 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSacFL: Self-Adaptive Federated Continual Learning for Resource-Constrained End Devices
May 01, 2025



The proliferation of end devices has led to a distributed computing paradigm, wherein on-device machine learning models continuously process diverse data generated by these devices. The dynamic nature of this data, characterized by continuous changes or data drift, poses significant challenges for on-device models. To address this issue, continual learning (CL) is proposed, enabling machine learning models to incrementally update their knowledge and mitigate catastrophic forgetting. However, the traditional centralized approach to CL is unsuitable for end devices due to privacy and data volume concerns. In this context, federated continual learning (FCL) emerges as a promising solution, preserving user data locally while enhancing models through collaborative updates. Aiming at the challenges of limited storage resources for CL, poor autonomy in task shift detection, and difficulty in coping with new adversarial tasks in FCL scenario, we propose a novel FCL framework named SacFL. SacFL employs an Encoder-Decoder architecture to separate task-robust and task-sensitive components, significantly reducing storage demands by retaining lightweight task-sensitive components for resource-constrained end devices. Moreover, $\rm{SacFL}$ leverages contrastive learning to introduce an autonomous data shift detection mechanism, enabling it to discern whether a new task has emerged and whether it is a benign task. This capability ultimately allows the device to autonomously trigger CL or attack defense strategy without additional information, which is more practical for end devices. Comprehensive experiments conducted on multiple text and image datasets, such as Cifar100 and THUCNews, have validated the effectiveness of $\rm{SacFL}$ in both class-incremental and domain-incremental scenarios. Furthermore, a demo system has been developed to verify its practicality.
