 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWUTDet: A 100K-Scale Ship Detection Dataset and Benchmarks with Dense Small Objects
Apr 09, 2026Ship detection for navigation is a fundamental perception task in intelligent waterway transportation systems. However, existing public ship detection datasets remain limited in terms of scale, the proportion of small-object instances, and scene diversity, which hinders the systematic evaluation and generalization study of detection algorithms in complex maritime environments. To this end, we construct WUTDet, a large-scale ship detection dataset. WUTDet contains 100,576 images and 381,378 annotated ship instances, covering diverse operational scenarios such as ports, anchorages, navigation, and berthing, as well as various imaging conditions including fog, glare, low-lightness, and rain, thereby exhibiting substantial diversity and challenge. Based on WUTDet, we systematically evaluate 20 baseline models from three mainstream detection architectures, namely CNN, Transformer, and Mamba. Experimental results show that the Transformer architecture achieves superior overall detection accuracy (AP) and small-object detection performance (APs), demonstrating stronger adaptability to complex maritime scenes; the CNN architecture maintains an advantage in inference efficiency, making it more suitable for real-time applications; and the Mamba architecture achieves a favorable balance between detection accuracy and computational efficiency. Furthermore, we construct a unified cross-dataset test set, Ship-GEN, to evaluate model generalization. Results on Ship-GEN show that models trained on WUTDet exhibit stronger generalization under different data distributions. These findings demonstrate that WUTDet provides effective data support for the research, evaluation, and generalization analysis of ship detection algorithms in complex maritime scenarios. The dataset is publicly available at: https://github.com/MAPGroup/WUTDet.
MotionFlux: Efficient Text-Guided Motion Generation through Rectified Flow Matching and Preference Alignment
Aug 27, 2025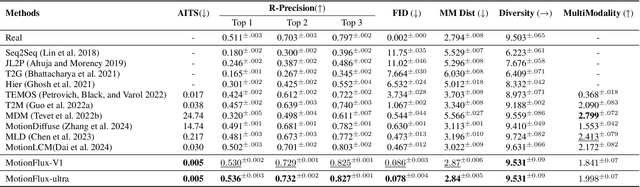
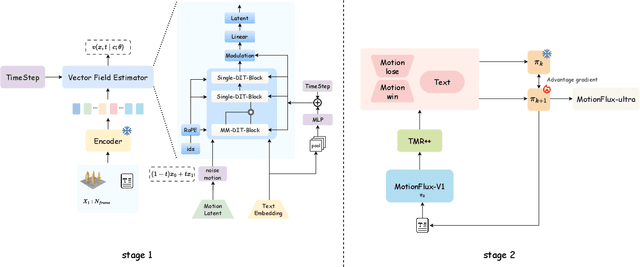
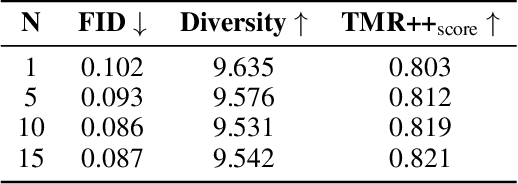
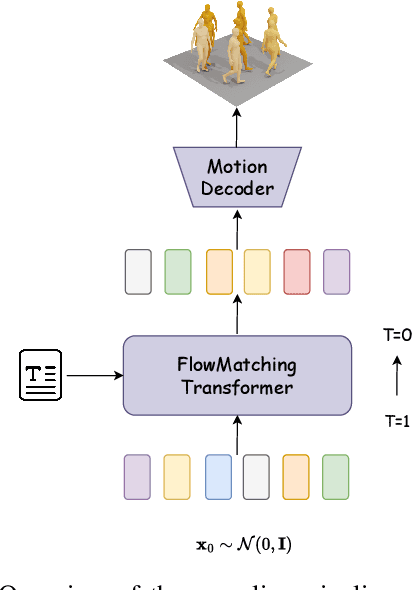
Motion generation is essential for animating virtual characters and embodied agents. While recent text-driven methods have made significant strides, they often struggle with achieving precise alignment between linguistic descriptions and motion semantics, as well as with the inefficiencies of slow, multi-step inference. To address these issues, we introduce TMR++ Aligned Preference Optimization (TAPO), an innovative framework that aligns subtle motion variations with textual modifiers and incorporates iterative adjustments to reinforce semantic grounding. To further enable real-time synthesis, we propose MotionFLUX, a high-speed generation framework based on deterministic rectified flow matching. Unlike traditional diffusion models, which require hundreds of denoising steps, MotionFLUX constructs optimal transport paths between noise distributions and motion spaces, facilitating real-time synthesis. The linearized probability paths reduce the need for multi-step sampling typical of sequential methods, significantly accelerating inference time without sacrificing motion quality. Experimental results demonstrate that, together, TAPO and MotionFLUX form a unified system that outperforms state-of-the-art approaches in both semantic consistency and motion quality, while also accelerating generation speed. The code and pretrained models will be released.
