Insect Identification in the Wild: The AMI Dataset
Jun 18, 2024
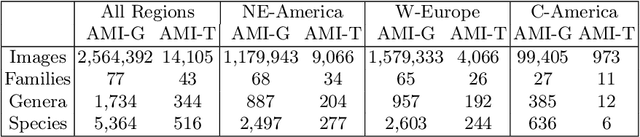


Insects represent half of all global biodiversity, yet many of the world's insects are disappearing, with severe implications for ecosystems and agriculture. Despite this crisis, data on insect diversity and abundance remain woefully inadequate, due to the scarcity of human experts and the lack of scalable tools for monitoring. Ecologists have started to adopt camera traps to record and study insects, and have proposed computer vision algorithms as an answer for scalable data processing. However, insect monitoring in the wild poses unique challenges that have not yet been addressed within computer vision, including the combination of long-tailed data, extremely similar classes, and significant distribution shifts. We provide the first large-scale machine learning benchmarks for fine-grained insect recognition, designed to match real-world tasks faced by ecologists. Our contributions include a curated dataset of images from citizen science platforms and museums, and an expert-annotated dataset drawn from automated camera traps across multiple continents, designed to test out-of-distribution generalization under field conditions. We train and evaluate a variety of baseline algorithms and introduce a combination of data augmentation techniques that enhance generalization across geographies and hardware setups. Code and datasets are made publicly available.
A machine learning pipeline for automated insect monitoring
Jun 18, 2024

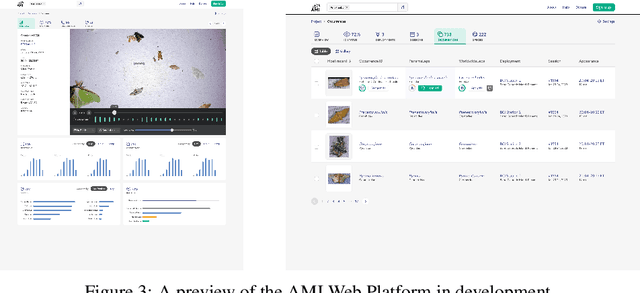

Climate change and other anthropogenic factors have led to a catastrophic decline in insects, endangering both biodiversity and the ecosystem services on which human society depends. Data on insect abundance, however, remains woefully inadequate. Camera traps, conventionally used for monitoring terrestrial vertebrates, are now being modified for insects, especially moths. We describe a complete, open-source machine learning-based software pipeline for automated monitoring of moths via camera traps, including object detection, moth/non-moth classification, fine-grained identification of moth species, and tracking individuals. We believe that our tools, which are already in use across three continents, represent the future of massively scalable data collection in entomology.
Agonist-Antagonist Pouch Motors: Bidirectional Soft Actuators Enhanced by Thermally Responsive Peltier Elements
Mar 16, 2024



In this study, we introduce a novel Mylar-based pouch motor design that leverages the reversible actuation capabilities of Peltier junctions to enable agonist-antagonist muscle mimicry in soft robotics. Addressing the limitations of traditional silicone-based materials, such as leakage and phase-change fluid degradation, our pouch motors filled with Novec 7000 provide a durable and leak-proof solution for geometric modeling. The integration of flexible Peltier junctions offers a significant advantage over conventional Joule heating methods by allowing active and reversible heating and cooling cycles. This innovation not only enhances the reliability and longevity of soft robotic applications but also broadens the scope of design possibilities, including the development of agonist-antagonist artificial muscles, grippers with can manipulate through flexion and extension, and an anchor-slip style simple crawler design. Our findings indicate that this approach could lead to more efficient, versatile, and durable robotic systems, marking a significant advancement in the field of soft robotics.
Generation Z's Ability to Discriminate Between AI-generated and Human-Authored Text on Discord
Dec 31, 2023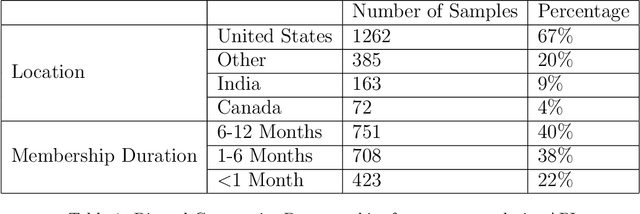