Task-Specific Knowledge Distillation from the Vision Foundation Model for Enhanced Medical Image Segmentation
Mar 10, 2025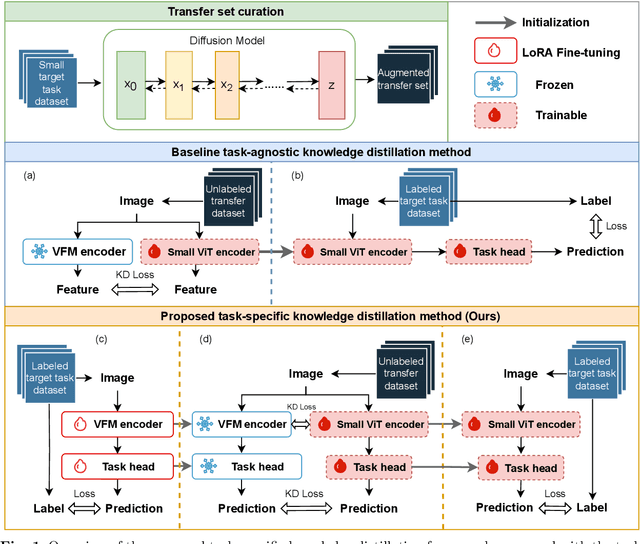
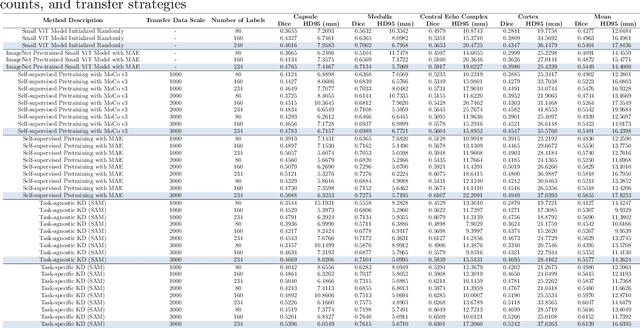
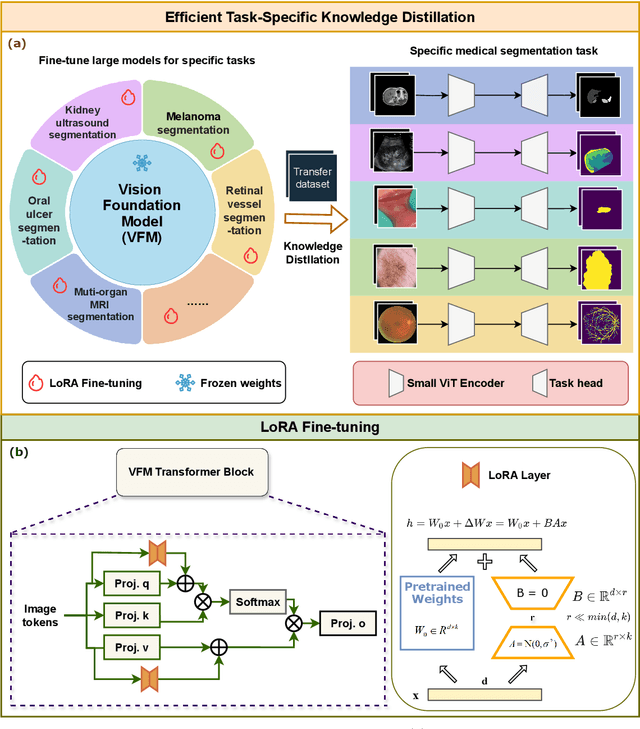
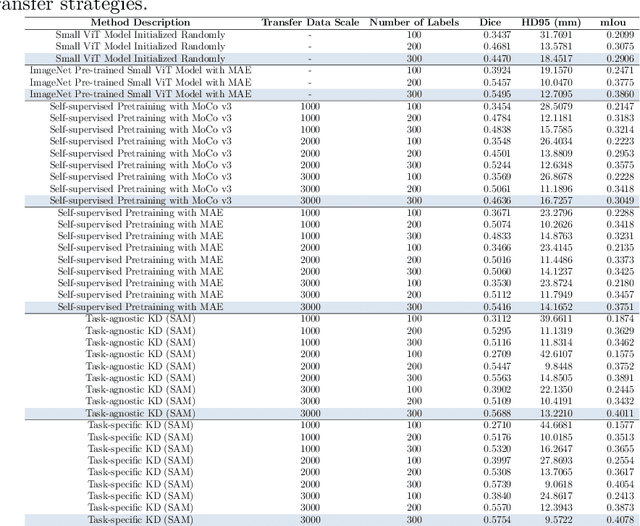
Large-scale pre-trained models, such as Vision Foundation Models (VFMs), have demonstrated impressive performance across various downstream tasks by transferring generalized knowledge, especially when target data is limited. However, their high computational cost and the domain gap between natural and medical images limit their practical application in medical segmentation tasks. Motivated by this, we pose the following important question: "How can we effectively utilize the knowledge of large pre-trained VFMs to train a small, task-specific model for medical image segmentation when training data is limited?" To address this problem, we propose a novel and generalizable task-specific knowledge distillation framework. Our method fine-tunes the VFM on the target segmentation task to capture task-specific features before distilling the knowledge to smaller models, leveraging Low-Rank Adaptation (LoRA) to reduce the computational cost of fine-tuning. Additionally, we incorporate synthetic data generated by diffusion models to augment the transfer set, enhancing model performance in data-limited scenarios. Experimental results across five medical image datasets demonstrate that our method consistently outperforms task-agnostic knowledge distillation and self-supervised pretraining approaches like MoCo v3 and Masked Autoencoders (MAE). For example, on the KidneyUS dataset, our method achieved a 28% higher Dice score than task-agnostic KD using 80 labeled samples for fine-tuning. On the CHAOS dataset, it achieved an 11% improvement over MAE with 100 labeled samples. These results underscore the potential of task-specific knowledge distillation to train accurate, efficient models for medical image segmentation in data-constrained settings.
