 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEditEmoTalk: Controllable Speech-Driven 3D Facial Animation with Continuous Expression Editing
Jan 15, 2026Speech-driven 3D facial animation aims to generate realistic and expressive facial motions directly from audio. While recent methods achieve high-quality lip synchronization, they often rely on discrete emotion categories, limiting continuous and fine-grained emotional control. We present EditEmoTalk, a controllable speech-driven 3D facial animation framework with continuous emotion editing. The key idea is a boundary-aware semantic embedding that learns the normal directions of inter-emotion decision boundaries, enabling a continuous expression manifold for smooth emotion manipulation. Moreover, we introduce an emotional consistency loss that enforces semantic alignment between the generated motion dynamics and the target emotion embedding through a mapping network, ensuring faithful emotional expression. Extensive experiments demonstrate that EditEmoTalk achieves superior controllability, expressiveness, and generalization while maintaining accurate lip synchronization. Code and pretrained models will be released.
Empirical Comparison of Encoder-Based Language Models and Feature-Based Supervised Machine Learning Approaches to Automated Scoring of Long Essays
Jan 07, 2026Long context may impose challenges for encoder-only language models in text processing, specifically for automated scoring of essays. This study trained several commonly used encoder-based language models for automated scoring of long essays. The performance of these trained models was evaluated and compared with the ensemble models built upon the base language models with a token limit of 512?. The experimented models include BERT-based models (BERT, RoBERTa, DistilBERT, and DeBERTa), ensemble models integrating embeddings from multiple encoder models, and ensemble models of feature-based supervised machine learning models, including Gradient-Boosted Decision Trees, eXtreme Gradient Boosting, and Light Gradient Boosting Machine. We trained, validated, and tested each model on a dataset of 17,307 essays, with an 80%/10%/10% split, and evaluated model performance using Quadratic Weighted Kappa. This study revealed that an ensemble-of-embeddings model that combines multiple pre-trained language model representations with gradient-boosting classifier as the ensemble model significantly outperforms individual language models at scoring long essays.
Uncertainty-Gated Deformable Network for Breast Tumor Segmentation in MR Images
Sep 19, 2025



Accurate segmentation of breast tumors in magnetic resonance images (MRI) is essential for breast cancer diagnosis, yet existing methods face challenges in capturing irregular tumor shapes and effectively integrating local and global features. To address these limitations, we propose an uncertainty-gated deformable network to leverage the complementary information from CNN and Transformers. Specifically, we incorporates deformable feature modeling into both convolution and attention modules, enabling adaptive receptive fields for irregular tumor contours. We also design an Uncertainty-Gated Enhancing Module (U-GEM) to selectively exchange complementary features between CNN and Transformer based on pixel-wise uncertainty, enhancing both local and global representations. Additionally, a Boundary-sensitive Deep Supervision Loss is introduced to further improve tumor boundary delineation. Comprehensive experiments on two clinical breast MRI datasets demonstrate that our method achieves superior segmentation performance compared with state-of-the-art methods, highlighting its clinical potential for accurate breast tumor delineation.
