 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVisual prompting reimagined: The power of the Activation Prompts
Apr 07, 2026Visual prompting (VP) has emerged as a popular method to repurpose pretrained vision models for adaptation to downstream tasks. Unlike conventional model fine-tuning techniques, VP introduces a universal perturbation directly into the input data to facilitate task-specific fine-tuning rather than modifying model parameters. However, there exists a noticeable performance gap between VP and conventional fine-tuning methods, highlighting an unexplored realm in theory and practice to understand and advance the input-level VP to reduce its current performance gap. Towards this end, we introduce a generalized concept, termed activation prompt (AP), which extends the scope of the input-level VP by enabling universal perturbations to be applied to activation maps within the intermediate layers of the model. By using AP to revisit the problem of VP and employing it as an analytical tool, we demonstrate the intrinsic limitations of VP in both performance and efficiency, revealing why input-level prompting may lack effectiveness compared to AP, which exhibits a model-dependent layer preference. We show that AP is closely related to normalization tuning in convolutional neural networks and vision transformers, although each model type has distinct layer preferences for prompting. We also theoretically elucidate the rationale behind such a preference by analyzing global features across layers. Through extensive experiments across 29 datasets and various model architectures, we provide a comprehensive performance analysis of AP, comparing it with VP and parameter-efficient fine-tuning baselines. Our results demonstrate AP's superiority in both accuracy and efficiency, considering factors such as time, parameters, memory usage, and throughput.
Exposing Weaknesses of Large Reasoning Models through Graph Algorithm Problems
Feb 06, 2026Large Reasoning Models (LRMs) have advanced rapidly; however, existing benchmarks in mathematics, code, and common-sense reasoning remain limited. They lack long-context evaluation, offer insufficient challenge, and provide answers that are difficult to verify programmatically. We introduce GrAlgoBench, a benchmark designed to evaluate LRMs through graph algorithm problems. Such problems are particularly well suited for probing reasoning abilities: they demand long-context reasoning, allow fine-grained control of difficulty levels, and enable standardized, programmatic evaluation. Across nine tasks, our systematic experiments reveal two major weaknesses of current LRMs. First, accuracy deteriorates sharply as context length increases, falling below 50% once graphs exceed 120 nodes. This degradation is driven by frequent execution errors, weak memory, and redundant reasoning. Second, LRMs suffer from an over-thinking phenomenon, primarily caused by extensive yet largely ineffective self-verification, which inflates reasoning traces without improving correctness. By exposing these limitations, GrAlgoBench establishes graph algorithm problems as a rigorous, multidimensional, and practically relevant testbed for advancing the study of reasoning in LRMs. Code is available at https://github.com/Bklight999/GrAlgoBench.
Attacking and Securing Community Detection: A Game-Theoretic Framework
Dec 12, 2025It has been demonstrated that adversarial graphs, i.e., graphs with imperceptible perturbations, can cause deep graph models to fail on classification tasks. In this work, we extend the concept of adversarial graphs to the community detection problem, which is more challenging. We propose novel attack and defense techniques for community detection problem, with the objective of hiding targeted individuals from detection models and enhancing the robustness of community detection models, respectively. These techniques have many applications in real-world scenarios, for example, protecting personal privacy in social networks and understanding camouflage patterns in transaction networks. To simulate interactive attack and defense behaviors, we further propose a game-theoretic framework, called CD-GAME. One player is a graph attacker, while the other player is a Rayleigh Quotient defender. The CD-GAME models the mutual influence and feedback mechanisms between the attacker and the defender, revealing the dynamic evolutionary process of the game. Both players dynamically update their strategies until they reach the Nash equilibrium. Extensive experiments demonstrate the effectiveness of our proposed attack and defense methods, and both outperform existing baselines by a significant margin. Furthermore, CD-GAME provides valuable insights for understanding interactive attack and defense scenarios in community detection problems. We found that in traditional single-step attack or defense, attacker tends to employ strategies that are most effective, but are easily detected and countered by defender. When the interactive game reaches a Nash equilibrium, attacker adopts more imperceptible strategies that can still achieve satisfactory attack effectiveness even after defense.