Semantic Prior Distillation with Vision Foundation Model for Enhanced Rapid Bone Scintigraphy Image Restoration
Mar 04, 2025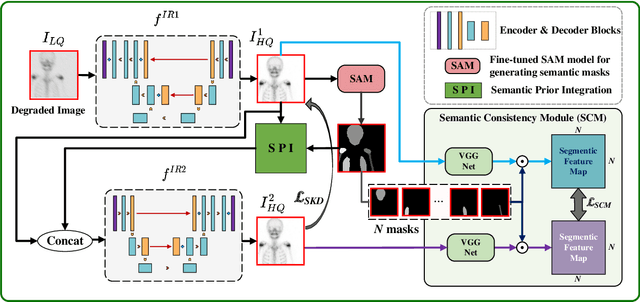
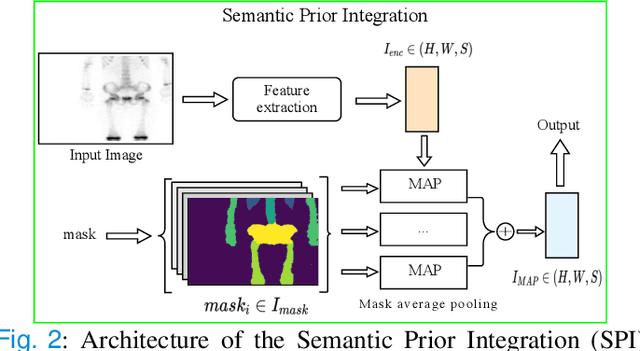
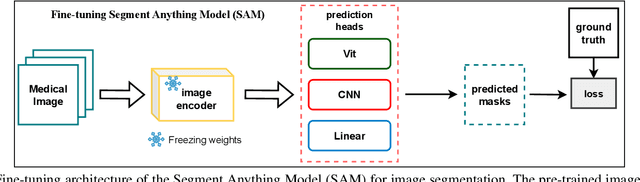
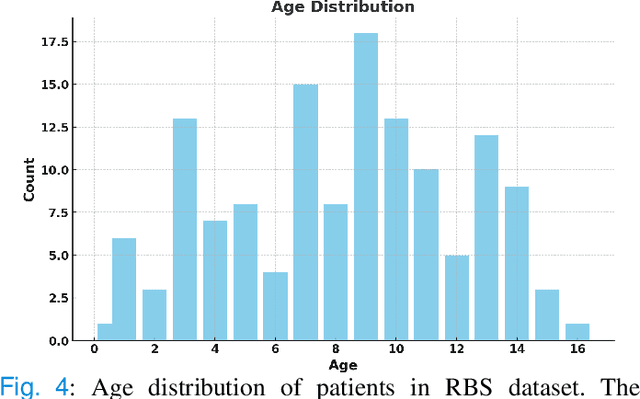
Rapid bone scintigraphy is an essential tool for diagnosing skeletal diseases and tumor metastasis in pediatric patients, as it reduces scan time and minimizes patient discomfort. However, rapid scans often result in poor image quality, potentially affecting diagnosis due to reduced resolution and detail, which make it challenging to identify and evaluate finer anatomical structures. To address this issue, we propose the first application of SAM-based semantic priors for medical image restoration, leveraging the Segment Anything Model (SAM) to enhance rapid bone scintigraphy images in pediatric populations. Our method comprises two cascaded networks, $f^{IR1}$ and $f^{IR2}$, augmented by three key modules: a Semantic Prior Integration (SPI) module, a Semantic Knowledge Distillation (SKD) module, and a Semantic Consistency Module (SCM). The SPI and SKD modules incorporate domain-specific semantic information from a fine-tuned SAM, while the SCM maintains consistent semantic feature representation throughout the cascaded networks. In addition, we will release a novel Rapid Bone Scintigraphy dataset called RBS, the first dataset dedicated to rapid bone scintigraphy image restoration in pediatric patients. RBS consists of 137 pediatric patients aged between 0.5 and 16 years who underwent both standard and rapid bone scans. The dataset includes scans performed at 20 cm/min (standard) and 40 cm/min (rapid), representing a $2\times$ acceleration. We conducted extensive experiments on both the publicly available endoscopic dataset and RBS. The results demonstrate that our method outperforms all existing methods across various metrics, including PSNR, SSIM, FID, and LPIPS.
