 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSDGOCC: Semantic and Depth-Guided Bird's-Eye View Transformation for 3D Multimodal Occupancy Prediction
Jul 22, 2025Multimodal 3D occupancy prediction has garnered significant attention for its potential in autonomous driving. However, most existing approaches are single-modality: camera-based methods lack depth information, while LiDAR-based methods struggle with occlusions. Current lightweight methods primarily rely on the Lift-Splat-Shoot (LSS) pipeline, which suffers from inaccurate depth estimation and fails to fully exploit the geometric and semantic information of 3D LiDAR points. Therefore, we propose a novel multimodal occupancy prediction network called SDG-OCC, which incorporates a joint semantic and depth-guided view transformation coupled with a fusion-to-occupancy-driven active distillation. The enhanced view transformation constructs accurate depth distributions by integrating pixel semantics and co-point depth through diffusion and bilinear discretization. The fusion-to-occupancy-driven active distillation extracts rich semantic information from multimodal data and selectively transfers knowledge to image features based on LiDAR-identified regions. Finally, for optimal performance, we introduce SDG-Fusion, which uses fusion alone, and SDG-KL, which integrates both fusion and distillation for faster inference. Our method achieves state-of-the-art (SOTA) performance with real-time processing on the Occ3D-nuScenes dataset and shows comparable performance on the more challenging SurroundOcc-nuScenes dataset, demonstrating its effectiveness and robustness. The code will be released at https://github.com/DzpLab/SDGOCC.
Multimodal Point Cloud Semantic Segmentation With Virtual Point Enhancement
Apr 02, 2025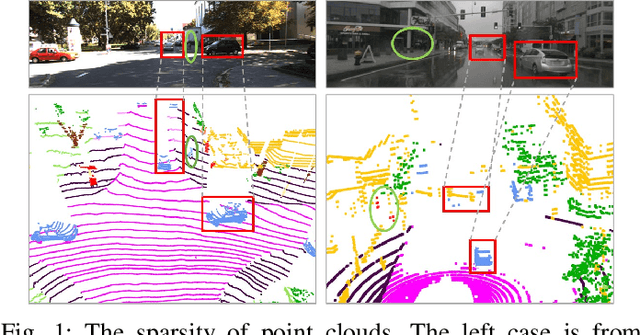
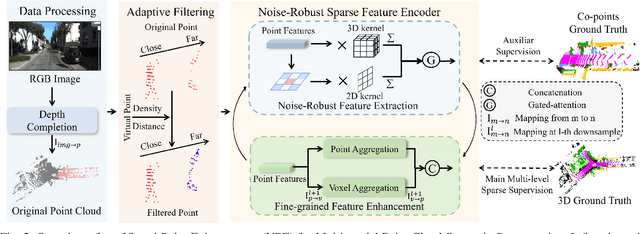

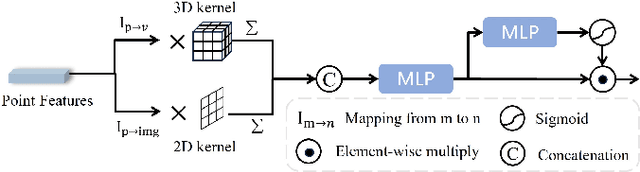
LiDAR-based 3D point cloud recognition has been proven beneficial in various applications. However, the sparsity and varying density pose a significant challenge in capturing intricate details of objects, particularly for medium-range and small targets. Therefore, we propose a multi-modal point cloud semantic segmentation method based on Virtual Point Enhancement (VPE), which integrates virtual points generated from images to address these issues. These virtual points are dense but noisy, and directly incorporating them can increase computational burden and degrade performance. Therefore, we introduce a spatial difference-driven adaptive filtering module that selectively extracts valuable pseudo points from these virtual points based on density and distance, enhancing the density of medium-range targets. Subsequently, we propose a noise-robust sparse feature encoder that incorporates noise-robust feature extraction and fine-grained feature enhancement. Noise-robust feature extraction exploits the 2D image space to reduce the impact of noisy points, while fine-grained feature enhancement boosts sparse geometric features through inner-voxel neighborhood point aggregation and downsampled voxel aggregation. The results on the SemanticKITTI and nuScenes, two large-scale benchmark data sets, have validated effectiveness, significantly improving 2.89\% mIoU with the introduction of 7.7\% virtual points on nuScenes.
