 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTVIM: Thermo-Active Variable Impedance Module: Evaluating Shear-Mode Capabilities of Polycaprolactone
Mar 16, 2024



In this work, we introduce an advanced thermo-active variable impedance module which builds upon our previous innovation in thermal-based impedance adjustment for actuation systems. Our initial design harnessed the temperature-responsive, viscoelastic properties of Polycaprolactone (PCL) to modulate stiffness and damping, facilitated by integrated flexible Peltier elements. While effective, the reliance on compressing and the inherent stress relaxation characteristics of PCL led to suboptimal response times in impedance adjustments. Addressing these limitations, the current iteration of our module pivots to a novel 'shear-mode' operation. By conducting comprehensive shear rheology analyses on PCL, we have identified a configuration that eliminates the viscoelastic delay, offering a faster response with improved heat transfer efficiency. A key advantage of our module lies in its scalability and elimination of additional mechanical actuators for impedance adjustment. The compactness and efficiency of thermal actuation through Peltier elements allow for significant downsizing, making these thermal, variable impedance modules exceptionally well-suited for applications where space constraints and actuator weight are critical considerations. This development represents a significant leap forward in the design of variable impedance actuators, offering a more versatile, responsive, and compact solution for a wide range of robotic and biomechanical applications.
Agonist-Antagonist Pouch Motors: Bidirectional Soft Actuators Enhanced by Thermally Responsive Peltier Elements
Mar 16, 2024



In this study, we introduce a novel Mylar-based pouch motor design that leverages the reversible actuation capabilities of Peltier junctions to enable agonist-antagonist muscle mimicry in soft robotics. Addressing the limitations of traditional silicone-based materials, such as leakage and phase-change fluid degradation, our pouch motors filled with Novec 7000 provide a durable and leak-proof solution for geometric modeling. The integration of flexible Peltier junctions offers a significant advantage over conventional Joule heating methods by allowing active and reversible heating and cooling cycles. This innovation not only enhances the reliability and longevity of soft robotic applications but also broadens the scope of design possibilities, including the development of agonist-antagonist artificial muscles, grippers with can manipulate through flexion and extension, and an anchor-slip style simple crawler design. Our findings indicate that this approach could lead to more efficient, versatile, and durable robotic systems, marking a significant advancement in the field of soft robotics.