MotionFlux: Efficient Text-Guided Motion Generation through Rectified Flow Matching and Preference Alignment
Aug 27, 2025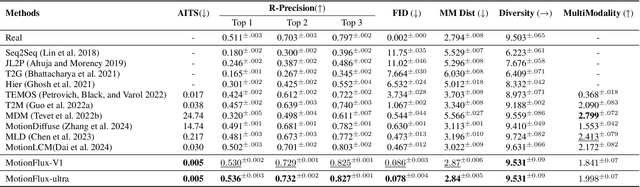
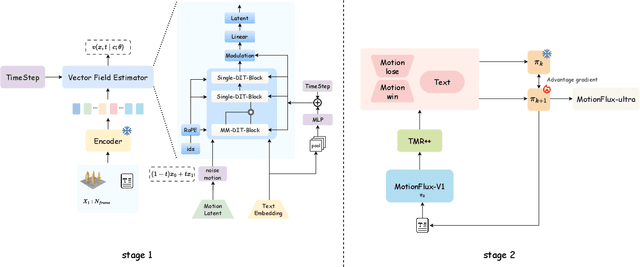
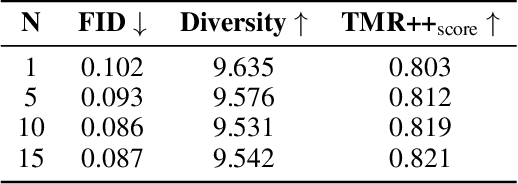
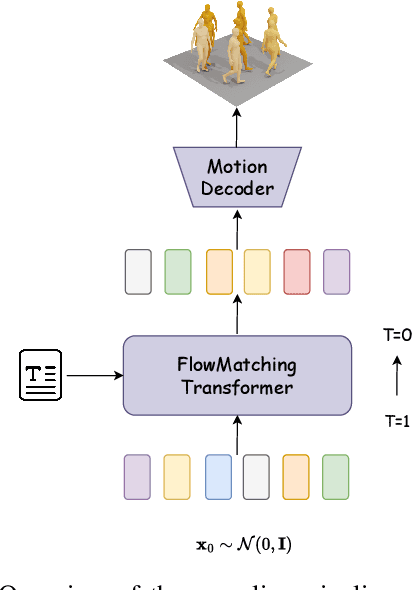
Motion generation is essential for animating virtual characters and embodied agents. While recent text-driven methods have made significant strides, they often struggle with achieving precise alignment between linguistic descriptions and motion semantics, as well as with the inefficiencies of slow, multi-step inference. To address these issues, we introduce TMR++ Aligned Preference Optimization (TAPO), an innovative framework that aligns subtle motion variations with textual modifiers and incorporates iterative adjustments to reinforce semantic grounding. To further enable real-time synthesis, we propose MotionFLUX, a high-speed generation framework based on deterministic rectified flow matching. Unlike traditional diffusion models, which require hundreds of denoising steps, MotionFLUX constructs optimal transport paths between noise distributions and motion spaces, facilitating real-time synthesis. The linearized probability paths reduce the need for multi-step sampling typical of sequential methods, significantly accelerating inference time without sacrificing motion quality. Experimental results demonstrate that, together, TAPO and MotionFLUX form a unified system that outperforms state-of-the-art approaches in both semantic consistency and motion quality, while also accelerating generation speed. The code and pretrained models will be released.
Comparing Human and AI Rater Effects Using the Many-Facet Rasch Model
May 28, 2025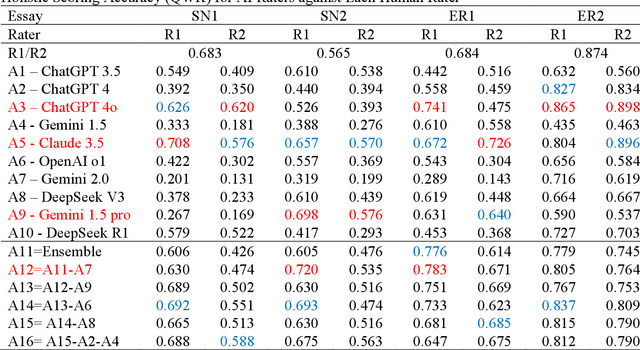



Large language models (LLMs) have been widely explored for automated scoring in low-stakes assessment to facilitate learning and instruction. Empirical evidence related to which LLM produces the most reliable scores and induces least rater effects needs to be collected before the use of LLMs for automated scoring in practice. This study compared ten LLMs (ChatGPT 3.5, ChatGPT 4, ChatGPT 4o, OpenAI o1, Claude 3.5 Sonnet, Gemini 1.5, Gemini 1.5 Pro, Gemini 2.0, as well as DeepSeek V3, and DeepSeek R1) with human expert raters in scoring two types of writing tasks. The accuracy of the holistic and analytic scores from LLMs compared with human raters was evaluated in terms of Quadratic Weighted Kappa. Intra-rater consistency across prompts was compared in terms of Cronbach Alpha. Rater effects of LLMs were evaluated and compared with human raters using the Many-Facet Rasch model. The results in general supported the use of ChatGPT 4o, Gemini 1.5 Pro, and Claude 3.5 Sonnet with high scoring accuracy, better rater reliability, and less rater effects.