Unlocking Generalization Power in LiDAR Point Cloud Registration
Mar 13, 2025



In real-world environments, a LiDAR point cloud registration method with robust generalization capabilities (across varying distances and datasets) is crucial for ensuring safety in autonomous driving and other LiDAR-based applications. However, current methods fall short in achieving this level of generalization. To address these limitations, we propose UGP, a pruned framework designed to enhance generalization power for LiDAR point cloud registration. The core insight in UGP is the elimination of cross-attention mechanisms to improve generalization, allowing the network to concentrate on intra-frame feature extraction. Additionally, we introduce a progressive self-attention module to reduce ambiguity in large-scale scenes and integrate Bird's Eye View (BEV) features to incorporate semantic information about scene elements. Together, these enhancements significantly boost the network's generalization performance. We validated our approach through various generalization experiments in multiple outdoor scenes. In cross-distance generalization experiments on KITTI and nuScenes, UGP achieved state-of-the-art mean Registration Recall rates of 94.5% and 91.4%, respectively. In cross-dataset generalization from nuScenes to KITTI, UGP achieved a state-of-the-art mean Registration Recall of 90.9%. Code will be available at https://github.com/peakpang/UGP.
Dual-Domain Homogeneous Fusion with Cross-Modal Mamba and Progressive Decoder for 3D Object Detection
Mar 12, 2025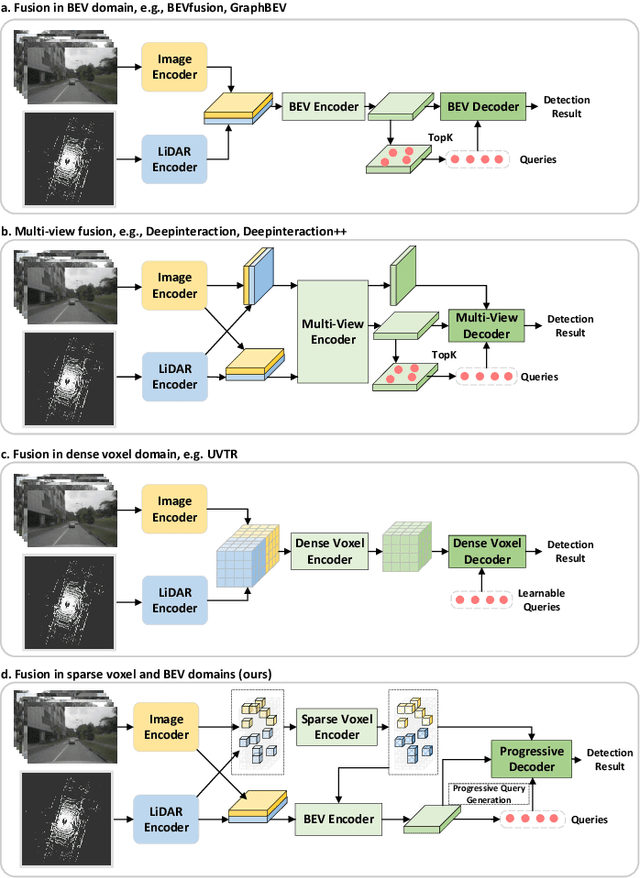
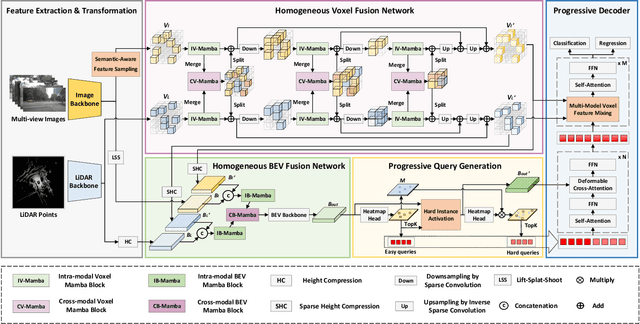
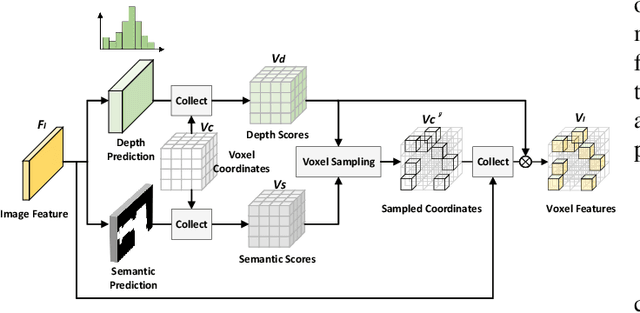
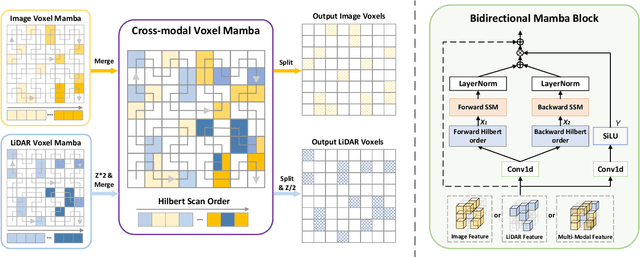
Fusing LiDAR point cloud features and image features in a homogeneous BEV space has been widely adopted for 3D object detection in autonomous driving. However, such methods are limited by the excessive compression of multi-modal features. While some works explore feature fusion in dense voxel spaces, they suffer from high computational costs and inefficiencies in query generation. To address these limitations, we propose a Dual-Domain Homogeneous Fusion network (DDHFusion), which leverages the complementary advantages of both BEV and voxel domains while mitigating their respective drawbacks. Specifically, we first transform image features into BEV and sparse voxel spaces using LSS and our proposed semantic-aware feature sampling module