 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTKG-Thinker: Towards Dynamic Reasoning over Temporal Knowledge Graphs via Agentic Reinforcement Learning
Feb 05, 2026Temporal knowledge graph question answering (TKGQA) aims to answer time-sensitive questions by leveraging temporal knowledge bases. While Large Language Models (LLMs) demonstrate significant potential in TKGQA, current prompting strategies constrain their efficacy in two primary ways. First, they are prone to reasoning hallucinations under complex temporal constraints. Second, static prompting limits model autonomy and generalization, as it lack optimization through dynamic interaction with temporal knowledge graphs (TKGs) environments. To address these limitations, we propose \textbf{TKG-Thinker}, a novel agent equipped with autonomous planning and adaptive retrieval capabilities for reasoning over TKGs. Specifically, TKG-Thinker performs in-depth temporal reasoning through dynamic multi-turn interactions with TKGs via a dual-training strategy. We first apply Supervised Fine-Tuning (SFT) with chain-of thought data to instill core planning capabilities, followed by a Reinforcement Learning (RL) stage that leverages multi-dimensional rewards to refine reasoning policies under intricate temporal constraints. Experimental results on benchmark datasets with three open-source LLMs show that TKG-Thinker achieves state-of-the-art performance and exhibits strong generalization across complex TKGQA settings.
RAPTOR: Ridge-Adaptive Logistic Probes
Jan 29, 2026Probing studies what information is encoded in a frozen LLM's layer representations by training a lightweight predictor on top of them. Beyond analysis, probes are often used operationally in probe-then-steer pipelines: a learned concept vector is extracted from a probe and injected via additive activation steering by adding it to a layer representation during the forward pass. The effectiveness of this pipeline hinges on estimating concept vectors that are accurate, directionally stable under ablation, and inexpensive to obtain. Motivated by these desiderata, we propose RAPTOR (Ridge-Adaptive Logistic Probe), a simple L2-regularized logistic probe whose validation-tuned ridge strength yields concept vectors from normalized weights. Across extensive experiments on instruction-tuned LLMs and human-written concept datasets, RAPTOR matches or exceeds strong baselines in accuracy while achieving competitive directional stability and substantially lower training cost; these quantitative results are supported by qualitative downstream steering demonstrations. Finally, using the Convex Gaussian Min-max Theorem (CGMT), we provide a mechanistic characterization of ridge logistic regression in an idealized Gaussian teacher-student model in the high-dimensional few-shot regime, explaining how penalty strength mediates probe accuracy and concept-vector stability and yielding structural predictions that qualitatively align with trends observed on real LLM embeddings.
Molmo2: Open Weights and Data for Vision-Language Models with Video Understanding and Grounding
Jan 15, 2026Today's strongest video-language models (VLMs) remain proprietary. The strongest open-weight models either rely on synthetic data from proprietary VLMs, effectively distilling from them, or do not disclose their training data or recipe. As a result, the open-source community lacks the foundations needed to improve on the state-of-the-art video (and image) language models. Crucially, many downstream applications require more than just high-level video understanding; they require grounding -- either by pointing or by tracking in pixels. Even proprietary models lack this capability. We present Molmo2, a new family of VLMs that are state-of-the-art among open-source models and demonstrate exceptional new capabilities in point-driven grounding in single image, multi-image, and video tasks. Our key contribution is a collection of 7 new video datasets and 2 multi-image datasets, including a dataset of highly detailed video captions for pre-training, a free-form video Q&A dataset for fine-tuning, a new object tracking dataset with complex queries, and an innovative new video pointing dataset, all collected without the use of closed VLMs. We also present a training recipe for this data utilizing an efficient packing and message-tree encoding scheme, and show bi-directional attention on vision tokens and a novel token-weight strategy improves performance. Our best-in-class 8B model outperforms others in the class of open weight and data models on short videos, counting, and captioning, and is competitive on long-videos. On video-grounding Molmo2 significantly outperforms existing open-weight models like Qwen3-VL (35.5 vs 29.6 accuracy on video counting) and surpasses proprietary models like Gemini 3 Pro on some tasks (38.4 vs 20.0 F1 on video pointing and 56.2 vs 41.1 J&F on video tracking).
DAP-MAE: Domain-Adaptive Point Cloud Masked Autoencoder for Effective Cross-Domain Learning
Oct 24, 2025Compared to 2D data, the scale of point cloud data in different domains available for training, is quite limited. Researchers have been trying to combine these data of different domains for masked autoencoder (MAE) pre-training to leverage such a data scarcity issue. However, the prior knowledge learned from mixed domains may not align well with the downstream 3D point cloud analysis tasks, leading to degraded performance. To address such an issue, we propose the Domain-Adaptive Point Cloud Masked Autoencoder (DAP-MAE), an MAE pre-training method, to adaptively integrate the knowledge of cross-domain datasets for general point cloud analysis. In DAP-MAE, we design a heterogeneous domain adapter that utilizes an adaptation mode during pre-training, enabling the model to comprehensively learn information from point clouds across different domains, while employing a fusion mode in the fine-tuning to enhance point cloud features. Meanwhile, DAP-MAE incorporates a domain feature generator to guide the adaptation of point cloud features to various downstream tasks. With only one pre-training, DAP-MAE achieves excellent performance across four different point cloud analysis tasks, reaching 95.18% in object classification on ScanObjectNN and 88.45% in facial expression recognition on Bosphorus.
