 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRethinking Token Pruning for Historical Screenshots in GUI Visual Agents: Semantic, Spatial, and Temporal Perspectives
Mar 27, 2026In recent years, GUI visual agents built upon Multimodal Large Language Models (MLLMs) have demonstrated strong potential in navigation tasks. However, high-resolution GUI screenshots produce a large number of visual tokens, making the direct preservation of complete historical information computationally expensive. In this paper, we conduct an empirical study on token pruning for historical screenshots in GUI scenarios and distill three practical insights that are crucial for designing effective pruning strategies. First, we observe that GUI screenshots exhibit a distinctive foreground-background semantic composition. To probe this property, we apply a simple edge-based separation to partition screenshots into foreground and background regions. Surprisingly, we find that, contrary to the common assumption that background areas have little semantic value, they effectively capture interface-state transitions, thereby providing auxiliary cues for GUI reasoning. Second, compared with carefully designed pruning strategies, random pruning possesses an inherent advantage in preserving spatial structure, enabling better performance under the same computational budget. Finally, we observe that GUI Agents exhibit a recency effect similar to human cognition: by allocating larger token budgets to more recent screenshots and heavily compressing distant ones, we can significantly reduce computational cost while maintaining nearly unchanged performance. These findings offer new insights and practical guidance for the design of efficient GUI visual agents.
Temporal Gains, Spatial Costs: Revisiting Video Fine-Tuning in Multimodal Large Language Models
Mar 18, 2026Multimodal large language models (MLLMs) are typically trained in multiple stages, with video-based supervised fine-tuning (Video-SFT) serving as a key step for improving visual understanding. Yet its effect on the fine-grained evolution of visual capabilities, particularly the balance between spatial and temporal understanding, remains poorly understood. In this paper, we systematically study how Video-SFT reshapes visual capabilities in MLLMs. Across architectures, parameter scales, and frame sampling settings, we observe a consistent pattern: Video-SFT reliably improves video performance, but often yields limited gains or even degradation on static image benchmarks. We further show that this trade-off is closely tied to temporal budget: increasing the number of sampled frames generally improves video performance, but does not reliably improve static image performance. Motivated by this finding, we study an instruction-aware Hybrid-Frame strategy that adaptively allocates frame counts and partially mitigates the image-video trade-off. Our results indicate that Video-SFT is not a free lunch for MLLMs, and preserving spatial understanding remains a central challenge in joint image-video training.
Unveiling Intrinsic Text Bias in Multimodal Large Language Models through Attention Key-Space Analysis
Oct 30, 2025Multimodal large language models (MLLMs) exhibit a pronounced preference for textual inputs when processing vision-language data, limiting their ability to reason effectively from visual evidence. Unlike prior studies that attribute this text bias to external factors such as data imbalance or instruction tuning, we propose that the bias originates from the model's internal architecture. Specifically, we hypothesize that visual key vectors (Visual Keys) are out-of-distribution (OOD) relative to the text key space learned during language-only pretraining. Consequently, these visual keys receive systematically lower similarity scores during attention computation, leading to their under-utilization in the context representation. To validate this hypothesis, we extract key vectors from LLaVA and Qwen2.5-VL and analyze their distributional structures using qualitative (t-SNE) and quantitative (Jensen-Shannon divergence) methods. The results provide direct evidence that visual and textual keys occupy markedly distinct subspaces within the attention space. The inter-modal divergence is statistically significant, exceeding intra-modal variation by several orders of magnitude. These findings reveal that text bias arises from an intrinsic misalignment within the attention key space rather than solely from external data factors.
