 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAutoIQ: An Ensemble Framework for Automatic Assessment of Geometric Distortion in Prostate Diffusion-Weighted Imaging
May 29, 2026Geometric distortion in prostate diffusion-weighted imaging (DWI) can impair lesion localization and reduce the reliability of MRI-based clinical assessment. We propose AutoIQ, an ensemble machine learning framework for automatic quantification and classification of DWI geometric distortion severity. A total of 140 retrospective prostate biparametric MRI examinations were analyzed, including 33 scans with severe distortion requiring repeat acquisition and 107 scans with acceptable distortion based on expert radiologist assessment. AutoIQ combines two complementary distortion quantification strategies: a segmentation-based method measuring prostate boundary mismatch between T2-weighted imaging (T2WI) and DWI, and a registration-based method estimating deformation magnitude after DWI-to-T2WI alignment. The resulting distortion scores were used to train individual classifiers and a logistic-regression ensemble model. Both computational methods significantly differentiated severe from acceptable distortion cases (p < 0.001). On an independent test set, the ensemble model achieved an accuracy of 0.95, F1-score of 0.93, and AUC of 0.98, outperforming individual models. These results suggest that AutoIQ can provide automated, quantitative quality assessment for prostate DWI and may help identify scans that require repeat acquisition.
Efficient LLM-based Advertising via Model Compression and Parallel Verification
May 12, 2026Large language models (LLMs) have shown remarkable potential in advertising scenarios such as ad creative generation and targeted advertising. However, deploying LLMs in real-time advertising systems poses significant challenges due to their high inference latency and computational cost. In this paper, we propose an Efficient Generative Targeting framework that integrates adaptive group quantization, layer-adaptive hierarchical sparsification, and prefix-tree parallel verification to accelerate LLM inference while preserving generation quality. Extensive experiments on two real-world advertising scenarios demonstrate that our framework achieves significant speedup with acceptable quality degradation, making it operationally viable for practical deployments.
HopChain: Multi-Hop Data Synthesis for Generalizable Vision-Language Reasoning
Mar 19, 2026Vision-language models (VLMs) show strong multimodal capabilities but still struggle with fine-grained vision-language reasoning. We find that long chain-of-thought (CoT) reasoning exposes diverse failure modes, including perception, reasoning, knowledge, and hallucination errors, which can compound across intermediate steps. However, most existing vision-language data used for reinforcement learning with verifiable rewards (RLVR) does not involve complex reasoning chains that rely on visual evidence throughout, leaving these weaknesses largely unexposed. We therefore propose HopChain, a scalable framework for synthesizing multi-hop vision-language reasoning data for RLVR training of VLMs. Each synthesized multi-hop query forms a logically dependent chain of instance-grounded hops, where earlier hops establish the instances, sets, or conditions needed for later hops, while the final answer remains a specific, unambiguous number suitable for verifiable rewards. We train Qwen3.5-35B-A3B and Qwen3.5-397B-A17B under two RLVR settings: the original data alone, and the original data plus HopChain's multi-hop data, and compare them across 24 benchmarks spanning STEM and Puzzle, General VQA, Text Recognition and Document Understanding, and Video Understanding. Although this multi-hop data is not synthesized for any specific benchmark, it improves 20 of 24 benchmarks on both models, indicating broad and generalizable gains. Consistently, replacing full chained queries with half-multi-hop or single-hop variants reduces the average score across five representative benchmarks from 70.4 to 66.7 and 64.3, respectively. Notably, multi-hop gains peak in long-CoT vision-language reasoning, exceeding 50 points in the ultra-long-CoT regime. These experiments establish HopChain as an effective, scalable framework for synthesizing multi-hop data that improves generalizable vision-language reasoning.
Revealing Behavioral Plasticity in Large Language Models: A Token-Conditional Perspective
Mar 09, 2026In this work, we reveal that Large Language Models (LLMs) possess intrinsic behavioral plasticity-akin to chameleons adapting their coloration to environmental cues-that can be exposed through token-conditional generation and stabilized via reinforcement learning. Specifically, by conditioning generation on carefully selected token prefixes sampled from responses exhibiting desired behaviors, LLMs seamlessly adapt their behavioral modes at inference time (e.g., switching from step-by-step reasoning to direct answering) without retraining. Based on this insight, we propose Token-Conditioned Reinforcement Learning (ToCoRL), a principled framework that leverages RL to internalize this chameleon-like plasticity, transforming transient inference-time adaptations into stable and learnable behavioral patterns. ToCoRL guides exploration with token-conditional generation and keep enhancing exploitation, enabling emergence of appropriate behaviors. Extensive experiments show that ToCoRL enables precise behavioral control without capability degradation. Notably, we show that large reasoning models, while performing strongly on complex mathematics, can be effectively adapted to excel at factual question answering, which was a capability previously hindered by their step-by-step reasoning patterns.