* 14 pages, 7 figures, conference
One Trajectory, One Token: Grounded Video Tokenization via Panoptic Sub-object Trajectory
May 29, 2025Effective video tokenization is critical for scaling transformer models for long videos. Current approaches tokenize videos using space-time patches, leading to excessive tokens and computational inefficiencies. The best token reduction strategies degrade performance and barely reduce the number of tokens when the camera moves. We introduce grounded video tokenization, a paradigm that organizes tokens based on panoptic sub-object trajectories rather than fixed patches. Our method aligns with fundamental perceptual principles, ensuring that tokenization reflects scene complexity rather than video duration. We propose TrajViT, a video encoder that extracts object trajectories and converts them into semantically meaningful tokens, significantly reducing redundancy while maintaining temporal coherence. Trained with contrastive learning, TrajViT significantly outperforms space-time ViT (ViT3D) across multiple video understanding benchmarks, e.g., TrajViT outperforms ViT3D by a large margin of 6% top-5 recall in average at video-text retrieval task with 10x token deduction. We also show TrajViT as a stronger model than ViT3D for being the video encoder for modern VideoLLM, obtaining an average of 5.2% performance improvement across 6 VideoQA benchmarks while having 4x faster training time and 18x less inference FLOPs. TrajViT is the first efficient encoder to consistently outperform ViT3D across diverse video analysis tasks, making it a robust and scalable solution.
InversionGNN: A Dual Path Network for Multi-Property Molecular Optimization
Mar 03, 2025



Exploring chemical space to find novel molecules that simultaneously satisfy multiple properties is crucial in drug discovery. However, existing methods often struggle with trading off multiple properties due to the conflicting or correlated nature of chemical properties. To tackle this issue, we introduce InversionGNN framework, an effective yet sample-efficient dual-path graph neural network (GNN) for multi-objective drug discovery. In the direct prediction path of InversionGNN, we train the model for multi-property prediction to acquire knowledge of the optimal combination of functional groups. Then the learned chemical knowledge helps the inversion generation path to generate molecules with required properties. In order to decode the complex knowledge of multiple properties in the inversion path, we propose a gradient-based Pareto search method to balance conflicting properties and generate Pareto optimal molecules. Additionally, InversionGNN is able to search the full Pareto front approximately in discrete chemical space. Comprehensive experimental evaluations show that InversionGNN is both effective and sample-efficient in various discrete multi-objective settings including drug discovery.
Molecule Generation for Target Protein Binding with Hierarchical Consistency Diffusion Model
Mar 02, 2025Effective generation of molecular structures, or new chemical entities, that bind to target proteins is crucial for lead identification and optimization in drug discovery. Despite advancements in atom- and motif-wise deep learning models for 3D molecular generation, current methods often struggle with validity and reliability. To address these issues, we develop the Atom-Motif Consistency Diffusion Model (AMDiff), utilizing a joint-training paradigm for multi-view learning. This model features a hierarchical diffusion architecture that integrates both atom- and motif-level views of molecules, allowing for comprehensive exploration of complementary information. By leveraging classifier-free guidance and incorporating binding site features as conditional inputs, AMDiff ensures robust molecule generation across diverse targets. Compared to existing approaches, AMDiff exhibits superior validity and novelty in generating molecules tailored to fit various protein pockets. Case studies targeting protein kinases, including Anaplastic Lymphoma Kinase (ALK) and Cyclin-dependent kinase 4 (CDK4), demonstrate the model's capability in structure-based de novo drug design. Overall, AMDiff bridges the gap between atom-view and motif-view drug discovery and speeds up the process of target-aware molecular generation.