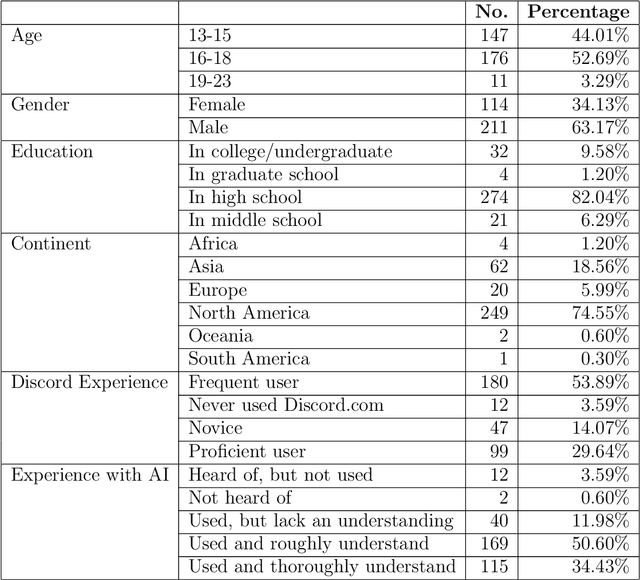
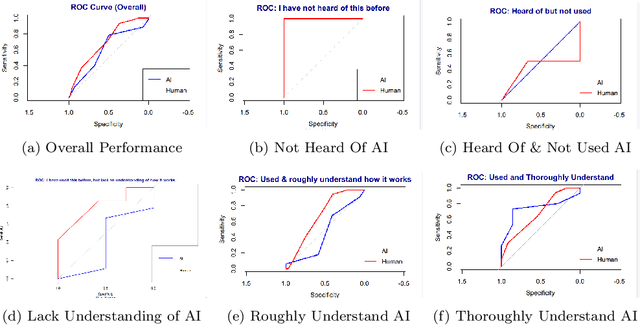
The growing popularity of generative artificial intelligence (AI) chatbots such as ChatGPT is having transformative effects on social media. As the prevalence of AI-generated content grows, concerns have been raised regarding privacy and misinformation online. Among social media platforms, Discord enables AI integrations -- making their primarily "Generation Z" userbase particularly exposed to AI-generated content. We surveyed Generation Z aged individuals (n = 335) to evaluate their proficiency in discriminating between AI-generated and human-authored text on Discord. The investigation employed one-shot prompting of ChatGPT, disguised as a text message received on the Discord.com platform. We explore the influence of demographic factors on ability, as well as participants' familiarity with Discord and artificial intelligence technologies. We find that Generation Z individuals are unable to discern between AI and human-authored text (p = 0.011), and that those with lower self-reported familiarity with Discord demonstrated an improved ability in identifying human-authored compared to those with self-reported experience with AI (p << 0.0001). Our results suggest that there is a nuanced relationship between AI technology and popular modes of communication for Generation Z, contributing valuable insights into human-computer interactions, digital communication, and artificial intelligence literacy.
Generator Assisted Mixture of Experts For Feature Acquisition in Batch
Dec 19, 2023