Vision-EKIPL: External Knowledge-Infused Policy Learning for Visual Reasoning
Jun 07, 2025


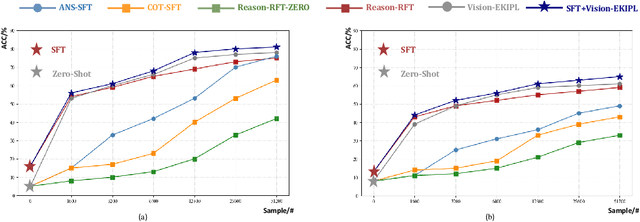
Visual reasoning is crucial for understanding complex multimodal data and advancing Artificial General Intelligence. Existing methods enhance the reasoning capability of Multimodal Large Language Models (MLLMs) through Reinforcement Learning (RL) fine-tuning (e.g., GRPO). However, current RL approaches sample action groups solely from the policy model itself, which limits the upper boundary of the model's reasoning capability and leads to inefficient training. To address these limitations, this paper proposes a novel RL framework called \textbf{Vision-EKIPL}. The core of this framework lies in introducing high-quality actions generated by external auxiliary models during the RL training process to guide the optimization of the policy model. The policy learning with knowledge infusion from external models significantly expands the model's exploration space, effectively improves the reasoning boundary, and substantially accelerates training convergence speed and efficiency. Experimental results demonstrate that our proposed Vision-EKIPL achieved up to a 5\% performance improvement on the Reason-RFT-CoT Benchmark compared to the state-of-the-art (SOTA). It reveals that Vision-EKIPL can overcome the limitations of traditional RL methods, significantly enhance the visual reasoning performance of MLLMs, and provide a new effective paradigm for research in this field.
Can Multimodal Large Language Models Understand Spatial Relations?
May 25, 2025Spatial relation reasoning is a crucial task for multimodal large language models (MLLMs) to understand the objective world. However, current benchmarks have issues like relying on bounding boxes, ignoring perspective substitutions, or allowing questions to be answered using only the model's prior knowledge without image understanding. To address these issues, we introduce SpatialMQA, a human-annotated spatial relation reasoning benchmark based on COCO2017, which enables MLLMs to focus more on understanding images in the objective world. To ensure data quality, we design a well-tailored annotation procedure, resulting in SpatialMQA consisting of 5,392 samples. Based on this benchmark, a series of closed- and open-source MLLMs are implemented and the results indicate that the current state-of-the-art MLLM achieves only 48.14% accuracy, far below the human-level accuracy of 98.40%. Extensive experimental analyses are also conducted, suggesting the future research directions. The benchmark and codes are available at https://github.com/ziyan-xiaoyu/SpatialMQA.git.
Graph-to-Vision: Multi-graph Understanding and Reasoning using Vision-Language Models
Mar 27, 2025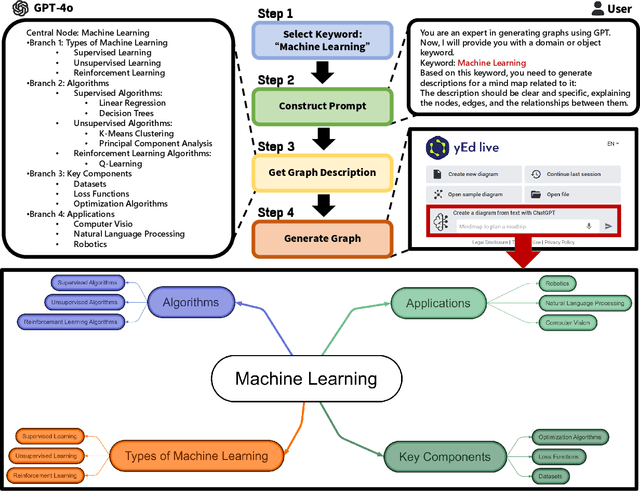
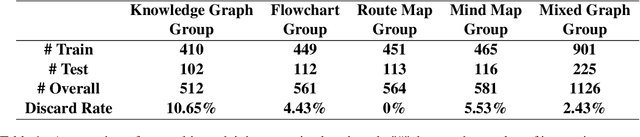
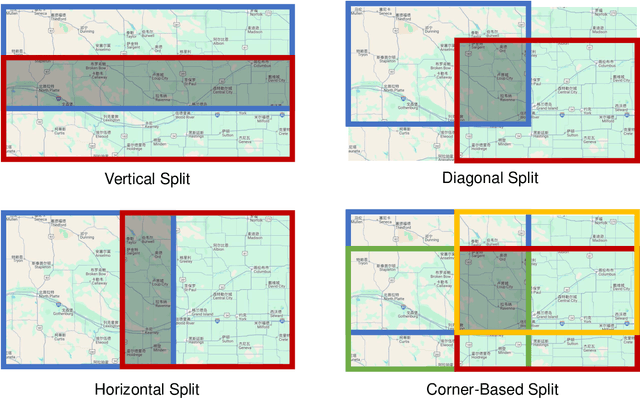