Outcome Accuracy is Not Enough: Aligning the Reasoning Process of Reward Models
Feb 04, 2026Generative Reward Models (GenRMs) and LLM-as-a-Judge exhibit deceptive alignment by producing correct judgments for incorrect reasons, as they are trained and evaluated to prioritize Outcome Accuracy, which undermines their ability to generalize during RLHF. We introduce Rationale Consistency, a fine-grained metric that quantifies the alignment between the model's reasoning process and human judgment. Our evaluation of frontier models reveals that rationale consistency effectively discriminates among state-of-the-art models and detects deceptive alignment, while outcome accuracy falls short in both respects. To mitigate this gap, we introduce a hybrid signal that combines rationale consistency with outcome accuracy for GenRM training. Our training method achieves state-of-the-art performance on RM-Bench (87.1%) and JudgeBench (82%), surpassing outcome-only baselines by an average of 5%. Using RM during RLHF, our method effectively improves performance as demonstrated on Arena Hard v2, notably yielding a 7% improvement in creative writing tasks. Further analysis confirms that our method escapes the deceptive alignment trap, effectively reversing the decline in rationale consistency observed in outcome-only training.
Learning Neural Operators from Partial Observations via Latent Autoregressive Modeling
Jan 27, 2026Real-world scientific applications frequently encounter incomplete observational data due to sensor limitations, geographic constraints, or measurement costs. Although neural operators significantly advanced PDE solving in terms of computational efficiency and accuracy, their underlying assumption of fully-observed spatial inputs severely restricts applicability in real-world applications. We introduce the first systematic framework for learning neural operators from partial observation. We identify and formalize two fundamental obstacles: (i) the supervision gap in unobserved regions that prevents effective learning of physical correlations, and (ii) the dynamic spatial mismatch between incomplete inputs and complete solution fields. Specifically, our proposed Latent Autoregressive Neural Operator(LANO) introduces two novel components designed explicitly to address the core difficulties of partial observations: (i) a mask-to-predict training strategy that creates artificial supervision by strategically masking observed regions, and (ii) a Physics-Aware Latent Propagator that reconstructs solutions through boundary-first autoregressive generation in latent space. Additionally, we develop POBench-PDE, a dedicated and comprehensive benchmark designed specifically for evaluating neural operators under partial observation conditions across three PDE-governed tasks. LANO achieves state-of-the-art performance with 18--69$\%$ relative L2 error reduction across all benchmarks under patch-wise missingness with less than 50$\%$ missing rate, including real-world climate prediction. Our approach effectively addresses practical scenarios involving up to 75$\%$ missing rate, to some extent bridging the existing gap between idealized research settings and the complexities of real-world scientific computing.
Neural-HAR: A Dimension-Gated CNN Accelerator for Real-Time Radar Human Activity Recognition
Oct 26, 2025Radar-based human activity recognition (HAR) is attractive for unobtrusive and privacy-preserving monitoring, yet many CNN/RNN solutions remain too heavy for edge deployment, and even lightweight ViT/SSM variants often exceed practical compute and memory budgets. We introduce Neural-HAR, a dimension-gated CNN accelerator tailored for real-time radar HAR on resource-constrained platforms. At its core is GateCNN, a parameter-efficient Doppler-temporal network that (i) embeds Doppler vectors to emphasize frequency evolution over time and (ii) applies dual-path gated convolutions that modulate Doppler-aware content features with temporal gates, complemented by a residual path for stable training. On the University of Glasgow UoG2020 continuous radar dataset, GateCNN attains 86.4% accuracy with only 2.7k parameters and 0.28M FLOPs per inference, comparable to CNN-BiGRU at a fraction of the complexity. Our FPGA prototype on Xilinx Zynq-7000 Z-7007S reaches 107.5 $\mu$s latency and 15 mW dynamic power using LUT-based ROM and distributed RAM only (zero DSP/BRAM), demonstrating real-time, energy-efficient edge inference. Code and HLS conversion scripts are available at https://github.com/lab-emi/AIRHAR.