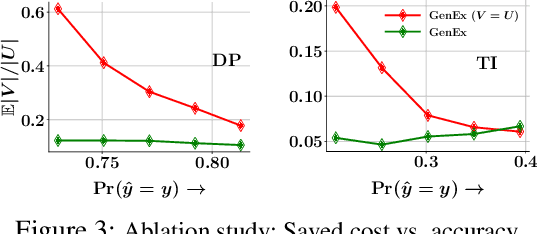

Given a set of observations, feature acquisition is about finding the subset of unobserved features which would enhance accuracy. Such problems have been explored in a sequential setting in prior work. Here, the model receives feedback from every new feature acquired and chooses to explore more features or to predict. However, sequential acquisition is not feasible in some settings where time is of the essence. We consider the problem of feature acquisition in batch, where the subset of features to be queried in batch is chosen based on the currently observed features, and then acquired as a batch, followed by prediction. We solve this problem using several technical innovations. First, we use a feature generator to draw a subset of the synthetic features for some examples, which reduces the cost of oracle queries. Second, to make the feature acquisition problem tractable for the large heterogeneous observed features, we partition the data into buckets, by borrowing tools from locality sensitive hashing and then train a mixture of experts model. Third, we design a tractable lower bound of the original objective. We use a greedy algorithm combined with model training to solve the underlying problem. Experiments with four datasets show that our approach outperforms these methods in terms of trade-off between accuracy and feature acquisition cost.
muBoost: An Effective Method for Solving Indic Multilingual Text Classification Problem
Jun 21, 2022
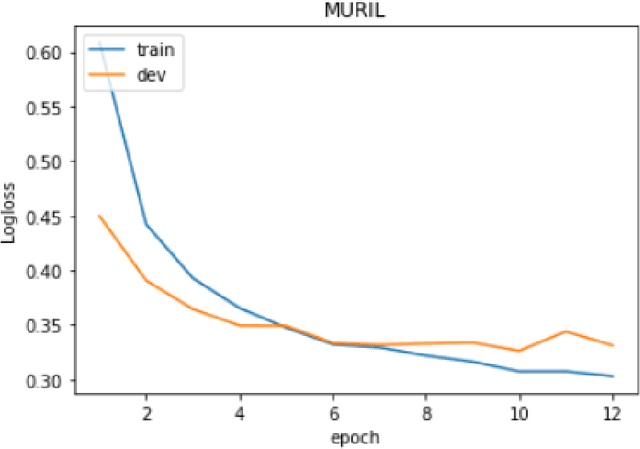
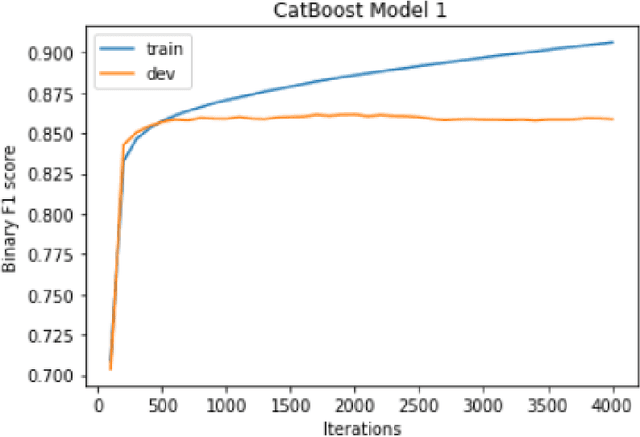
Text Classification is an integral part of many Natural Language Processing tasks such as sarcasm detection, sentiment analysis and many more such applications. Many e-commerce websites, social-media/entertainment platforms use such models to enhance user-experience to generate traffic and thus, revenue on their platforms. In this paper, we are presenting our solution to Multilingual Abusive Comment Identification Problem on Moj, an Indian video-sharing social networking service, powered by ShareChat. The problem dealt with detecting abusive comments, in 13 regional Indic languages such as Hindi, Telugu, Kannada etc., on the videos on Moj platform. Our solution utilizes the novel muBoost, an ensemble of CatBoost classifier models and Multilingual Representations for Indian Languages (MURIL) model, to produce SOTA performance on Indic text classification tasks. We were able to achieve a mean F1-score of 89.286 on the test data, an improvement over baseline MURIL model with a F1-score of 87.48.
Machine Learning in Sports: A Case Study on Using Explainable Models for Predicting Outcomes of Volleyball Matches
Jun 18, 2022