which can significantly reduces computational overhead by filtering unimportant voxels. For feature encoding, we design two networks for BEV and voxel feature fusion, incorporating novel cross-modal voxel and BEV Mamba blocks to resolve feature misalignment and enable efficient yet comprehensive scene perception. The output voxel features are injected into the BEV space to compensate for the loss of 3D details caused by height compression. For feature decoding, a progressive query generation module is implemented in the BEV domain to alleviate false negatives during query selection caused by feature compression and small object sizes. Finally, a progressive decoder can sequentially aggregate not only context-rich BEV features but also geometry-aware voxel features, ensuring more precise confidence prediction and bounding box regression. On the NuScenes dataset, DDHfusion achieves state-of-the-art performance, and further experiments demonstrate its superiority over other homogeneous fusion methods.
Deep Learning for 3D Point Cloud Enhancement: A Survey
Oct 30, 2024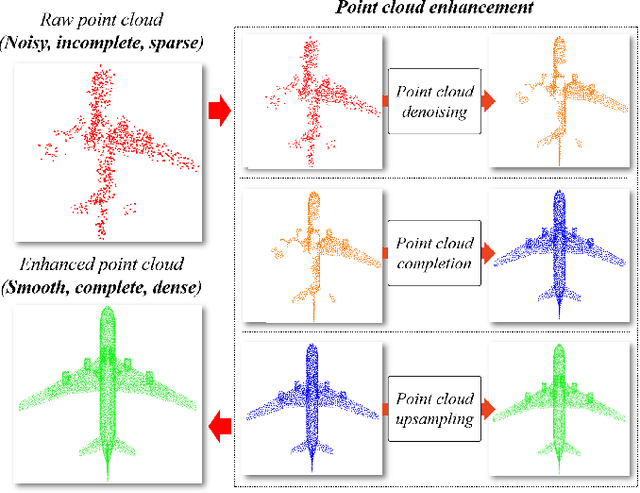

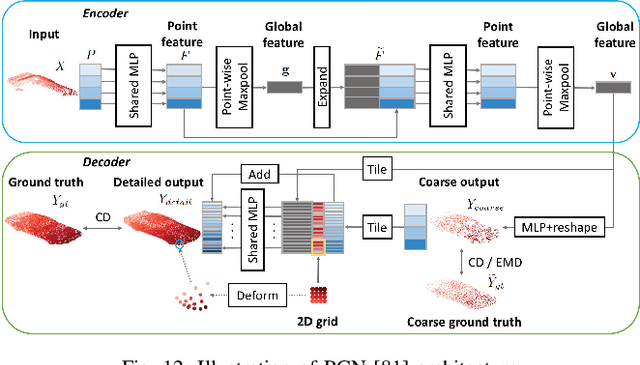
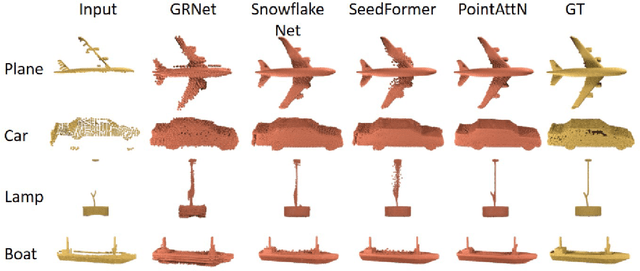
Point cloud data now are popular data representations in a number of three-dimensional (3D) vision research realms. However, due to the limited performance of sensors and sensing noise, the raw data usually suffer from sparsity, noise, and incompleteness. This poses great challenges to down-stream point cloud processing tasks. In recent years, deep-learning-based point cloud enhancement methods, which aim to achieve dense, clean, and complete point clouds from low-quality raw point clouds using deep neural networks, are gaining tremendous research attention. This paper, for the first time to our knowledge, presents a comprehensive survey for deep-learning-based point cloud enhancement methods. It covers three main perspectives for point cloud enhancement, i.e., (1) denoising to achieve clean data; (2) completion to recover unseen data; (3) upsampling to obtain dense data. Our survey presents a new taxonomy for recent state-of-the-art methods and systematic experimental results on standard benchmarks. In addition, we share our insightful observations, thoughts, and inspiring future research directions for point cloud enhancement with deep learning.
FSF-Net: Enhance 4D Occupancy Forecasting with Coarse BEV Scene Flow for Autonomous Driving
Sep 24, 2024