Topology-Aware Wavelet Mamba for Airway Structure Segmentation in Postoperative Recurrent Nasopharyngeal Carcinoma CT Scans
Feb 20, 2025Nasopharyngeal carcinoma (NPC) patients often undergo radiotherapy and chemotherapy, which can lead to postoperative complications such as limited mouth opening and joint stiffness, particularly in recurrent cases that require re-surgery. These complications can affect airway function, making accurate postoperative airway risk assessment essential for managing patient care. Accurate segmentation of airway-related structures in postoperative CT scans is crucial for assessing these risks. This study introduces TopoWMamba (Topology-aware Wavelet Mamba), a novel segmentation model specifically designed to address the challenges of postoperative airway risk evaluation in recurrent NPC patients. TopoWMamba combines wavelet-based multi-scale feature extraction, state-space sequence modeling, and topology-aware modules to segment airway-related structures in CT scans robustly. By leveraging the Wavelet-based Mamba Block (WMB) for hierarchical frequency decomposition and the Snake Conv VSS (SCVSS) module to preserve anatomical continuity, TopoWMamba effectively captures both fine-grained boundaries and global structural context, crucial for accurate segmentation in complex postoperative scenarios. Through extensive testing on the NPCSegCT dataset, TopoWMamba achieves an average Dice score of 88.02%, outperforming existing models such as UNet, Attention UNet, and SwinUNet. Additionally, TopoWMamba is tested on the SegRap 2023 Challenge dataset, where it shows a significant improvement in trachea segmentation with a Dice score of 95.26%. The proposed model provides a strong foundation for automated segmentation, enabling more accurate postoperative airway risk evaluation.
Graph Neural Networks for Protein-Protein Interactions -- A Short Survey
Apr 16, 2024Protein-protein interactions (PPIs) play key roles in a broad range of biological processes. Numerous strategies have been proposed for predicting PPIs, and among them, graph-based methods have demonstrated promising outcomes owing to the inherent graph structure of PPI networks. This paper reviews various graph-based methodologies, and discusses their applications in PPI prediction. We classify these approaches into two primary groups based on their model structures. The first category employs Graph Neural Networks (GNN) or Graph Convolutional Networks (GCN), while the second category utilizes Graph Attention Networks (GAT), Graph Auto-Encoders and Graph-BERT. We highlight the distinctive methodologies of each approach in managing the graph-structured data inherent in PPI networks and anticipate future research directions in this domain.
Blockchain-empowered Federated Learning: Benefits, Challenges, and Solutions
Mar 01, 2024Federated learning (FL) is a distributed machine learning approach that protects user data privacy by training models locally on clients and aggregating them on a parameter server. While effective at preserving privacy, FL systems face limitations such as single points of failure, lack of incentives, and inadequate security. To address these challenges, blockchain technology is integrated into FL systems to provide stronger security, fairness, and scalability. However, blockchain-empowered FL (BC-FL) systems introduce additional demands on network, computing, and storage resources. This survey provides a comprehensive review of recent research on BC-FL systems, analyzing the benefits and challenges associated with blockchain integration. We explore why blockchain is applicable to FL, how it can be implemented, and the challenges and existing solutions for its integration. Additionally, we offer insights on future research directions for the BC-FL system.
Online Parameter Identification of Generalized Non-cooperative Game
Oct 14, 2023


This work studies the parameter identification problem of a generalized non-cooperative game, where each player's cost function is influenced by an observable signal and some unknown parameters. We consider the scenario where equilibrium of the game at some observable signals can be observed with noises, whereas our goal is to identify the unknown parameters with the observed data. Assuming that the observable signals and the corresponding noise-corrupted equilibriums are acquired sequentially, we construct this parameter identification problem as online optimization and introduce a novel online parameter identification algorithm. To be specific, we construct a regularized loss function that balances conservativeness and correctiveness, where the conservativeness term ensures that the new estimates do not deviate significantly from the current estimates, while the correctiveness term is captured by the Karush-Kuhn-Tucker conditions. We then prove that when the players' cost functions are linear with respect to the unknown parameters and the learning rate of the online parameter identification algorithm satisfies \mu_k \propto 1/\sqrt{k}, along with other assumptions, the regret bound of the proposed algorithm is O(\sqrt{K}). Finally, we conduct numerical simulations on a Nash-Cournot problem to demonstrate that the performance of the online identification algorithm is comparable to that of the offline setting.