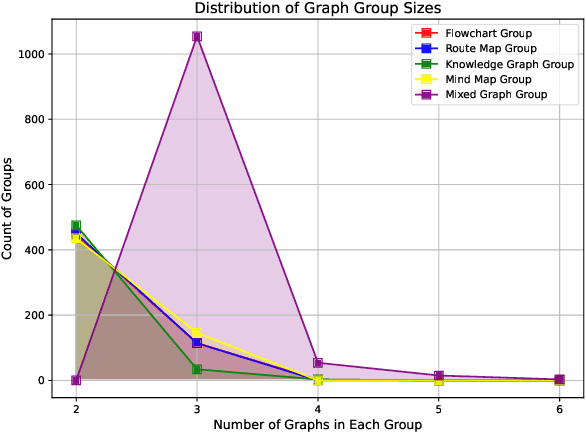
Graph Neural Networks (GNNs), as the dominant paradigm for graph-structured learning, have long faced dual challenges of exponentially escalating computational complexity and inadequate cross-scenario generalization capability. With the rapid advancement of multimodal learning, Vision-Language Models (VLMs) have demonstrated exceptional cross-modal relational reasoning capabilities and generalization capacities, thereby opening up novel pathways for overcoming the inherent limitations of conventional graph learning paradigms. However, current research predominantly concentrates on investigating the single-graph reasoning capabilities of VLMs, which fundamentally fails to address the critical requirement for coordinated reasoning across multiple heterogeneous graph data in real-world application scenarios. To address these limitations, we propose the first multi-graph joint reasoning benchmark for VLMs. Our benchmark encompasses four graph categories: knowledge graphs, flowcharts, mind maps, and route maps,with each graph group accompanied by three progressively challenging instruction-response pairs. Leveraging this benchmark, we conducted comprehensive capability assessments of state-of-the-art VLMs and performed fine-tuning on open-source models. This study not only addresses the underexplored evaluation gap in multi-graph reasoning for VLMs but also empirically validates their generalization superiority in graph-structured learning.
Empowering Users in Digital Privacy Management through Interactive LLM-Based Agents
Oct 15, 2024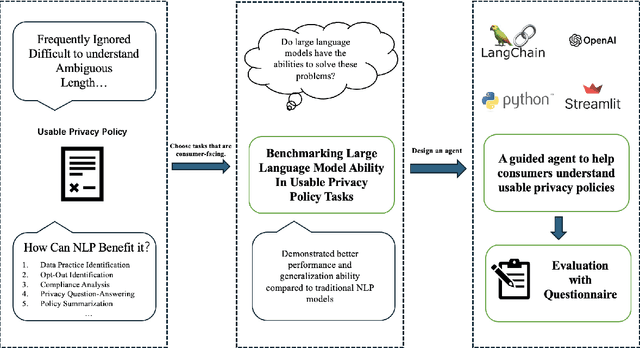
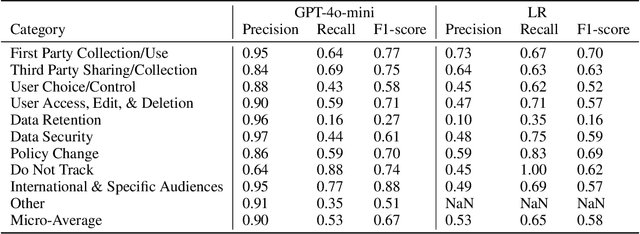
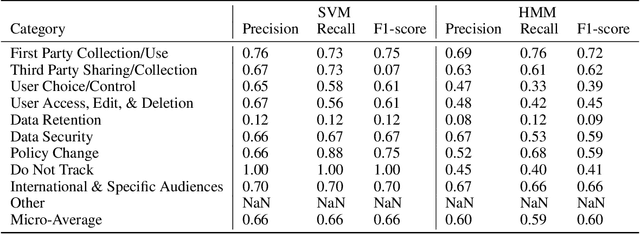
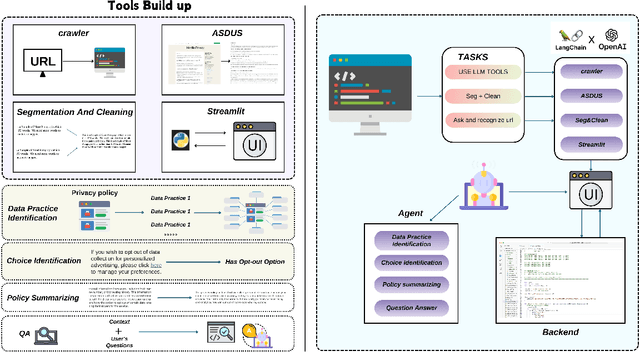
This paper presents a novel application of large language models (LLMs) to enhance user comprehension of privacy policies through an interactive dialogue agent. We demonstrate that LLMs significantly outperform traditional models in tasks like Data Practice Identification, Choice Identification, Policy Summarization, and Privacy Question Answering, setting new benchmarks in privacy policy analysis. Building on these findings, we introduce an innovative LLM-based agent that functions as an expert system for processing website privacy policies, guiding users through complex legal language without requiring them to pose specific questions. A user study with 100 participants showed that users assisted by the agent had higher comprehension levels (mean score of 2.6 out of 3 vs. 1.8 in the control group), reduced cognitive load (task difficulty ratings of 3.2 out of 10 vs. 7.8), increased confidence in managing privacy, and completed tasks in less time (5.5 minutes vs. 15.8 minutes). This work highlights the potential of LLM-based agents to transform user interaction with privacy policies, leading to more informed consent and empowering users in the digital services landscape.