4D occupancy forecasting is one of the important techniques for autonomous driving, which can avoid potential risk in the complex traffic scenes. Scene flow is a crucial element to describe 4D occupancy map tendency. However, an accurate scene flow is difficult to predict in the real scene. In this paper, we find that BEV scene flow can approximately represent 3D scene flow in most traffic scenes. And coarse BEV scene flow is easy to generate. Under this thought, we propose 4D occupancy forecasting method FSF-Net based on coarse BEV scene flow. At first, we develop a general occupancy forecasting architecture based on coarse BEV scene flow. Then, to further enhance 4D occupancy feature representation ability, we propose a vector quantized based Mamba (VQ-Mamba) network to mine spatial-temporal structural scene feature. After that, to effectively fuse coarse occupancy maps forecasted from BEV scene flow and latent features, we design a U-Net based quality fusion (UQF) network to generate the fine-grained forecasting result. Extensive experiments are conducted on public Occ3D dataset. FSF-Net has achieved IoU and mIoU 9.56% and 10.87% higher than state-of-the-art method. Hence, we believe that proposed FSF-Net benefits to the safety of autonomous driving.
3D Single-object Tracking in Point Clouds with High Temporal Variation
Aug 04, 2024



The high temporal variation of the point clouds is the key challenge of 3D single-object tracking (3D SOT). Existing approaches rely on the assumption that the shape variation of the point clouds and the motion of the objects across neighboring frames are smooth, failing to cope with high temporal variation data. In this paper, we present a novel framework for 3D SOT in point clouds with high temporal variation, called HVTrack. HVTrack proposes three novel components to tackle the challenges in the high temporal variation scenario: 1) A Relative-Pose-Aware Memory module to handle temporal point cloud shape variations; 2) a Base-Expansion Feature Cross-Attention module to deal with similar object distractions in expanded search areas; 3) a Contextual Point Guided Self-Attention module for suppressing heavy background noise. We construct a dataset with high temporal variation (KITTI-HV) by setting different frame intervals for sampling in the KITTI dataset. On the KITTI-HV with 5 frame intervals, our HVTrack surpasses the state-of-the-art tracker CXTracker by 11.3%/15.7% in Success/Precision.