Towards a Unified Naming Scheme for Thermo-Active Soft Actuators: A Review of Materials, Working Principles, and Applications
Dec 11, 2023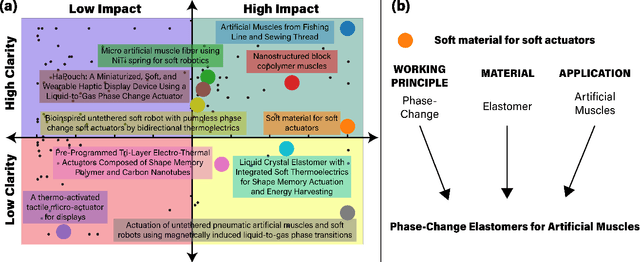
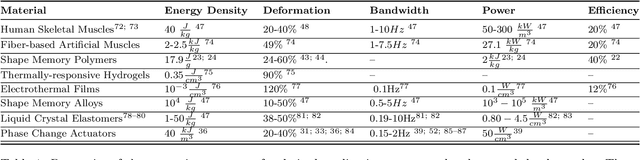
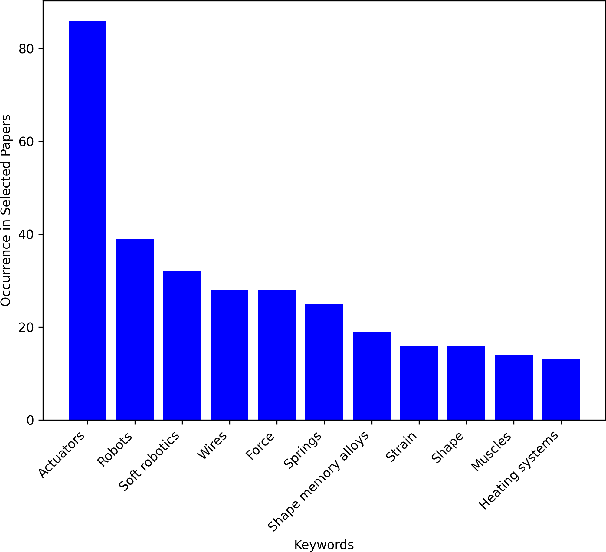
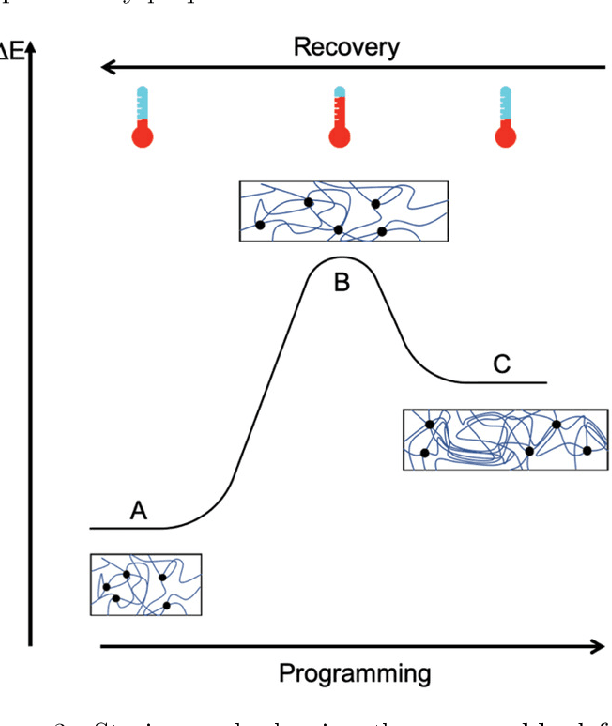
Soft robotics is a rapidly growing field that spans the fields of chemistry, materials science, and engineering. Due to the diverse background of the field, there have been contrasting naming schemes such as 'intelligent', 'smart' and 'adaptive' materials which add vagueness to the broad innovation among literature. Therefore, a clear, functional and descriptive naming scheme is proposed in which a previously vague name -- Soft Material for Soft Actuators -- can remain clear and concise -- Phase-Change Elastomers for Artificial Muscles. By synthesizing the working principle, material, and application into a naming scheme, the searchability of soft robotics can be enhanced and applied to other fields. The field of thermo-active soft actuators spans multiple domains and requires added clarity. Thermo-active actuators have potential for a variety of applications spanning virtual reality haptics to assistive devices. This review offers a comprehensive guide to selecting the type of thermo-active actuator when one has an application in mind. Additionally, it discusses future directions and improvements that are necessary for implementation.
Comparison Study Between Token Classification and Sequence Classification In Text Classification
Nov 25, 2022



Unsupervised Machine Learning techniques have been applied to Natural Language Processing tasks and surpasses the benchmarks such as GLUE with great success. Building language models approach achieves good results in one language and it can be applied to multiple NLP task such as classification, summarization, generation and etc as an out of box model. Among all the of the classical approaches used in NLP, the masked language modeling is the most used. In general, the only requirement to build a language model is presence of the large corpus of textual data. Text classification engines uses a variety of models from classical and state of art transformer models to classify texts for in order to save costs. Sequence Classifiers are mostly used in the domain of text classification. However Token classifiers also are viable candidate models as well. Sequence Classifiers and Token Classifier both tend to improve the classification predictions due to the capturing the context information differently. This work aims to compare the performance of Sequence Classifier and Token Classifiers and evaluate each model on the same set of data. In this work, we are using a pre-trained model as the base model and Token Classifier and Sequence Classier heads results of these two scoring paradigms with be compared..