TRCE: Towards Reliable Malicious Concept Erasure in Text-to-Image Diffusion Models
Mar 10, 2025Recent advances in text-to-image diffusion models enable photorealistic image generation, but they also risk producing malicious content, such as NSFW images. To mitigate risk, concept erasure methods are studied to facilitate the model to unlearn specific concepts. However, current studies struggle to fully erase malicious concepts implicitly embedded in prompts (e.g., metaphorical expressions or adversarial prompts) while preserving the model's normal generation capability. To address this challenge, our study proposes TRCE, using a two-stage concept erasure strategy to achieve an effective trade-off between reliable erasure and knowledge preservation. Firstly, TRCE starts by erasing the malicious semantics implicitly embedded in textual prompts. By identifying a critical mapping objective(i.e., the [EoT] embedding), we optimize the cross-attention layers to map malicious prompts to contextually similar prompts but with safe concepts. This step prevents the model from being overly influenced by malicious semantics during the denoising process. Following this, considering the deterministic properties of the sampling trajectory of the diffusion model, TRCE further steers the early denoising prediction toward the safe direction and away from the unsafe one through contrastive learning, thus further avoiding the generation of malicious content. Finally, we conduct comprehensive evaluations of TRCE on multiple malicious concept erasure benchmarks, and the results demonstrate its effectiveness in erasing malicious concepts while better preserving the model's original generation ability. The code is available at: http://github.com/ddgoodgood/TRCE. CAUTION: This paper includes model-generated content that may contain offensive material.
Domain Adaptation from Generated Multi-Weather Images for Unsupervised Maritime Object Classification
Jan 26, 2025



The classification and recognition of maritime objects are crucial for enhancing maritime safety, monitoring, and intelligent sea environment prediction. However, existing unsupervised methods for maritime object classification often struggle with the long-tail data distributions in both object categories and weather conditions. In this paper, we construct a dataset named AIMO produced by large-scale generative models with diverse weather conditions and balanced object categories, and collect a dataset named RMO with real-world images where long-tail issue exists. We propose a novel domain adaptation approach that leverages AIMO (source domain) to address the problem of limited labeled data, unbalanced distribution and domain shift in RMO (target domain), and enhance the generalization of source features with the Vision-Language Models such as CLIP. Experimental results shows that the proposed method significantly improves the classification accuracy, particularly for samples within rare object categories and weather conditions. Datasets and codes will be publicly available at https://github.com/honoria0204/AIMO.
FSF-Net: Enhance 4D Occupancy Forecasting with Coarse BEV Scene Flow for Autonomous Driving
Sep 24, 2024



4D occupancy forecasting is one of the important techniques for autonomous driving, which can avoid potential risk in the complex traffic scenes. Scene flow is a crucial element to describe 4D occupancy map tendency. However, an accurate scene flow is difficult to predict in the real scene. In this paper, we find that BEV scene flow can approximately represent 3D scene flow in most traffic scenes. And coarse BEV scene flow is easy to generate. Under this thought, we propose 4D occupancy forecasting method FSF-Net based on coarse BEV scene flow. At first, we develop a general occupancy forecasting architecture based on coarse BEV scene flow. Then, to further enhance 4D occupancy feature representation ability, we propose a vector quantized based Mamba (VQ-Mamba) network to mine spatial-temporal structural scene feature. After that, to effectively fuse coarse occupancy maps forecasted from BEV scene flow and latent features, we design a U-Net based quality fusion (UQF) network to generate the fine-grained forecasting result. Extensive experiments are conducted on public Occ3D dataset. FSF-Net has achieved IoU and mIoU 9.56% and 10.87% higher than state-of-the-art method. Hence, we believe that proposed FSF-Net benefits to the safety of autonomous driving.