GLBench: A Comprehensive Benchmark for Graph with Large Language Models
Jul 11, 2024



The emergence of large language models (LLMs) has revolutionized the way we interact with graphs, leading to a new paradigm called GraphLLM. Despite the rapid development of GraphLLM methods in recent years, the progress and understanding of this field remain unclear due to the lack of a benchmark with consistent experimental protocols. To bridge this gap, we introduce GLBench, the first comprehensive benchmark for evaluating GraphLLM methods in both supervised and zero-shot scenarios. GLBench provides a fair and thorough evaluation of different categories of GraphLLM methods, along with traditional baselines such as graph neural networks. Through extensive experiments on a collection of real-world datasets with consistent data processing and splitting strategies, we have uncovered several key findings. Firstly, GraphLLM methods outperform traditional baselines in supervised settings, with LLM-as-enhancers showing the most robust performance. However, using LLMs as predictors is less effective and often leads to uncontrollable output issues. We also notice that no clear scaling laws exist for current GraphLLM methods. In addition, both structures and semantics are crucial for effective zero-shot transfer, and our proposed simple baseline can even outperform several models tailored for zero-shot scenarios. The data and code of the benchmark can be found at https://github.com/NineAbyss/GLBench.
Sequence can Secretly Tell You What to Discard
Apr 24, 2024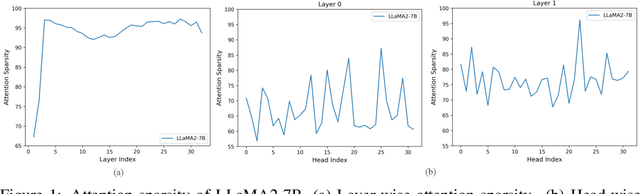
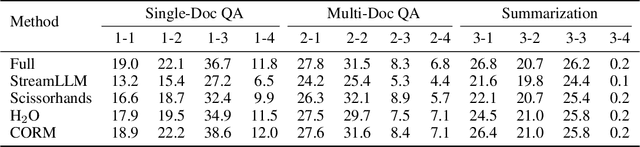
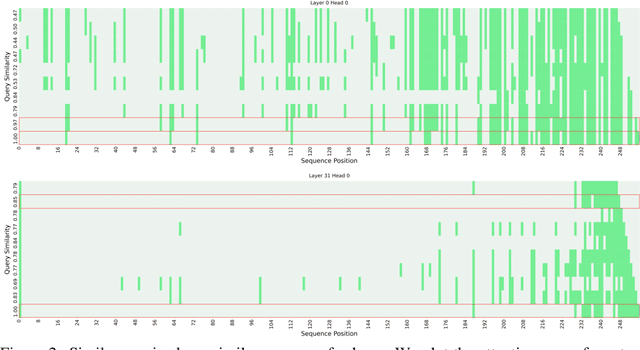
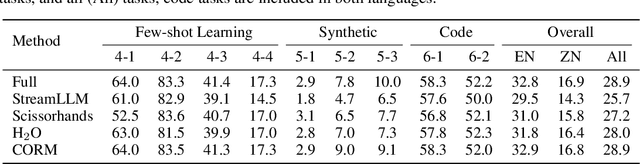
Large Language Models (LLMs), despite their impressive performance on a wide range of tasks, require significant GPU memory and consume substantial computational resources. In addition to model weights, the memory occupied by KV cache increases linearly with sequence length, becoming a main bottleneck for inference. In this paper, we introduce a novel approach for optimizing the KV cache which significantly reduces its memory footprint. Through a comprehensive investigation, we find that on LLaMA2 series models, (i) the similarity between adjacent tokens' query vectors is remarkably high, and (ii) current query's attention calculation can rely solely on the attention information of a small portion of the preceding queries. Based on these observations, we propose CORM, a KV cache eviction policy that dynamically retains important key-value pairs for inference without finetuning the model. We validate that CORM reduces the inference memory usage of KV cache by up to 70% without noticeable performance degradation across six tasks in LongBench.