Generate Any Scene: Evaluating and Improving Text-to-Vision Generation with Scene Graph Programming
Dec 11, 2024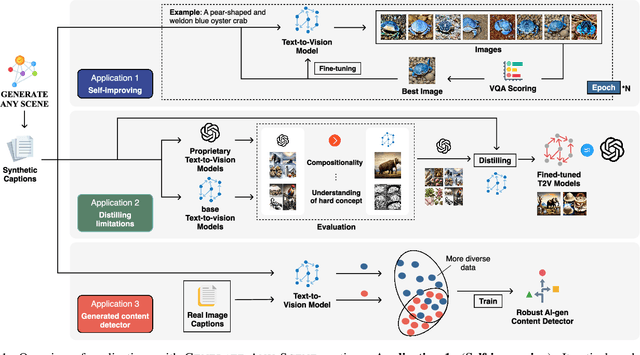
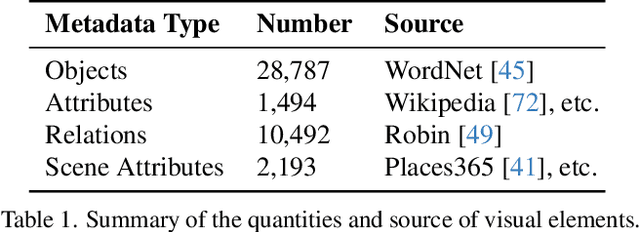
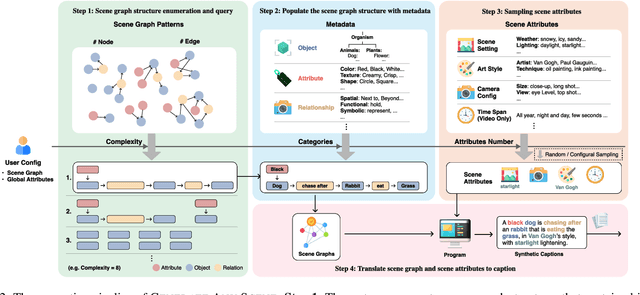
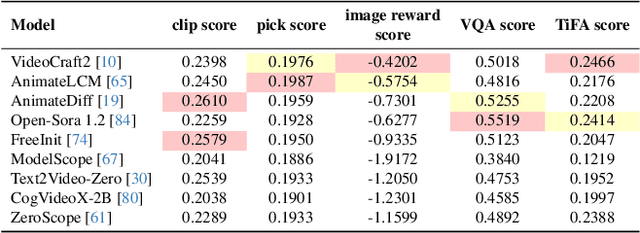
DALL-E and Sora have gained attention by producing implausible images, such as "astronauts riding a horse in space." Despite the proliferation of text-to-vision models that have inundated the internet with synthetic visuals, from images to 3D assets, current benchmarks predominantly evaluate these models on real-world scenes paired with captions. We introduce Generate Any Scene, a framework that systematically enumerates scene graphs representing a vast array of visual scenes, spanning realistic to imaginative compositions. Generate Any Scene leverages 'scene graph programming', a method for dynamically constructing scene graphs of varying complexity from a structured taxonomy of visual elements. This taxonomy includes numerous objects, attributes, and relations, enabling the synthesis of an almost infinite variety of scene graphs. Using these structured representations, Generate Any Scene translates each scene graph into a caption, enabling scalable evaluation of text-to-vision models through standard metrics. We conduct extensive evaluations across multiple text-to-image, text-to-video, and text-to-3D models, presenting key findings on model performance. We find that DiT-backbone text-to-image models align more closely with input captions than UNet-backbone models. Text-to-video models struggle with balancing dynamics and consistency, while both text-to-video and text-to-3D models show notable gaps in human preference alignment. We demonstrate the effectiveness of Generate Any Scene by conducting three practical applications leveraging captions generated by Generate Any Scene: 1) a self-improving framework where models iteratively enhance their performance using generated data, 2) a distillation process to transfer specific strengths from proprietary models to open-source counterparts, and 3) improvements in content moderation by identifying and generating challenging synthetic data.
MS-Glance: Non-semantic context vectors and the applications in supervising image reconstruction
Oct 31, 2024Non-semantic context information is crucial for visual recognition, as the human visual perception system first uses global statistics to process scenes rapidly before identifying specific objects. However, while semantic information is increasingly incorporated into computer vision tasks such as image reconstruction, non-semantic information, such as global spatial structures, is often overlooked. To bridge the gap, we propose a biologically informed non-semantic context descriptor, \textbf{MS-Glance}, along with the Glance Index Measure for comparing two images. A Global Glance vector is formulated by randomly retrieving pixels based on a perception-driven rule from an image to form a vector representing non-semantic global context, while a local Glance vector is a flattened local image window, mimicking a zoom-in observation. The Glance Index is defined as the inner product of two standardized sets of Glance vectors. We evaluate the effectiveness of incorporating Glance supervision in two reconstruction tasks: image fitting with implicit neural representation (INR) and undersampled MRI reconstruction. Extensive experimental results show that MS-Glance outperforms existing image restoration losses across both natural and medical images. The code is available at \url{https://github.com/Z7Gao/MSGlance}.
Parameter-Efficient Fine-Tuning via Circular Convolution
Jul 27, 2024Low-Rank Adaptation (LoRA) has gained popularity for fine-tuning large foundation models, leveraging low-rank matrices $\mathbf{A}$ and $\mathbf{B}$ to represent weight changes (\textit{i.e.,} $\Delta \mathbf{W} = \mathbf{B} \mathbf{A}$). This method reduces trainable parameters and mitigates heavy memory consumption associated with full delta matrices by sequentially multiplying $\mathbf{A}$ and $\mathbf{B}$ with the activation. Despite its success, the intrinsic low-rank characteristic may limit its performance. Although several variants have been proposed to address this issue, they often overlook the crucial computational and memory efficiency brought by LoRA. In this paper, we propose \underline{C}ir\underline{c}ular \underline{C}onvolution \underline{A}daptation (C$^3$A), which not only achieves high-rank adaptation with enhanced performance but also excels in both computational power and memory utilization. Extensive experiments demonstrate that C$^3$A consistently outperforms LoRA and its variants across various fine-tuning tasks.