Towards Deconfounded Image-Text Matching with Causal Inference
Aug 22, 2024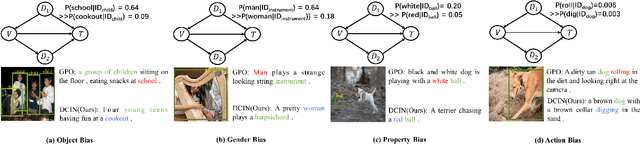
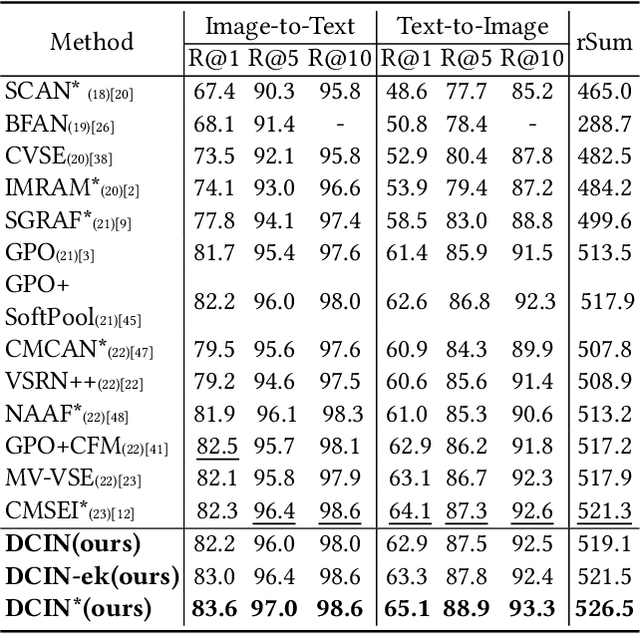
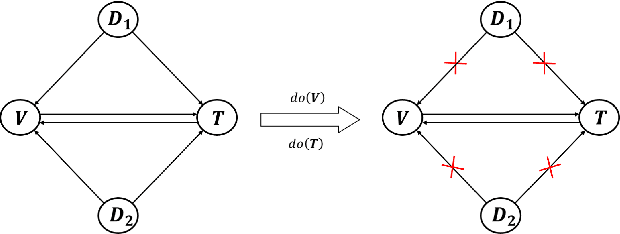
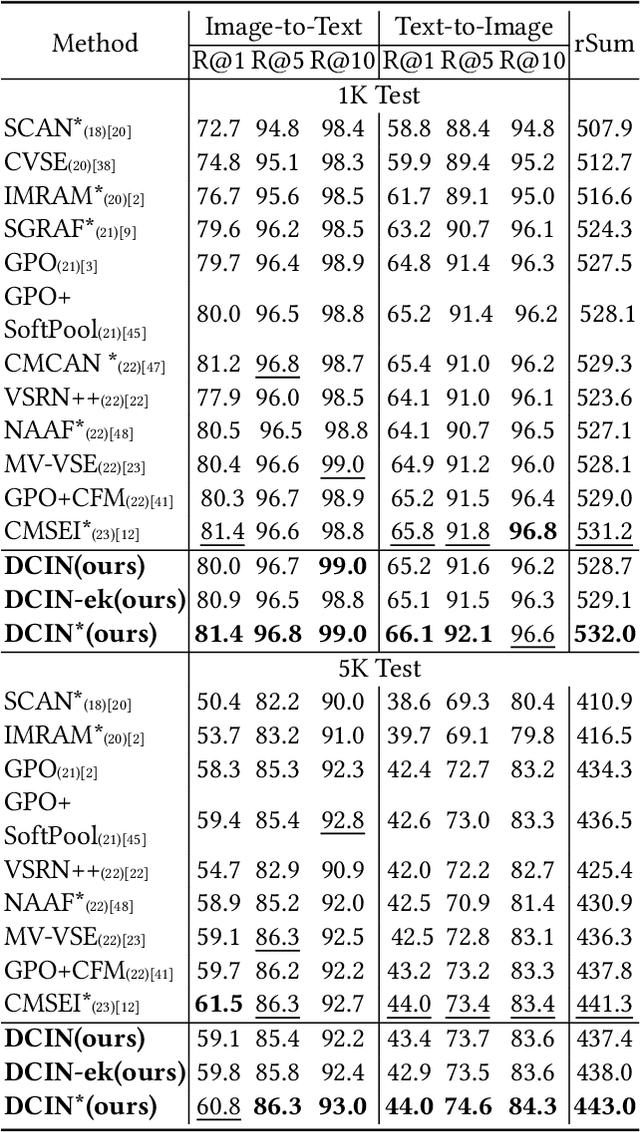
Prior image-text matching methods have shown remarkable performance on many benchmark datasets, but most of them overlook the bias in the dataset, which exists in intra-modal and inter-modal, and tend to learn the spurious correlations that extremely degrade the generalization ability of the model. Furthermore, these methods often incorporate biased external knowledge from large-scale datasets as prior knowledge into image-text matching model, which is inevitable to force model further learn biased associations. To address above limitations, this paper firstly utilizes Structural Causal Models (SCMs) to illustrate how intra- and inter-modal confounders damage the image-text matching. Then, we employ backdoor adjustment to propose an innovative Deconfounded Causal Inference Network (DCIN) for image-text matching task. DCIN (1) decomposes the intra- and inter-modal confounders and incorporates them into the encoding stage of visual and textual features, effectively eliminating the spurious correlations during image-text matching, and (2) uses causal inference to mitigate biases of external knowledge. Consequently, the model can learn causality instead of spurious correlations caused by dataset bias. Extensive experiments on two well-known benchmark datasets, i.e., Flickr30K and MSCOCO, demonstrate the superiority of our proposed method.
* ACM MM
A Training-Free Plug-and-Play Watermark Framework for Stable Diffusion
Apr 08, 2024



Nowadays, the family of Stable Diffusion (SD) models has gained prominence for its high quality outputs and scalability. This has also raised security concerns on social media, as malicious users can create and disseminate harmful content. Existing approaches involve training components or entire SDs to embed a watermark in generated images for