 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Rise of Artificial Intelligence in Educational Measurement: Opportunities and Ethical Challenges
Jun 27, 2024
The integration of artificial intelligence (AI) in educational measurement has revolutionized assessment methods, enabling automated scoring, rapid content analysis, and personalized feedback through machine learning and natural language processing. These advancements provide timely, consistent feedback and valuable insights into student performance, thereby enhancing the assessment experience. However, the deployment of AI in education also raises significant ethical concerns regarding validity, reliability, transparency, fairness, and equity. Issues such as algorithmic bias and the opacity of AI decision-making processes pose risks of perpetuating inequalities and affecting assessment outcomes. Responding to these concerns, various stakeholders, including educators, policymakers, and organizations, have developed guidelines to ensure ethical AI use in education. The National Council of Measurement in Education's Special Interest Group on AI in Measurement and Education (AIME) also focuses on establishing ethical standards and advancing research in this area. In this paper, a diverse group of AIME members examines the ethical implications of AI-powered tools in educational measurement, explores significant challenges such as automation bias and environmental impact, and proposes solutions to ensure AI's responsible and effective use in education.
Using Language Models to Detect Alarming Student Responses
May 12, 2023

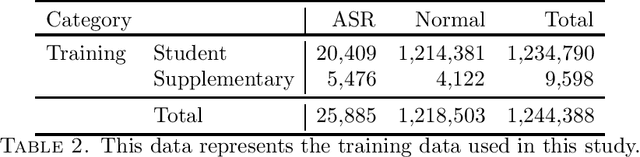

This article details the advances made to a system that uses artificial intelligence to identify alarming student responses. This system is built into our assessment platform to assess whether a student's response indicates they are a threat to themselves or others. Such responses may include details concerning threats of violence, severe depression, suicide risks, and descriptions of abuse. Driven by advances in natural language processing, the latest model is a fine-tuned language model trained on a large corpus consisting of student responses and supplementary texts. We demonstrate that the use of a language model delivers a substantial improvement in accuracy over the previous iterations of this system.
Language models and Automated Essay Scoring
Sep 18, 2019
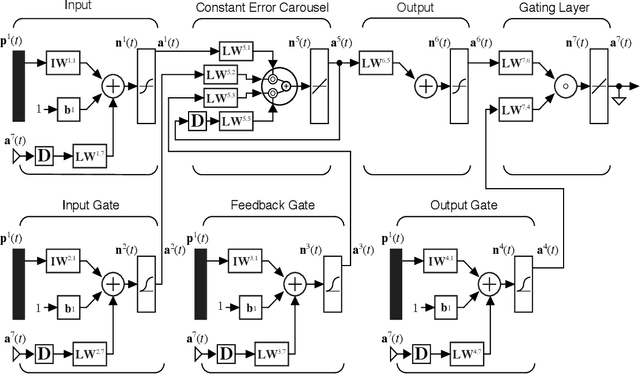
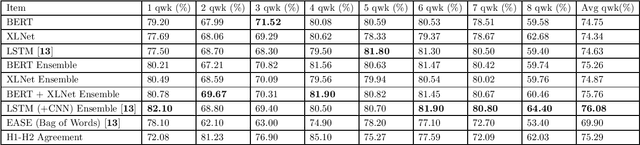
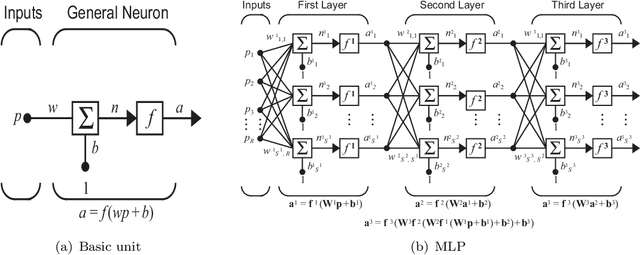
In this paper, we present a new comparative study on automatic essay scoring (AES). The current state-of-the-art natural language processing (NLP) neural network architectures are used in this work to achieve above human-level accuracy on the publicly available Kaggle AES dataset. We compare two powerful language models, BERT and XLNet, and describe all the layers and network architectures in these models. We elucidate the network architectures of BERT and XLNet using clear notation and diagrams and explain the advantages of transformer architectures over traditional recurrent neural network architectures. Linear algebra notation is used to clarify the functions of transformers and attention mechanisms. We compare the results with more traditional methods, such as bag of words (BOW) and long short term memory (LSTM) networks.
Neural network approach to classifying alarming student responses to online assessment
Sep 20, 2018



Automated scoring engines are increasingly being used to score the free-form text responses that students give to questions. Such engines are not designed to appropriately deal with responses that a human reader would find alarming such as those that indicate an intention to self-harm or harm others, responses that allude to drug abuse or sexual abuse or any response that would elicit concern for the student writing the response. Our neural network models have been designed to help identify these anomalous responses from a large collection of typical responses that students give. The responses identified by the neural network can be assessed for urgency, severity, and validity more quickly by a team of reviewers than otherwise possible. Given the anomalous nature of these types of responses, our goal is to maximize the chance of flagging these responses for review given the constraint that only a fixed percentage of responses can viably be assessed by a team of reviewers.