A Survey of Cross-domain Graph Learning: Progress and Future Directions
Mar 14, 2025
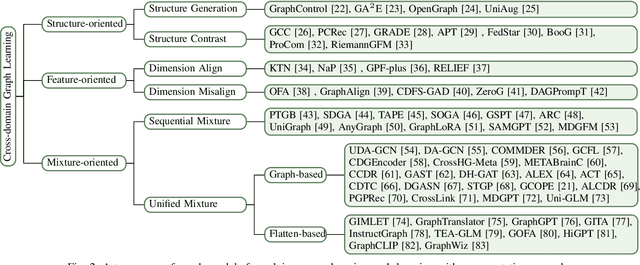


Graph learning plays a vital role in mining and analyzing complex relationships involved in graph data, which is widely used in many real-world applications like transaction networks and communication networks. Foundation models in CV and NLP have shown powerful cross-domain capabilities that are also significant in graph domains. However, existing graph learning approaches struggle with cross-domain tasks. Inspired by successes in CV and NLP, cross-domain graph learning has once again become a focal point of attention to realizing true graph foundation models. In this survey, we present a comprehensive review and analysis of existing works on cross-domain graph learning. Concretely, we first propose a new taxonomy, categorizing existing approaches based on the learned cross-domain information: structure, feature, and structure-feature mixture. Next, we systematically survey representative methods in these categories. Finally, we discuss the remaining limitations of existing studies and highlight promising avenues for future research. Relevant papers are summarized and will be consistently updated at: https://github.com/cshhzhao/Awesome-Cross-Domain-Graph-Learning.
Parameter-Efficient Fine-Tuning via Circular Convolution
Jul 27, 2024Low-Rank Adaptation (LoRA) has gained popularity for fine-tuning large foundation models, leveraging low-rank matrices $\mathbf{A}$ and $\mathbf{B}$ to represent weight changes (\textit{i.e.,} $\Delta \mathbf{W} = \mathbf{B} \mathbf{A}$). This method reduces trainable parameters and mitigates heavy memory consumption associated with full delta matrices by sequentially multiplying $\mathbf{A}$ and $\mathbf{B}$ with the activation. Despite its success, the intrinsic low-rank characteristic may limit its performance. Although several variants have been proposed to address this issue, they often overlook the crucial computational and memory efficiency brought by LoRA. In this paper, we propose \underline{C}ir\underline{c}ular \underline{C}onvolution \underline{A}daptation (C$^3$A), which not only achieves high-rank adaptation with enhanced performance but also excels in both computational power and memory utilization. Extensive experiments demonstrate that C$^3$A consistently outperforms LoRA and its variants across various fine-tuning tasks.
GLBench: A Comprehensive Benchmark for Graph with Large Language Models
Jul 11, 2024



The emergence of large language models (LLMs) has revolutionized the way we interact with graphs, leading to a new paradigm called GraphLLM. Despite the rapid development of GraphLLM methods in recent years, the progress and understanding of this field remain unclear due to the lack of a benchmark with consistent experimental protocols. To bridge this gap, we introduce GLBench, the first comprehensive benchmark for evaluating GraphLLM methods in both supervised and zero-shot scenarios. GLBench provides a fair and thorough evaluation of different categories of GraphLLM methods, along with traditional baselines such as graph neural networks. Through extensive experiments on a collection of real-world datasets with consistent data processing and splitting strategies, we have uncovered several key findings. Firstly, GraphLLM methods outperform traditional baselines in supervised settings, with LLM-as-enhancers showing the most robust performance. However, using LLMs as predictors is less effective and often leads to uncontrollable output issues. We also notice that no clear scaling laws exist for current GraphLLM methods. In addition, both structures and semantics are crucial for effective zero-shot transfer, and our proposed simple baseline can even outperform several models tailored for zero-shot scenarios. The data and code of the benchmark can be found at https://github.com/NineAbyss/GLBench.