A Deep Learning Anomaly Detection Method in Textual Data
Nov 25, 2022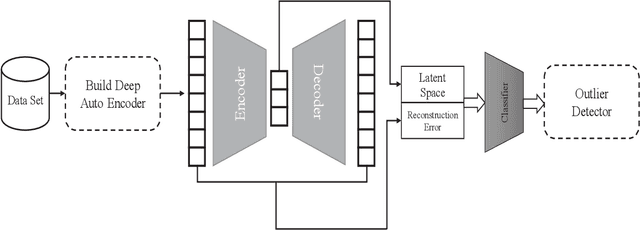


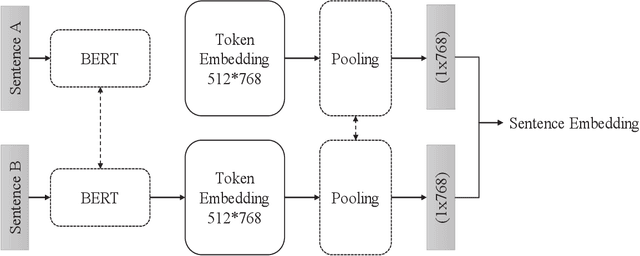
In this article, we propose using deep learning and transformer architectures combined with classical machine learning algorithms to detect and identify text anomalies in texts. Deep learning model provides a very crucial context information about the textual data which all textual context are converted to a numerical representation. We used multiple machine learning methods such as Sentence Transformers, Auto Encoders, Logistic Regression and Distance calculation methods to predict anomalies. The method are tested on the texts data and we used syntactic data from different source injected into the original text as anomalies or use them as target. Different methods and algorithm are explained in the field of outlier detection and the results of the best technique is presented. These results suggest that our algorithm could potentially reduce false positive rates compared with other anomaly detection methods that we are testing.
The effects of data size on Automated Essay Scoring engines
Aug 30, 2021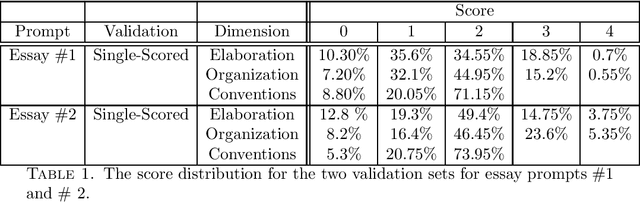
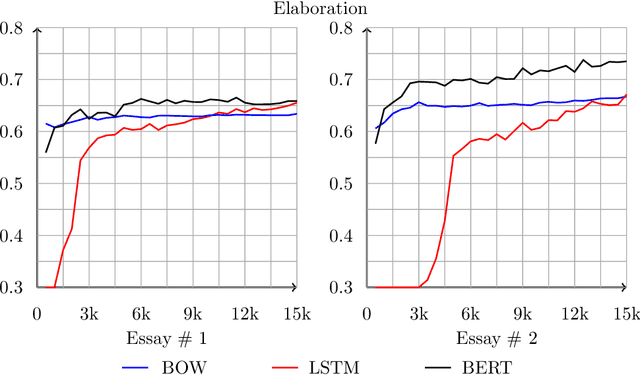
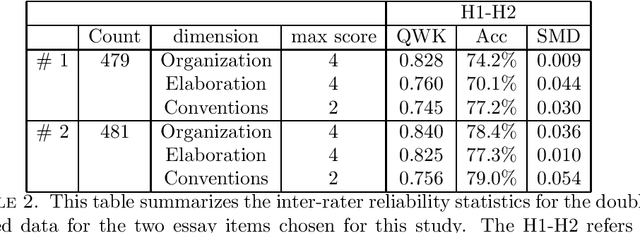
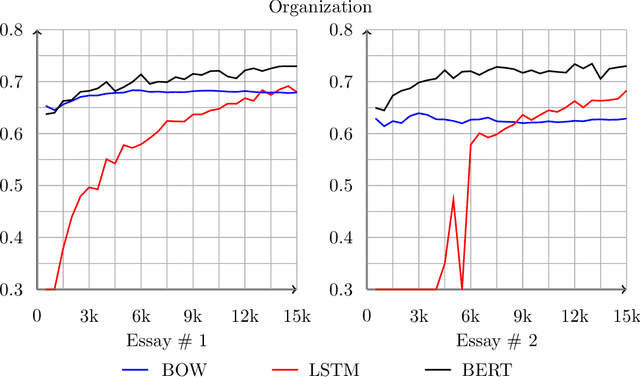
We study the effects of data size and quality on the performance on Automated Essay Scoring (AES) engines that are designed in accordance with three different paradigms; A frequency and hand-crafted feature-based model, a recurrent neural network model, and a