traceability and responsibility attribution. However, in the era of AI-generated content (AIGC), the rapid iteration of SDs renders retraining with watermark models costly. To address this, we propose a training-free plug-and-play watermark framework for SDs. Without modifying any components of SDs, we embed diverse watermarks in the latent space, adapting to the denoising process. Our experimental findings reveal that our method effectively harmonizes image quality and watermark invisibility. Furthermore, it performs robustly under various attacks. We also have validated that our method is generalized to multiple versions of SDs, even without retraining the watermark model.
Rule-driven News Captioning
Mar 14, 2024News captioning task aims to generate sentences by describing named entities or concrete events for an image with its news article. Existing methods have achieved remarkable results by relying on the large-scale pre-trained models, which primarily focus on the correlations between the input news content and the output predictions. However, the news captioning requires adhering to some fundamental rules of news reporting, such as accurately describing the individuals and actions associated with the event. In this paper, we propose the rule-driven news captioning method, which can generate image descriptions following designated rule signal. Specifically, we first design the news-aware semantic rule for the descriptions. This rule incorporates the primary action depicted in the image (e.g., "performing") and the roles played by named entities involved in the action (e.g., "Agent" and "Place"). Second, we inject this semantic rule into the large-scale pre-trained model, BART, with the prefix-tuning strategy, where multiple encoder layers are embedded with news-aware semantic rule. Finally, we can effectively guide BART to generate news sentences that comply with the designated rule. Extensive experiments on two widely used datasets (i.e., GoodNews and NYTimes800k) demonstrate the effectiveness of our method.