MMTSA: Multimodal Temporal Segment Attention Network for Efficient Human Activity Recognition
Oct 14, 2022
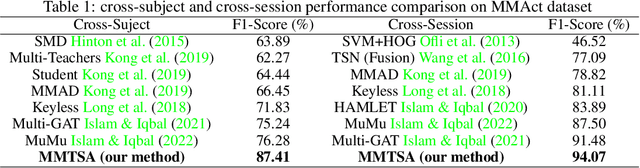


Multimodal sensors (e.g., visual, non-visual, and wearable) provide complementary information to develop robust perception systems for recognizing activities. However, most existing algorithms use dense sampling and heterogeneous sub-network to extract unimodal features and fuse them at the end of their framework, which causes data redundancy, lack of complementary multimodal information and high computational cost. In this paper, we propose a new novel multimodal neural architecture based on RGB and IMU wearable sensors (e.g., accelerometer, gyroscope) for human activity recognition called Multimodal Temporal Segment Attention Network (MMTSA). MMTSA first employs a multimodal data isomorphism mechanism based on Gramian Angular Field (GAF) and then applies a novel multimodal sparse sampling method to reduce redundancy. Moreover, we propose an inter-segment attention module in MMTSA to fuse multimodal features effectively and efficiently. We demonstrate the importance of imu data imaging and attention mechanism in human activity recognition by rigorous evaluation on three public datasets, and achieve superior improvements ($11.13\%$ on the MMAct dataset) than the previous state-of-the-art methods. The code is available at: https://github.com/THU-CS-PI/MMTSA.
Dynamic Bicycle Dispatching of Dockless Public Bicycle-sharing Systems using Multi-objective Reinforcement Learning
Jan 19, 2021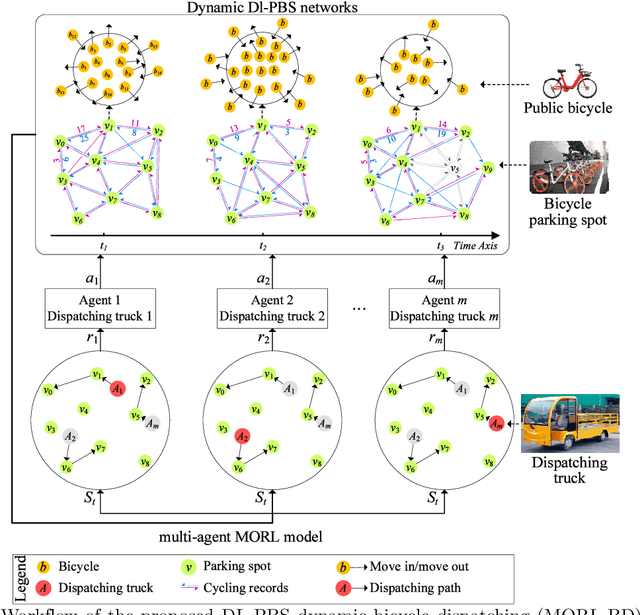
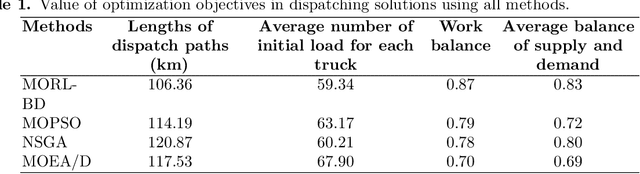

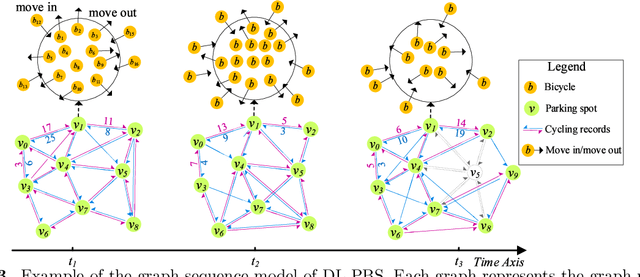
As a new generation of Public Bicycle-sharing Systems (PBS), the dockless PBS (DL-PBS) is an important application of cyber-physical systems and intelligent transportation. How to use AI to provide efficient bicycle dispatching solutions based on dynamic bicycle rental demand is an essential issue for DL-PBS. In this paper, we propose a dynamic bicycle dispatching algorithm based on multi-objective reinforcement learning (MORL-BD) to provide the optimal bicycle dispatching solution for DL-PBS. We model the DL-PBS system from the perspective of CPS and use deep learning to predict the layout of bicycle parking spots and the dynamic demand of bicycle dispatching. We define the multi-route bicycle dispatching problem as a multi-objective optimization problem by considering the optimization objectives of dispatching costs, dispatch truck's initial load, workload balance among the trucks, and the dynamic balance of bicycle supply and demand. On this basis, the collaborative multi-route bicycle dispatching problem among multiple dispatch trucks is modeled as a multi-agent MORL model. All dispatch paths between parking spots are defined as state spaces, and the reciprocal of dispatching costs is defined as a reward. Each dispatch truck is equipped with an agent to learn the optimal dispatch path in the dynamic DL-PBS network. We create an elite list to store the Pareto optimal solutions of bicycle dispatch paths found in each action, and finally, get the Pareto frontier. Experimental results on the actual DL-PBS systems show that compared with existing methods, MORL-BD can find a higher quality Pareto frontier with less execution time.