pretrained transformer-based language model that is fine-tuned for classification. We expect that each type of model benefits from the size and the quality of the training data in very different ways. Standard practices for developing training data for AES engines were established with feature-based methods in mind, however, since neural networks are increasingly being considered in a production setting, this work seeks to inform us as to how to establish better training data for neural networks that will be used in production.
Automated essay scoring using efficient transformer-based language models
Feb 25, 2021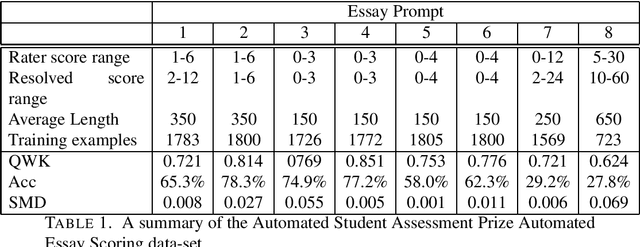
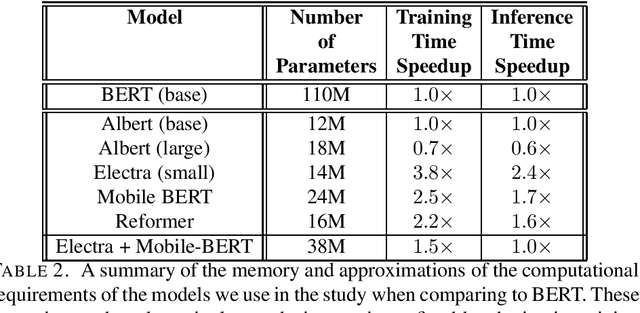
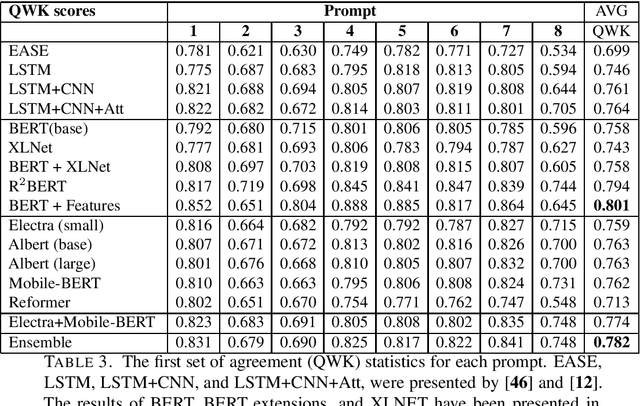
Automated Essay Scoring (AES) is a cross-disciplinary effort involving Education, Linguistics, and Natural Language Processing (NLP). The efficacy of an NLP model in AES tests it ability to evaluate long-term dependencies and extrapolate meaning even when text is poorly written. Large pretrained transformer-based language models have dominated the current state-of-the-art in many NLP tasks, however, the computational requirements of these models make them expensive to deploy in practice. The goal of this paper is to challenge the paradigm in NLP that bigger is better when it comes to AES. To do this, we evaluate the performance of several fine-tuned pretrained NLP models with a modest number of parameters on an AES dataset. By ensembling our models, we achieve excellent results with fewer parameters than most pretrained transformer-based models.