Parameter-Efficient Fine-Tuning with Discrete Fourier Transform
May 05, 2024Low-rank adaptation~(LoRA) has recently gained much interest in fine-tuning foundation models. It effectively reduces the number of trainable parameters by incorporating low-rank matrices $A$ and $B$ to represent the weight change, i.e., $\Delta W=BA$. Despite LoRA's progress, it faces storage challenges when handling extensive customization adaptations or larger base models. In this work, we aim to further compress trainable parameters by enjoying the powerful expressiveness of the Fourier transform. Specifically, we introduce FourierFT, which treats $\Delta W$ as a matrix in the spatial domain and learns only a small fraction of its spectral coefficients. With the trained spectral coefficients, we implement the inverse discrete Fourier transform to recover $\Delta W$. Empirically, our FourierFT method shows comparable or better performance with fewer parameters than LoRA on various tasks, including natural language understanding, natural language generation, instruction tuning, and image classification. For example, when performing instruction tuning on the LLaMA2-7B model, FourierFT surpasses LoRA with only 0.064M trainable parameters, compared to LoRA's 33.5M. Our code is released at \url{https://github.com/Chaos96/fourierft}.
All in One and One for All: A Simple yet Effective Method towards Cross-domain Graph Pretraining
Feb 15, 2024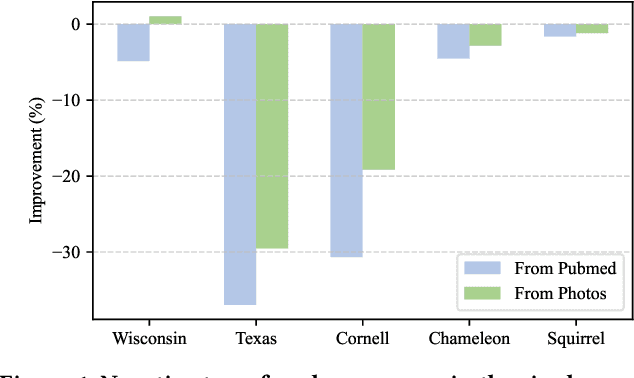

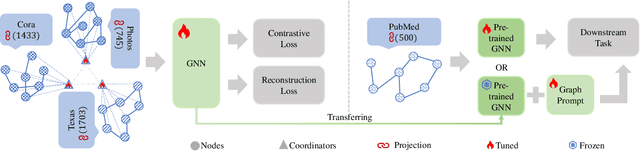

Large Language Models (LLMs) have revolutionized the fields of computer vision (CV) and natural language processing (NLP). One of the most notable advancements of LLMs is that a single model is trained on vast and diverse datasets spanning multiple domains -- a paradigm we term `All in One'. This methodology empowers LLMs with super generalization capabilities, facilitating an encompassing comprehension of varied data distributions. Leveraging these capabilities, a single LLM demonstrates remarkable versatility across a variety of domains -- a paradigm we term `One for All'. However, applying this idea to the graph field remains a formidable challenge, with cross-domain pretraining often resulting in negative transfer. This issue is particularly important in few-shot learning scenarios, where the paucity of training data necessitates the incorporation of external knowledge sources. In response to this challenge, we propose a novel approach called Graph COordinators for PrEtraining (GCOPE), that harnesses the underlying commonalities across diverse graph datasets to enhance few-shot learning. Our novel methodology involves a unification framework that amalgamates disparate graph datasets during the pretraining phase to distill and transfer meaningful knowledge to target tasks. Extensive experiments across multiple graph datasets demonstrate the superior efficacy of our approach. By successfully leveraging the synergistic potential of multiple graph datasets for pretraining, our work stands as a pioneering contribution to the realm of graph foundational model.
