 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLER-YOLO: Reliability-Aware Expert Routing for Misaligned RGB-Infrared UAV Detection
May 20, 2026Detecting small unmanned aerial vehicles from RGB-infrared remote-sensing pairs remains challenging due to tiny target scale, cluttered backgrounds, and spatial misalignment between heterogeneous sensors. Existing bimodal detectors often align or fuse features without assessing the reliability of local cross-sensor correspondence, allowing mismatch artifacts to propagate into the detection head. To address this issue, we propose LER-YOLO, a reliability-aware sparse mixture-of-experts framework for misaligned RGB-infrared UAV detection. LER-YOLO first introduces an Uncertainty-Aware Target Alignment module that resamples visible features toward the infrared reference and estimates a spatial reliability map. This reliability prior is then used by a Reliability-Guided Sparse MoE Fusion module to adaptively select k experts from RGB-dominant, infrared-dominant, and interactive fusion experts, enabling trustworthy cross-modal interaction while suppressing unreliable fusion. Experiments on the public MBU benchmark under a YOLOv5s-family protocol show that LER-YOLO achieves 89.7+/-0.2% AP50 over three independent seeds, with a best result of 89.9%. Extensive ablations, parameter-matched comparisons, synthetic-shift evaluations, and complexity analysis demonstrate that the gains mainly come from reliability-guided expert routing rather than increased model capacity.
Rethink Efficiency Side of Neural Combinatorial Solver: An Offline and Self-Play Paradigm
Feb 24, 2026We propose ECO, a versatile learning paradigm that enables efficient offline self-play for Neural Combinatorial Optimization (NCO). ECO addresses key limitations in the field through: 1) Paradigm Shift: Moving beyond inefficient online paradigms, we introduce a two-phase offline paradigm consisting of supervised warm-up and iterative Direct Preference Optimization (DPO); 2) Architecture Shift: We deliberately design a Mamba-based architecture to further enhance the efficiency in the offline paradigm; and 3) Progressive Bootstrapping: To stabilize training, we employ a heuristic-based bootstrapping mechanism that ensures continuous policy improvement during training. Comparison results on TSP and CVRP highlight that ECO performs competitively with up-to-date baselines, with significant advantage on the efficiency side in terms of memory utilization and training throughput. We provide further in-depth analysis on the efficiency, throughput and memory usage of ECO. Ablation studies show rationale behind our designs.
Fluid Antenna Systems under Channel Uncertainty and Hardware Impairments: Trends, Challenges, and Future Research Directions
Jan 30, 2026Fluid antenna systems (FAS) have recently emerged as a promising paradigm for achieving spatially reconfigurable, compact, and energy-efficient wireless communications in beyond fifth-generation (B5G) and sixth-generation (6G) networks. By dynamically repositioning a liquid-based radiating element within a confined physical structure, FAS can exploit spatial diversity without relying on multiple fixed antenna elements. This spatial mobility provides a new degree of freedom for mitigating channel fading and interference, while maintaining low hardware complexity and power consumption. However, the performance of FAS in realistic deployments is strongly affected by channel uncertainty, hardware nonidealities, and mechanical constraints, all of which can substantially deviate from idealized analytical assumptions. This paper presents a comprehensive survey of the operation and design of FAS under such practical considerations. Key aspects include the characterization of spatio-temporal channel uncertainty, analysis of hardware and mechanical impairments such as RF nonlinearity, port coupling, and fluid response delay, as well as the exploration of robust design and learning-based control strategies to enhance system reliability. Finally, open research directions are identified, aiming to guide future developments toward robust, adaptive, and cross-domain FAS design for next-generation wireless networks.
Symphony: A Decentralized Multi-Agent Framework for Scalable Collective Intelligence
Aug 27, 2025Most existing Large Language Model (LLM)-based agent frameworks rely on centralized orchestration, incurring high deployment costs, rigid communication topologies, and limited adaptability. To address these challenges, we introduce Symphony, a decentralized multi-agent system which enables lightweight LLMs on consumer-grade GPUs to coordinate. Symphony introduces three key mechanisms: (1) a decentralized ledger that records capabilities, (2) a Beacon-selection protocol for dynamic task allocation, and (3) weighted result voting based on CoTs. This design forms a privacy-saving, scalable, and fault-tolerant orchestration with low overhead. Empirically, Symphony outperforms existing baselines on reasoning benchmarks, achieving substantial accuracy gains and demonstrating robustness across models of varying capacities.