Investigating AI Rater Effects of Large Language Models: GPT, Claude, Gemini, and DeepSeek
May 24, 2025Large language models (LLMs) have been widely explored for automated scoring in low-stakes assessment to facilitate learning and instruction. Empirical evidence related to which LLM produces the most reliable scores and induces least rater effects needs to be collected before the use of LLMs for automated scoring in practice. This study compared ten LLMs (ChatGPT 3.5, ChatGPT 4, ChatGPT 4o, OpenAI o1, Claude 3.5 Sonnet, Gemini 1.5, Gemini 1.5 Pro, Gemini 2.0, as well as DeepSeek V3, and DeepSeek R1) with human expert raters in scoring two types of writing tasks. The accuracy of the holistic and analytic scores from LLMs compared with human raters was evaluated in terms of Quadratic Weighted Kappa. Intra-rater consistency across prompts was compared in terms of Cronbach Alpha. Rater effects of LLMs were evaluated and compared with human raters using the Many-Facet Rasch model. The results in general supported the use of ChatGPT 4o, Gemini 1.5 Pro, and Claude 3.5 Sonnet with high scoring accuracy, better rater reliability, and less rater effects.
Domain Adaptation from Generated Multi-Weather Images for Unsupervised Maritime Object Classification
Jan 26, 2025



The classification and recognition of maritime objects are crucial for enhancing maritime safety, monitoring, and intelligent sea environment prediction. However, existing unsupervised methods for maritime object classification often struggle with the long-tail data distributions in both object categories and weather conditions. In this paper, we construct a dataset named AIMO produced by large-scale generative models with diverse weather conditions and balanced object categories, and collect a dataset named RMO with real-world images where long-tail issue exists. We propose a novel domain adaptation approach that leverages AIMO (source domain) to address the problem of limited labeled data, unbalanced distribution