 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLanguage models and Automated Essay Scoring
Sep 18, 2019
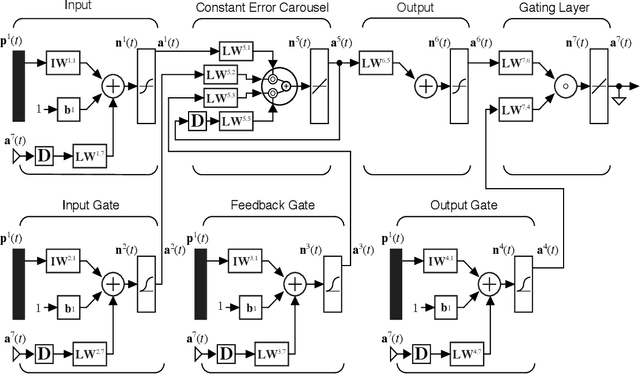
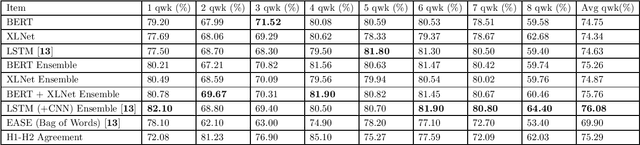
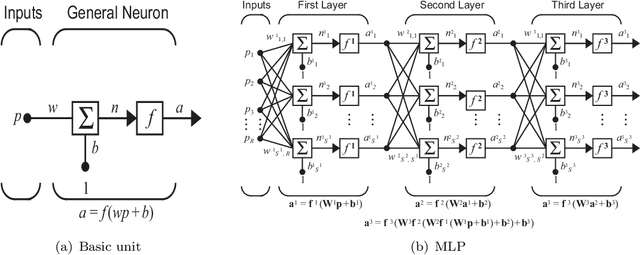
In this paper, we present a new comparative study on automatic essay scoring (AES). The current state-of-the-art natural language processing (NLP) neural network architectures are used in this work to achieve above human-level accuracy on the publicly available Kaggle AES dataset. We compare two powerful language models, BERT and XLNet, and describe all the layers and network architectures in these models. We elucidate the network architectures of BERT and XLNet using clear notation and diagrams and explain the advantages of transformer architectures over traditional recurrent neural network architectures. Linear algebra notation is used to clarify the functions of transformers and attention mechanisms. We compare the results with more traditional methods, such as bag of words (BOW) and long short term memory (LSTM) networks.