Dynamic Planning of Bicycle Stations in Dockless Public Bicycle-sharing System Using Gated Graph Neural Network
Jan 19, 2021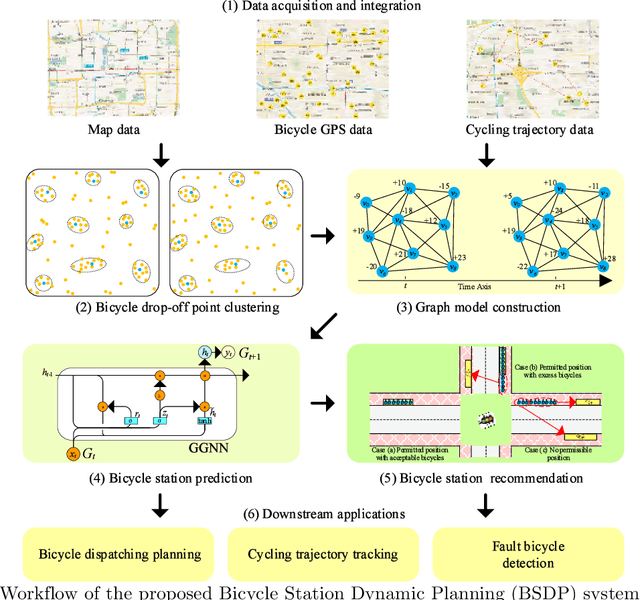
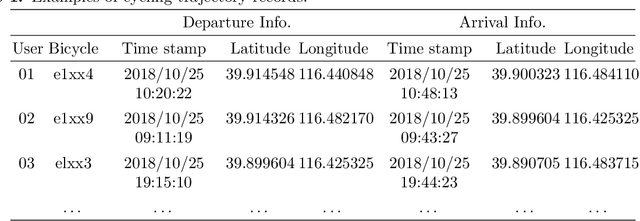

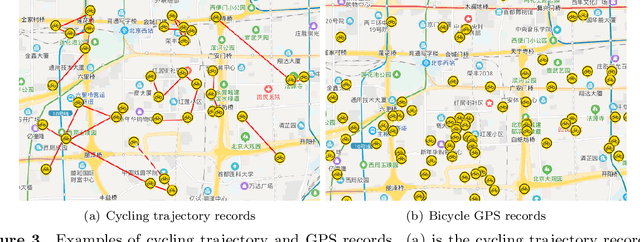
Benefiting from convenient cycling and flexible parking locations, the Dockless Public Bicycle-sharing (DL-PBS) network becomes increasingly popular in many countries. However, redundant and low-utility stations waste public urban space and maintenance costs of DL-PBS vendors. In this paper, we propose a Bicycle Station Dynamic Planning (BSDP) system to dynamically provide the optimal bicycle station layout for the DL-PBS network. The BSDP system contains four modules: bicycle drop-off location clustering, bicycle-station graph modeling, bicycle-station location prediction, and bicycle-station layout recommendation. In the bicycle drop-off location clustering module, candidate bicycle stations are clustered from each spatio-temporal subset of the large-scale cycling trajectory records. In the bicycle-station graph modeling module, a weighted digraph model is built based on the clustering results and inferior stations with low station revenue and utility are filtered. Then, graph models across time periods are combined to create a graph sequence model. In the bicycle-station location prediction module, the GGNN model is used to train the graph sequence data and dynamically predict bicycle stations in the next period. In the bicycle-station layout recommendation module, the predicted bicycle stations are fine-tuned according to the government urban management plan, which ensures that the recommended station layout is conducive to city management, vendor revenue, and user convenience. Experiments on actual DL-PBS networks verify the effectiveness, accuracy and feasibility of the proposed BSDP system.