 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRule-driven News Captioning
Mar 14, 2024News captioning task aims to generate sentences by describing named entities or concrete events for an image with its news article. Existing methods have achieved remarkable results by relying on the large-scale pre-trained models, which primarily focus on the correlations between the input news content and the output predictions. However, the news captioning requires adhering to some fundamental rules of news reporting, such as accurately describing the individuals and actions associated with the event. In this paper, we propose the rule-driven news captioning method, which can generate image descriptions following designated rule signal. Specifically, we first design the news-aware semantic rule for the descriptions. This rule incorporates the primary action depicted in the image (e.g., "performing") and the roles played by named entities involved in the action (e.g., "Agent" and "Place"). Second, we inject this semantic rule into the large-scale pre-trained model, BART, with the prefix-tuning strategy, where multiple encoder layers are embedded with news-aware semantic rule. Finally, we can effectively guide BART to generate news sentences that comply with the designated rule. Extensive experiments on two widely used datasets (i.e., GoodNews and NYTimes800k) demonstrate the effectiveness of our method.
How to Understand Named Entities: Using Common Sense for News Captioning
Mar 11, 2024



News captioning aims to describe an image with its news article body as input. It greatly relies on a set of detected named entities, including real-world people, organizations, and places. This paper exploits commonsense knowledge to understand named entities for news captioning. By ``understand'', we mean correlating the news content with common sense in the wild, which helps an agent to 1) distinguish semantically similar named entities and 2) describe named entities using words outside of training corpora. Our approach consists of three modules: (a) Filter Module aims to clarify the common sense concerning a named entity from two aspects: what does it mean? and what is it related to?, which divide the common sense into explanatory knowledge and relevant knowledge, respectively. (b) Distinguish Module aggregates explanatory knowledge from node-degree, dependency, and distinguish three aspects to distinguish semantically similar named entities. (c) Enrich Module attaches relevant knowledge to named entities to enrich the entity description by commonsense information (e.g., identity and social position). Finally, the probability distributions from both modules are integrated to generate the news captions. Extensive experiments on two challenging datasets (i.e., GoodNews and NYTimes) demonstrate the superiority of our method. Ablation studies and visualization further validate its effectiveness in understanding named entities.
CAT-DM: Controllable Accelerated Virtual Try-on with Diffusion Model
Nov 30, 2023Image-based virtual try-on enables users to virtually try on different garments by altering original clothes in their photographs. Generative Adversarial Networks (GANs) dominate the research field in image-based virtual try-on, but have not resolved problems such as unnatural deformation of garments and the blurry generation quality. Recently, diffusion models have emerged with surprising performance across various image generation tasks. While the generative quality of diffusion models is impressive, achieving controllability poses a significant challenge when applying it to virtual try-on tasks and multiple denoising iterations limit its potential for real-time applications. In this paper, we propose Controllable Accelerated virtual Try-on with Diffusion Model called CAT-DM. To enhance the controllability, a basic diffusion-based virtual try-on network is designed, which utilizes ControlNet to introduce additional control conditions and improves the feature extraction of garment images. In terms of acceleration, CAT-DM initiates a reverse denoising process with an implicit distribution generated by a pre-trained GAN-based model. Compared with previous try-on methods based on diffusion models, CAT-DM not only retains the pattern and texture details of the in-shop garment but also reduces the sampling steps without compromising generation quality. Extensive experiments demonstrate the superiority of CAT-DM against both GAN-based and diffusion-based methods in producing more realistic images and accurately reproducing garment patterns. Our code and models will be publicly released.
Causality is all you need
Nov 21, 2023
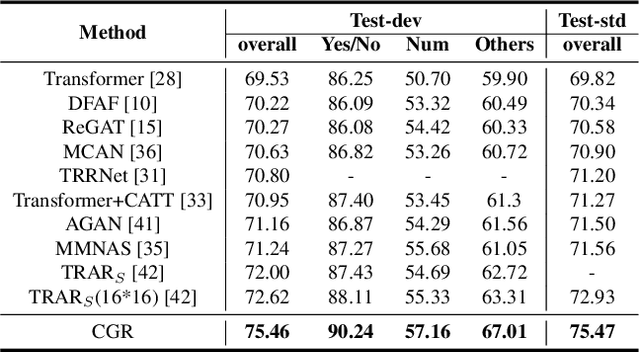
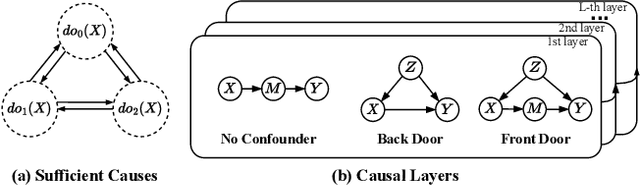
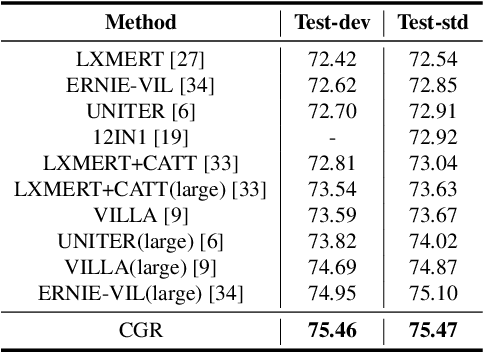
In the fundamental statistics course, students are taught to remember the well-known saying: "Correlation is not Causation". Till now, statistics (i.e., correlation) have developed various successful frameworks, such as Transformer and Pre-training large-scale models, which have stacked multiple parallel self-attention blocks to imitate a wide range of tasks. However, in the causation community, how to build an integrated causal framework still remains an untouched domain despite its excellent intervention capabilities. In this paper, we propose the Causal Graph Routing (CGR) framework, an integrated causal scheme relying entirely on the intervention mechanisms to reveal the cause-effect forces hidden in data. Specifically, CGR is composed of a stack of causal layers. Each layer includes a set of parallel deconfounding blocks from different causal graphs. We combine these blocks via the concept of the proposed sufficient cause, which allows the model to dynamically select the suitable deconfounding methods in each layer. CGR is implemented as the stacked networks, integrating no confounder, back-door adjustment, front-door adjustment, and probability of sufficient cause. We evaluate this framework on two classical tasks of CV and NLP. Experiments show CGR can surpass the current state-of-the-art methods on both Visual Question Answer and Long Document Classification tasks. In particular, CGR has great potential in building the "causal" pre-training large-scale model that effectively generalizes to diverse tasks. It will improve the machines' comprehension of causal relationships within a broader semantic space.