Language models and Automated Essay Scoring
Sep 18, 2019
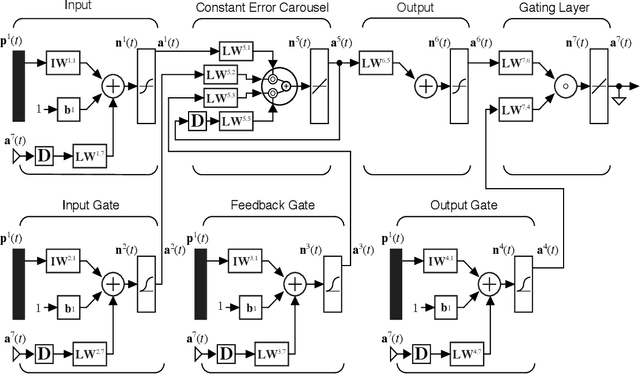
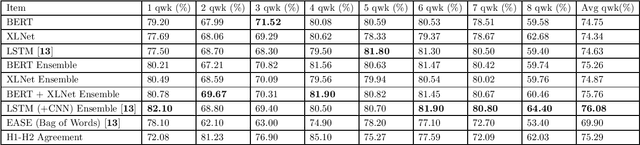
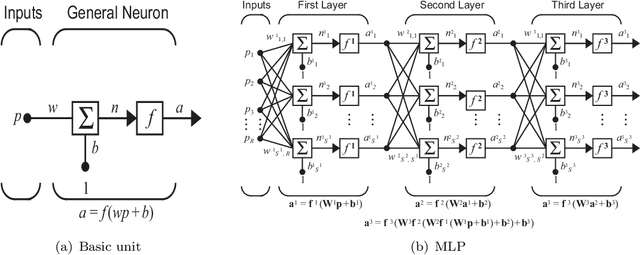
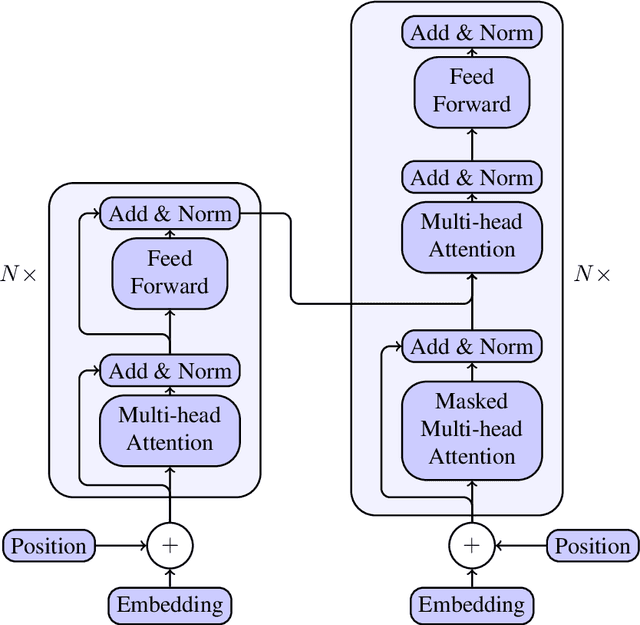
In this paper, we present a new comparative study on automatic essay scoring (AES). The current state-of-the-art natural language processing (NLP) neural network architectures are used in this work to achieve above human-level accuracy on the publicly available Kaggle AES dataset. We compare two powerful language models, BERT and XLNet, and describe all the layers and network architectures in these models. We elucidate the network architectures of BERT and XLNet using clear notation and diagrams and explain the advantages of transformer architectures over traditional recurrent neural network architectures. Linear algebra notation is used to clarify the functions of transformers and attention mechanisms. We compare the results with more traditional methods, such as bag of words (BOW) and long short term memory (LSTM) networks.