and domain shift in RMO (target domain), and enhance the generalization of source features with the Vision-Language Models such as CLIP. Experimental results shows that the proposed method significantly improves the classification accuracy, particularly for samples within rare object categories and weather conditions. Datasets and codes will be publicly available at https://github.com/honoria0204/AIMO.
Towards Deconfounded Image-Text Matching with Causal Inference
Aug 22, 2024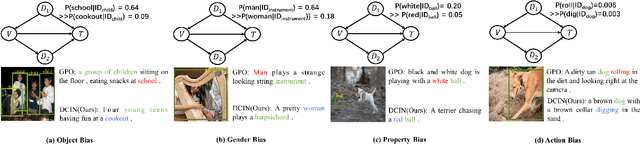
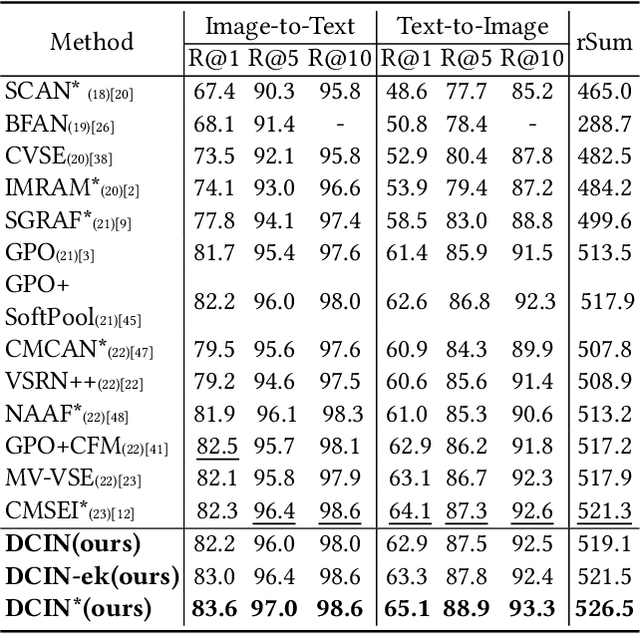
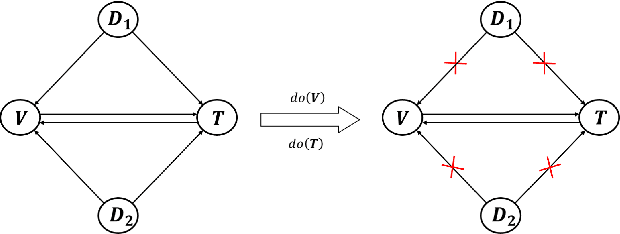
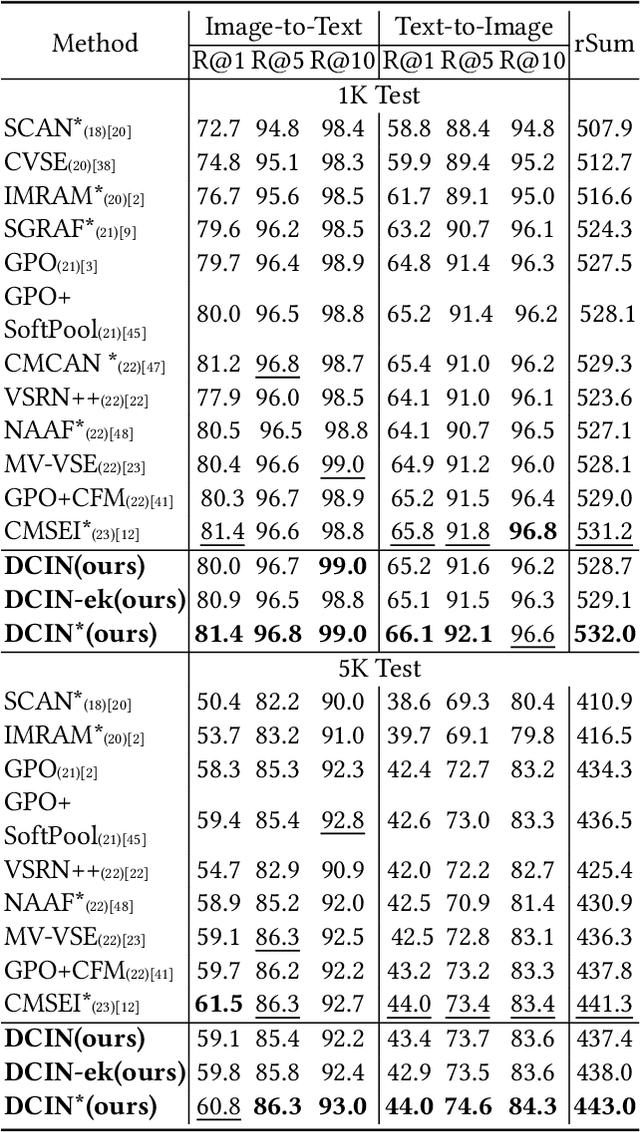
Prior image-text matching methods have shown remarkable performance on many benchmark datasets, but most of them overlook the bias in the dataset, which exists in intra-modal and inter-modal, and tend to learn the spurious correlations that extremely degrade the generalization ability of the model. Furthermore, these methods often incorporate biased external knowledge from large-scale datasets as prior knowledge into image-text matching model, which is inevitable to force model further learn biased associations. To address above limitations, this paper firstly utilizes Structural Causal Models (SCMs) to illustrate how intra- and inter-modal confounders damage the image-text matching. Then, we employ backdoor adjustment to propose an innovative Deconfounded Causal Inference Network (DCIN) for image-text matching task. DCIN (1) decomposes the intra- and inter-modal confounders and incorporates them into the encoding stage of visual and textual features, effectively eliminating the spurious correlations during image-text matching, and (2) uses causal inference to mitigate biases of external knowledge. Consequently, the model can learn causality instead of spurious correlations caused by dataset bias. Extensive experiments on two well-known benchmark datasets, i.e., Flickr30K and MSCOCO, demonstrate the superiority of our proposed method.