MIKE: A New Benchmark for Fine-grained Multimodal Entity Knowledge Editing
Feb 18, 2024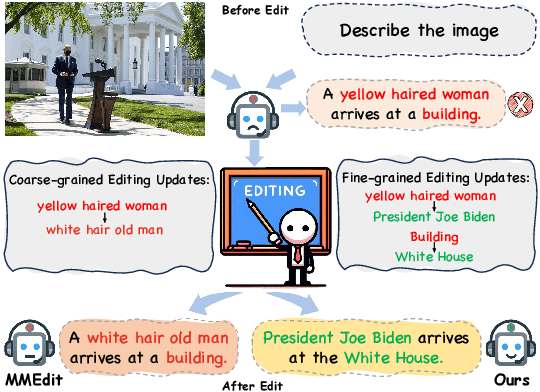
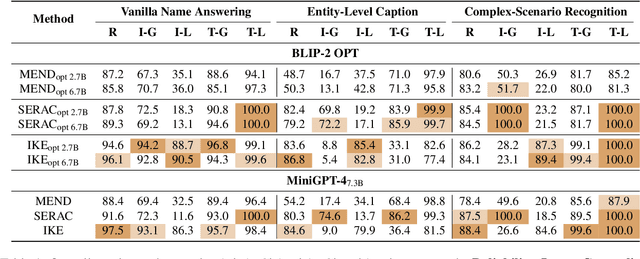

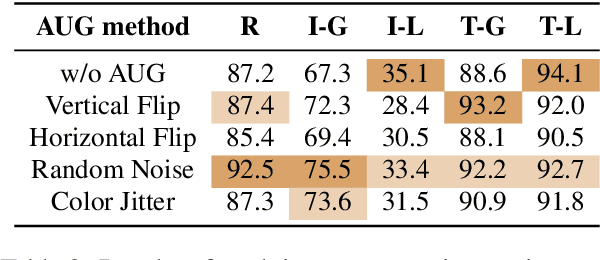
Multimodal knowledge editing represents a critical advancement in enhancing the capabilities of Multimodal Large Language Models (MLLMs). Despite its potential, current benchmarks predominantly focus on coarse-grained knowledge, leaving the intricacies of fine-grained (FG) multimodal entity knowledge largely unexplored. This gap presents a notable challenge, as FG entity recognition is pivotal for the practical deployment and effectiveness of MLLMs in diverse real-world scenarios. To bridge this gap, we introduce MIKE, a comprehensive benchmark and dataset specifically designed for the FG multimodal entity knowledge editing. MIKE encompasses a suite of tasks tailored to assess different perspectives, including Vanilla Name Answering, Entity-Level Caption, and Complex-Scenario Recognition. In addition, a new form of knowledge editing, Multi-step Editing, is introduced to evaluate the editing efficiency. Through our extensive evaluations, we demonstrate that the current state-of-the-art methods face significant challenges in tackling our proposed benchmark, underscoring the complexity of FG knowledge editing in MLLMs. Our findings spotlight the urgent need for novel approaches in this domain, setting a clear agenda for future research and development efforts within the community.