Task-Specific Zero-shot Quantization-Aware Training for Object Detection
Jul 22, 2025Quantization is a key technique to reduce network size and computational complexity by representing the network parameters with a lower precision. Traditional quantization methods rely on access to original training data, which is often restricted due to privacy concerns or security challenges. Zero-shot Quantization (ZSQ) addresses this by using synthetic data generated from pre-trained models, eliminating the need for real training data. Recently, ZSQ has been extended to object detection. However, existing methods use unlabeled task-agnostic synthetic images that lack the specific information required for object detection, leading to suboptimal performance. In this paper, we propose a novel task-specific ZSQ framework for object detection networks, which consists of two main stages. First, we introduce a bounding box and category sampling strategy to synthesize a task-specific calibration set from the pre-trained network, reconstructing object locations, sizes, and category distributions without any prior knowledge. Second, we integrate task-specific training into the knowledge distillation process to restore the performance of quantized detection networks. Extensive experiments conducted on the MS-COCO and Pascal VOC datasets demonstrate the efficiency and state-of-the-art performance of our method. Our code is publicly available at: https://github.com/DFQ-Dojo/dfq-toolkit .
Resource Allocation for Pinching-Antenna Systems: State-of-the-Art, Key Techniques and Open Issues
Jun 06, 2025Pinching antennas have emerged as a promising technology for reconfiguring wireless propagation environments, particularly in high-frequency communication systems operating in the millimeter-wave and terahertz bands. By enabling dynamic activation at arbitrary positions along a dielectric waveguide, pinching antennas offer unprecedented channel reconfigurability and the ability to provide line-of-sight (LoS) links in scenarios with severe LoS blockages. The performance of pinching-antenna systems is highly dependent on the optimized placement of the pinching antennas, which must be jointly considered with traditional resource allocation (RA) variables -- including transmission power, time slots, and subcarriers. The resulting joint RA problems are typically non-convex with complex variable coupling, necessitating sophisticated optimization techniques. This article provides a comprehensive survey of existing RA algorithms designed for pinching-antenna systems, supported by numerical case studies that demonstrate their potential performance gains. Key challenges and open research problems are also identified to guide future developments in this emerging field.
Energy-Efficient Design for Downlink Pinching-Antenna Systems with QoS Guarantee
May 20, 2025



Pinching antennas have recently garnered significant attention due to their ability to dynamically reconfigure wireless propagation environments. Despite notable advancements in this area, the exploration of energy efficiency (EE) maximization in pinching-antenna systems remains relatively underdeveloped. In this paper, we address the EE maximization problem in a downlink time-division multiple access (TDMA)-based multi-user system employing one waveguide and multiple pinching antennas, where each user is subject to a minimum rate constraint to ensure quality-of-service. The formulated optimization problem jointly considers transmit power and time allocations as well as the positioning of pinching antennas, resulting in a non-convex problem. To tackle this challenge, we first obtain the optimal positions of the pinching antennas. Based on this, we establish a feasibility condition for the system. Subsequently, the joint power and time allocation problem is decomposed into two subproblems, which are solved iteratively until convergence. Specifically, the power allocation subproblem is addressed through an iterative approach, where a semi-analytical solution is obtained in each iteration. Likewise, a semi-analytical solution is derived for the time allocation subproblem. Numerical simulations demonstrate that the proposed pinching-antenna-based strategy significantly outperforms both conventional fixed-antenna systems and other benchmark pinching-antenna schemes in terms of EE.
Energy-Efficient Resource Allocation for NOMA-Assisted Uplink Pinching-Antenna Systems
May 12, 2025The pinching-antenna architecture has emerged as a promising solution for reconfiguring wireless propagation environments and enhancing system performance. While prior research has primarily focused on sum-rate maximization or transmit power minimization of pinching-antenna systems, the critical aspect of energy efficiency (EE) has received limited attention. Given the increasing importance of EE in future wireless communication networks, this work investigates EE optimization in a non-orthogonal multiple access (NOMA)-assisted multi-user pinching-antenna uplink system. The problem entails the joint optimization of the users' transmit power and the pinching-antenna position. The resulting optimization problem is non-convex due to tightly coupled variables. To tackle this, we employ an alternating optimization framework to decompose the original problem into two subproblems: one focusing on power allocation and the other on antenna positioning. A low-complexity optimal solution is derived for the power allocation subproblem, while the pinching-antenna positioning subproblem is addressed using a particle swarm optimization algorithm to obtain a high-quality near-optimal solution. Simulation results demonstrate that the proposed scheme significantly outperforms both conventional-antenna configurations and orthogonal multiple access-based pinching-antenna systems in terms of EE.