* ACM MM
BooW-VTON: Boosting In-the-Wild Virtual Try-On via Mask-Free Pseudo Data Training
Aug 12, 2024

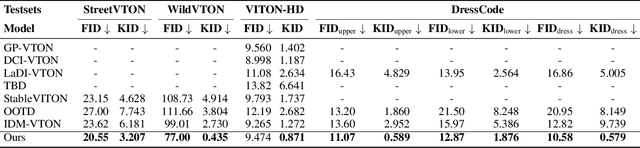
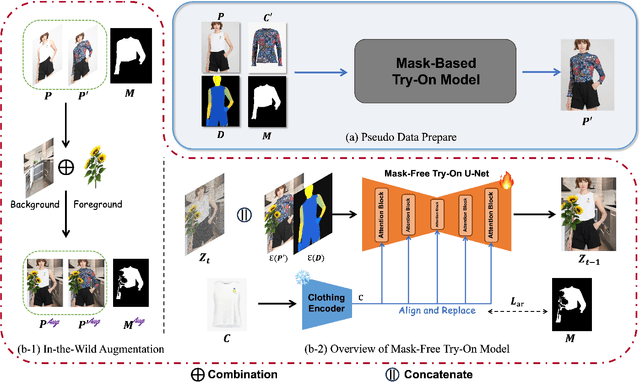
Image-based virtual try-on is an increasingly popular and important task to generate realistic try-on images of specific person. Existing methods always employ an accurate mask to remove the original garment in the source image, thus achieving realistic synthesized images in simple and conventional try-on scenarios based on powerful diffusion model. Therefore, acquiring suitable mask is vital to the try-on performance of these methods. However, obtaining precise inpainting masks, especially for complex wild try-on data containing diverse foreground occlusions and person poses, is not easy as Figure 1-Top shows. This difficulty often results in poor performance in more practical and challenging real-life scenarios, such as the selfie scene shown in Figure 1-Bottom. To this end, we propose a novel training paradigm combined with an efficient data augmentation method to acquire large-scale unpaired training data from wild scenarios, thereby significantly facilitating the try-on performance of our model without the need for additional inpainting masks. Besides, a try-on localization loss is designed to localize a more accurate try-on area to obtain more reasonable try-on results. It is noted that our method only needs the reference cloth image, source pose image and source person image as input, which is more cost-effective and user-friendly compared to existing methods. Extensive qualitative and quantitative experiments have demonstrated superior performance in wild scenarios with such a low-demand input.
The Rise of Artificial Intelligence in Educational Measurement: Opportunities and Ethical Challenges
Jun 27, 2024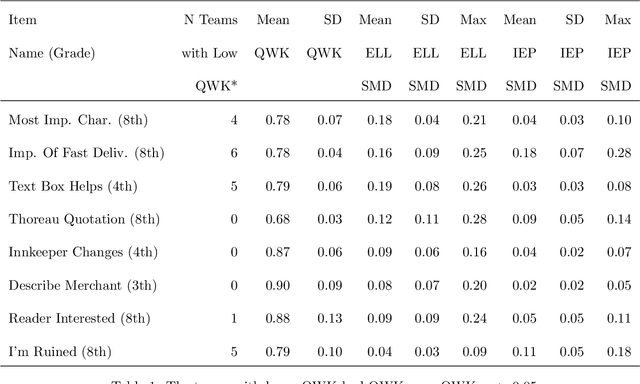
The integration of artificial intelligence (AI) in educational measurement has revolutionized assessment methods, enabling automated scoring, rapid content analysis, and personalized feedback through machine learning and natural language processing. These advancements provide timely, consistent feedback and valuable insights into student performance, thereby enhancing the assessment experience. However, the deployment of AI in education also raises significant ethical concerns regarding validity, reliability, transparency, fairness, and equity. Issues such as algorithmic bias and the opacity of AI decision-making processes pose risks of perpetuating inequalities and affecting assessment outcomes. Responding to these concerns, various stakeholders, including educators, policymakers, and organizations, have developed guidelines to ensure ethical AI use in education. The National Council of Measurement in Education's Special Interest Group on AI in Measurement and Education (AIME) also focuses on establishing ethical standards and advancing research in this area. In this paper, a diverse group of AIME members examines the ethical implications of AI-powered tools in educational measurement, explores significant challenges such as automation bias and environmental impact, and proposes solutions to ensure AI's responsible and effective use in education.