Machine Learning has become an integral part of engineering design and decision making in several domains, including sports. Deep Neural Networks (DNNs) have been the state-of-the-art methods for predicting outcomes of professional sports events. However, apart from getting highly accurate predictions on these sports events outcomes, it is necessary to answer questions such as "Why did the model predict that Team A would win Match X against Team B?" DNNs are inherently black-box in nature. Therefore, it is required to provide high-quality interpretable, and understandable explanations for a model's prediction in sports. This paper explores a two-phased Explainable Artificial Intelligence(XAI) approach to predict outcomes of matches in the Brazilian volleyball League (SuperLiga). In the first phase, we directly use the interpretable rule-based ML models that provide a global understanding of the model's behaviors based on Boolean Rule Column Generation (BRCG; extracts simple AND-OR classification rules) and Logistic Regression (LogReg; allows to estimate the feature importance scores). In the second phase, we construct non-linear models such as Support Vector Machine (SVM) and Deep Neural Network (DNN) to obtain predictive performance on the volleyball matches' outcomes. We construct the "post-hoc" explanations for each data instance using ProtoDash, a method that finds prototypes in the training dataset that are most similar to the test instance, and SHAP, a method that estimates the contribution of each feature on the model's prediction. We evaluate the SHAP explanations using the faithfulness metric. Our results demonstrate the effectiveness of the explanations for the model's predictions.
Solving Fashion Recommendation -- The Farfetch Challenge
Aug 03, 2021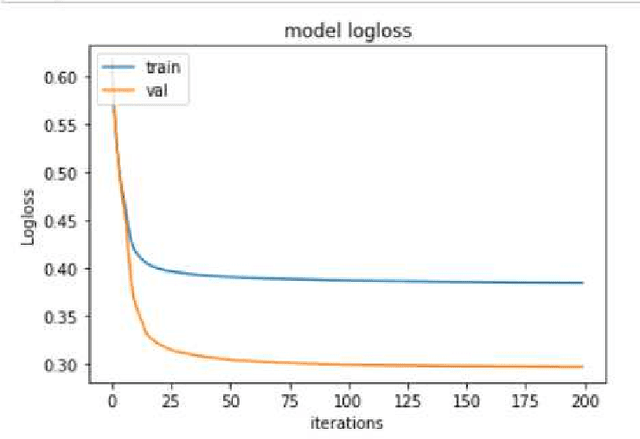
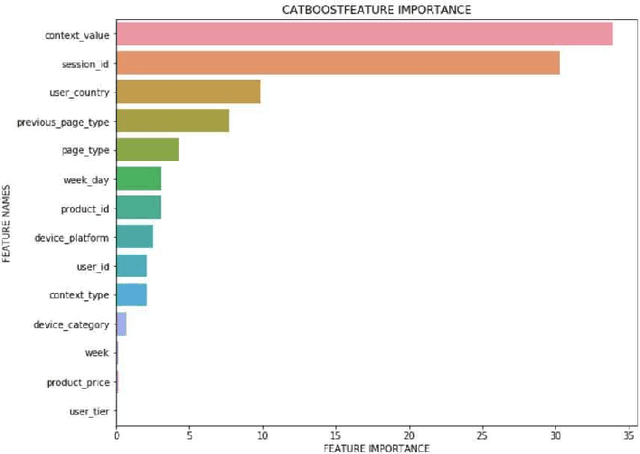
Recommendation engines are integral to the modern e-commerce experience, both for the seller and the end user. Accurate recommendations lead to higher revenue and better user experience. In this paper, we are presenting our solution to ECML PKDD Farfetch Fashion Recommendation Challenge.The goal of this challenge is to maximize the chances of a click when the users are presented with set of fashion items. We have approached this problem as a binary classification problem. Our winning solution utilizes Catboost as the classifier and Bayesian Optimization for hyper parameter tuning. Our baseline model achieved MRR of 0.5153 on the validation set. Bayesian optimization of hyper parameters improved the MRR to 0.5240 on the validation set. Our final submission on the test set achieved a MRR of 0.5257.