To Generate or Not? Safety-Driven Unlearned Diffusion Models Are Still Easy To Generate Unsafe Images For Now
Oct 18, 2023The recent advances in diffusion models (DMs) have revolutionized the generation of complex and diverse images. However, these models also introduce potential safety hazards, such as the production of harmful content and infringement of data copyrights. Although there have been efforts to create safety-driven unlearning methods to counteract these challenges, doubts remain about their capabilities. To bridge this uncertainty, we propose an evaluation framework built upon adversarial attacks (also referred to as adversarial prompts), in order to discern the trustworthiness of these safety-driven unlearned DMs. Specifically, our research explores the (worst-case) robustness of unlearned DMs in eradicating unwanted concepts, styles, and objects, assessed by the generation of adversarial prompts. We develop a novel adversarial learning approach called UnlearnDiff that leverages the inherent classification capabilities of DMs to streamline the generation of adversarial prompts, making it as simple for DMs as it is for image classification attacks. This technique streamlines the creation of adversarial prompts, making the process as intuitive for generative modeling as it is for image classification assaults. Through comprehensive benchmarking, we assess the unlearning robustness of five prevalent unlearned DMs across multiple tasks. Our results underscore the effectiveness and efficiency of UnlearnDiff when compared to state-of-the-art adversarial prompting methods. Codes are available at https://github.com/OPTML-Group/Diffusion-MU-Attack. WARNING: This paper contains model outputs that may be offensive in nature.
Selectivity Drives Productivity: Efficient Dataset Pruning for Enhanced Transfer Learning
Oct 16, 2023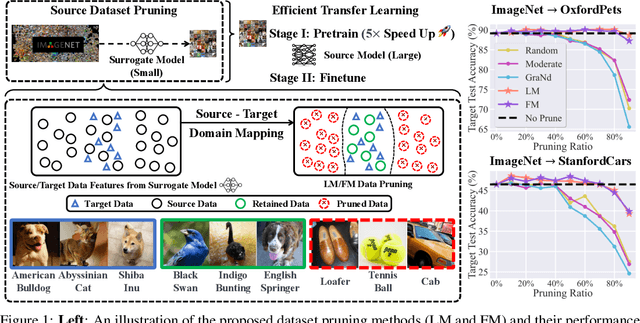


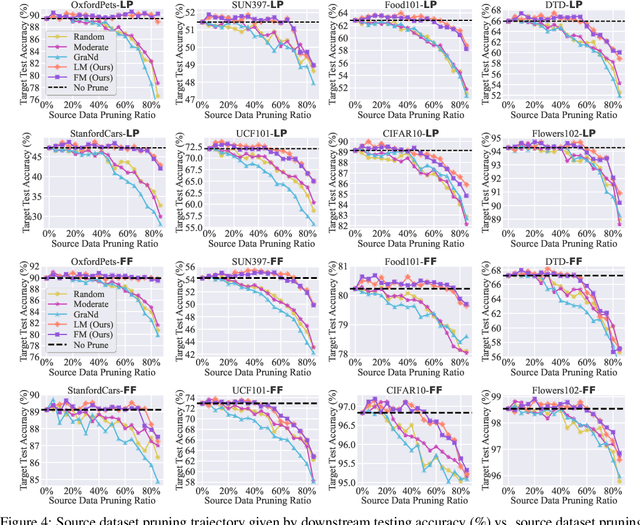
Massive data is often considered essential for deep learning applications, but it also incurs significant computational and infrastructural costs. Therefore, dataset pruning (DP) has emerged as an effective way to improve data efficiency by identifying and removing redundant training samples without sacrificing performance. In this work, we aim to address the problem of DP for transfer learning, i.e., how to prune a source dataset for improved pretraining efficiency and lossless finetuning accuracy on downstream target tasks. To our best knowledge, the problem of DP for transfer learning remains open, as previous studies have primarily addressed DP and transfer learning as separate problems. By contrast, we establish a unified viewpoint to integrate DP with transfer learning and find that existing DP methods are not suitable for the transfer learning paradigm. We then propose two new DP methods, label mapping and feature mapping, for supervised and self-supervised pretraining settings respectively, by revisiting the DP problem through the lens of source-target domain mapping. Furthermore, we demonstrate the effectiveness of our approach on numerous transfer learning tasks. We show that source data classes can be pruned by up to 40% ~ 80% without sacrificing downstream performance, resulting in a significant 2 ~ 5 times speed-up during the pretraining stage. Besides, our proposal exhibits broad applicability and can improve other computationally intensive transfer learning techniques, such as adversarial pretraining. Codes are available at https://github.com/OPTML-Group/DP4TL.