 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExtending Depth of Field for Varifocal Multiview Images
Sep 28, 2024Optical imaging systems are generally limited by the depth of field because of the nature of the optics. Therefore, extending depth of field (EDoF) is a fundamental task for meeting the requirements of emerging visual applications. To solve this task, the common practice is using multi-focus images from a single viewpoint. This method can obtain acceptable quality of EDoF under the condition of fixed field of view, but it is only applicable to static scenes and the field of view is limited and fixed. An emerging data type, varifocal multiview images have the potential to become a new paradigm for solving the EDoF, because the data contains more field of view information than multi-focus images. To realize EDoF of varifocal multiview images, we propose an end-to-end method for the EDoF, including image alignment, image optimization and image fusion. Experimental results demonstrate the efficiency of the proposed method.
FSF-Net: Enhance 4D Occupancy Forecasting with Coarse BEV Scene Flow for Autonomous Driving
Sep 24, 2024



4D occupancy forecasting is one of the important techniques for autonomous driving, which can avoid potential risk in the complex traffic scenes. Scene flow is a crucial element to describe 4D occupancy map tendency. However, an accurate scene flow is difficult to predict in the real scene. In this paper, we find that BEV scene flow can approximately represent 3D scene flow in most traffic scenes. And coarse BEV scene flow is easy to generate. Under this thought, we propose 4D occupancy forecasting method FSF-Net based on coarse BEV scene flow. At first, we develop a general occupancy forecasting architecture based on coarse BEV scene flow. Then, to further enhance 4D occupancy feature representation ability, we propose a vector quantized based Mamba (VQ-Mamba) network to mine spatial-temporal structural scene feature. After that, to effectively fuse coarse occupancy maps forecasted from BEV scene flow and latent features, we design a U-Net based quality fusion (UQF) network to generate the fine-grained forecasting result. Extensive experiments are conducted on public Occ3D dataset. FSF-Net has achieved IoU and mIoU 9.56% and 10.87% higher than state-of-the-art method. Hence, we believe that proposed FSF-Net benefits to the safety of autonomous driving.
Varifocal Multiview Images: Capturing and Visual Tasks
Nov 19, 2021
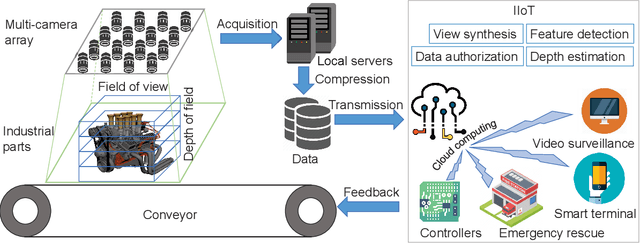


Multiview images have flexible field of view (FoV) but inflexible depth of field (DoF). To overcome the limitation of multiview images on visual tasks, in this paper, we present varifocal multiview (VFMV) images with flexible DoF. VFMV images are captured by focusing a scene on distinct depths by varying focal planes, and each view only focused on one single plane.Therefore, VFMV images contain more information in focal dimension than multiview images, and can provide a rich representation for 3D scene by considering both FoV and DoF. The characteristics of VFMV images are useful for visual tasks to achieve high quality scene representation. Two experiments are conducted to validate the advantages of VFMV images in 4D light field feature detection and 3D reconstruction. Experiment results show that VFMV images can detect more light field features and achieve higher reconstruction quality due to informative focus cues. This work demonstrates that VFMV images have definite advantages over multiview images in visual tasks.