Sum Rate Maximization for NOMA-Assisted Uplink Pinching-Antenna Systems
May 01, 2025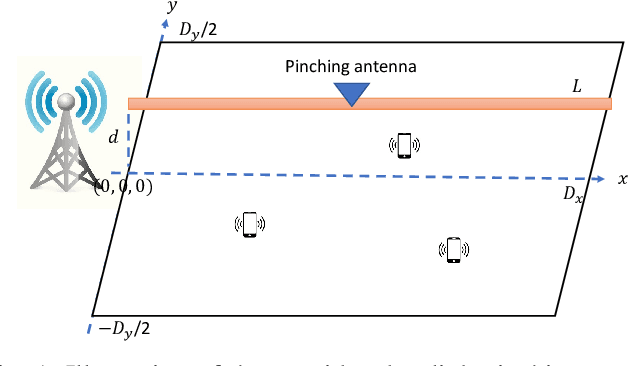
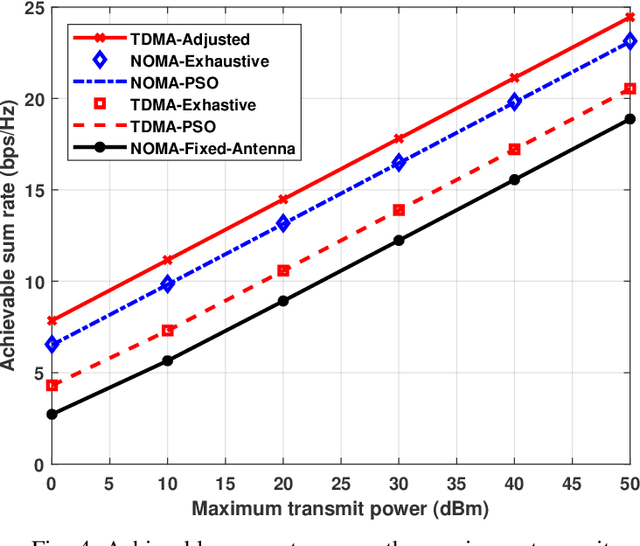
In this paper, we investigate an uplink communication scenario in which multiple users communicate with an access point (AP) employing non-orthogonal multiple access (NOMA). A pinching antenna, which can be activated at an arbitrary point along a dielectric waveguide, is deployed at the AP to dynamically reconfigure user channels. The objective is to maximize the system sum rate by jointly optimizing the pinching-antenna's position and the users' transmit powers. The formulated optimization problem is non-convex, and addressed using the particle swarm optimization (PSO) algorithm. For performance benchmarking, two time division multiple access (TDMA) schemes are considered: one based on the pinching antenna individually activated for each user, and the other based on the single-pinching-antenna configuration serving all users. Numerical results demonstrate that the use of the pinching antenna significantly enhances the system sum rate compared to conventional antenna architectures. Moreover, the NOMA-based scheme outperforms the TDMA-based scheme with a single pinching antenna but is outperformed by the TDMA-based approach when the pinching antenna is adaptively configured for each user. Finally, the proposed PSO-based method is shown to achieve near-optimal performance for both NOMA and TDMA with a common pinching-antenna configuration.
SacFL: Self-Adaptive Federated Continual Learning for Resource-Constrained End Devices
May 01, 2025



The proliferation of end devices has led to a distributed computing paradigm, wherein on-device machine learning models continuously process diverse data generated by these devices. The dynamic nature of this data, characterized by continuous changes or data drift, poses significant challenges for on-device models. To address this issue, continual learning (CL) is proposed, enabling machine learning models to incrementally update their knowledge and mitigate catastrophic forgetting. However, the traditional centralized approach to CL is unsuitable for end devices due to privacy and data volume concerns. In this context, federated continual learning (FCL) emerges as a promising solution, preserving user data locally while enhancing models through collaborative updates. Aiming at the challenges of limited storage resources for CL, poor autonomy in task shift detection, and difficulty in coping with new adversarial tasks in FCL scenario, we propose a novel FCL framework named SacFL. SacFL employs an Encoder-Decoder architecture to separate task-robust and task-sensitive components, significantly reducing storage demands by retaining lightweight task-sensitive components for resource-constrained end devices. Moreover, $\rm{SacFL}$ leverages contrastive learning to introduce an autonomous data shift detection mechanism, enabling it to discern whether a new task has emerged and whether it is a benign task. This capability ultimately allows the device to autonomously trigger CL or attack defense strategy without additional information, which is more practical for end devices. Comprehensive experiments conducted on multiple text and image datasets, such as Cifar100 and THUCNews, have validated the effectiveness of $\rm{SacFL}$ in both class-incremental and domain-incremental scenarios. Furthermore, a demo system has been developed to verify its practicality.