How to Understand Named Entities: Using Common Sense for News Captioning
Mar 11, 2024



News captioning aims to describe an image with its news article body as input. It greatly relies on a set of detected named entities, including real-world people, organizations, and places. This paper exploits commonsense knowledge to understand named entities for news captioning. By ``understand'', we mean correlating the news content with common sense in the wild, which helps an agent to 1) distinguish semantically similar named entities and 2) describe named entities using words outside of training corpora. Our approach consists of three modules: (a) Filter Module aims to clarify the common sense concerning a named entity from two aspects: what does it mean? and what is it related to?, which divide the common sense into explanatory knowledge and relevant knowledge, respectively. (b) Distinguish Module aggregates explanatory knowledge from node-degree, dependency, and distinguish three aspects to distinguish semantically similar named entities. (c) Enrich Module attaches relevant knowledge to named entities to enrich the entity description by commonsense information (e.g., identity and social position). Finally, the probability distributions from both modules are integrated to generate the news captions. Extensive experiments on two challenging datasets (i.e., GoodNews and NYTimes) demonstrate the superiority of our method. Ablation studies and visualization further validate its effectiveness in understanding named entities.
Causality is all you need
Nov 21, 2023
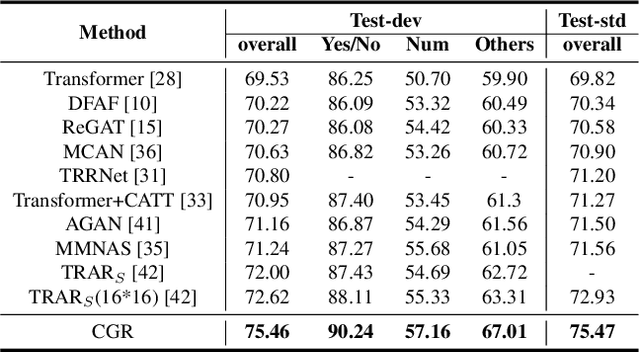
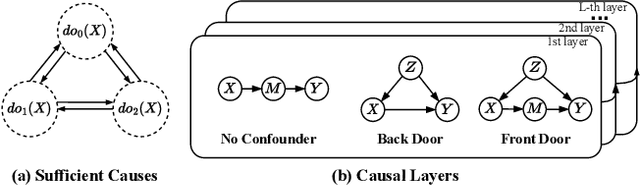
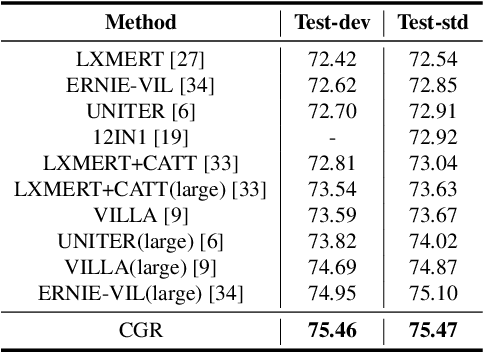
In the fundamental statistics course, students are taught to remember the well-known saying: "Correlation is not Causation". Till now, statistics (i.e., correlation) have developed various successful frameworks, such as Transformer and Pre-training large-scale models, which have stacked multiple parallel self-attention blocks to imitate a wide range of tasks. However, in the causation community, how to build an integrated causal framework still remains an untouched domain despite its excellent intervention capabilities. In this paper, we propose the Causal Graph Routing (CGR) framework, an integrated causal scheme relying entirely on the intervention mechanisms to reveal the cause-effect forces hidden in data. Specifically, CGR is composed of a stack of causal layers. Each layer includes a set of parallel deconfounding blocks from different causal graphs. We combine these blocks via the concept of the proposed sufficient cause, which allows the model to dynamically select the suitable deconfounding methods in each layer. CGR is implemented as the stacked networks, integrating no confounder, back-door adjustment, front-door adjustment, and probability of sufficient cause. We evaluate this framework on two classical tasks of CV and NLP. Experiments show CGR can surpass the current state-of-the-art methods on both Visual Question Answer and Long Document Classification tasks. In particular, CGR has great potential in building the "causal" pre-training large-scale model that effectively generalizes to diverse tasks. It will improve the machines' comprehension of causal relationships within a broader semantic space.