MANZANO: A Simple and Scalable Unified Multimodal Model with a Hybrid Vision Tokenizer
Sep 19, 2025
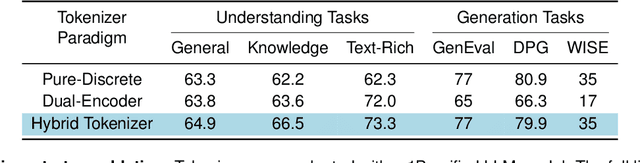
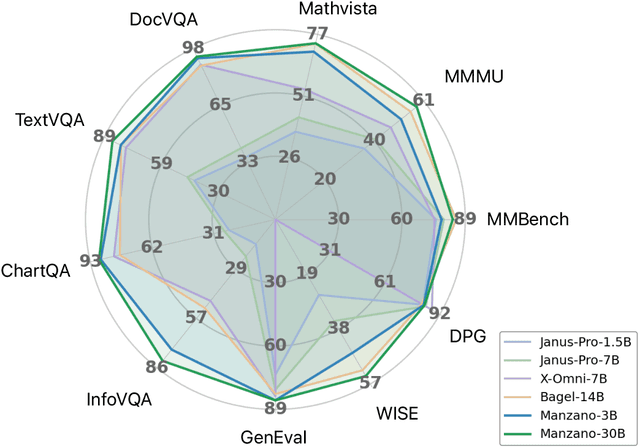
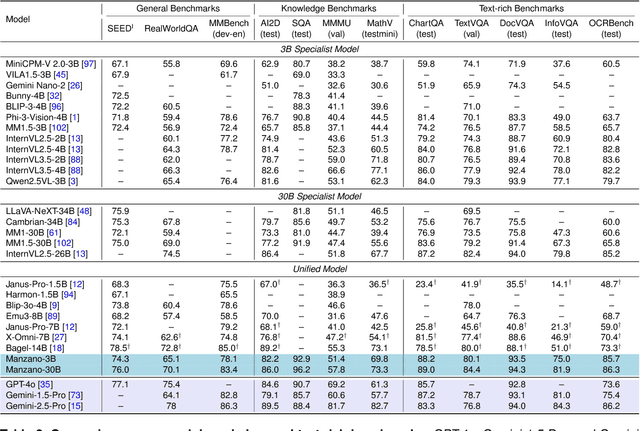
Unified multimodal Large Language Models (LLMs) that can both understand and generate visual content hold immense potential. However, existing open-source models often suffer from a performance trade-off between these capabilities. We present Manzano, a simple and scalable unified framework that substantially reduces this tension by coupling a hybrid image tokenizer with a well-curated training recipe. A single shared vision encoder feeds two lightweight adapters that produce continuous embeddings for image-to-text understanding and discrete tokens for text-to-image generation within a common semantic space. A unified autoregressive LLM predicts high-level semantics in the form of text and image tokens, with an auxiliary diffusion decoder subsequently translating the image tokens into pixels. The architecture, together with a unified training recipe over understanding and generation data, enables scalable joint learning of both capabilities. Manzano achieves state-of-the-art results among unified models, and is competitive with specialist models, particularly on text-rich evaluation. Our studies show minimal task conflicts and consistent gains from scaling model size, validating our design choice of a hybrid tokenizer.
EvHand-FPV: Efficient Event-Based 3D Hand Tracking from First-Person View
Sep 17, 2025Hand tracking holds great promise for intuitive interaction paradigms, but frame-based methods often struggle to meet the requirements of accuracy, low latency, and energy efficiency, especially in resource-constrained settings such as Extended Reality (XR) devices. Event cameras provide $\mu$s-level temporal resolution at mW-level power by asynchronously sensing brightness changes. In this work, we present EvHand-FPV, a lightweight framework for egocentric First-Person-View 3D hand tracking from a single event camera. We construct an event-based FPV dataset that couples synthetic training data with 3D labels and real event data with 2D labels for evaluation to address the scarcity of egocentric benchmarks. EvHand-FPV also introduces a wrist-based region of interest (ROI) that localizes the hand region via geometric cues, combined with an end-to-end mapping strategy that embeds ROI offsets into the network to reduce computation without explicit reconstruction, and a multi-task learning strategy with an auxiliary geometric feature head that improves representations without test-time overhead. On our real FPV test set, EvHand-FPV improves 2D-AUCp from 0.77 to 0.85 while reducing parameters from 11.2M to 1.2M by 89% and FLOPs per inference from 1.648G to 0.185G by 89%. It also maintains a competitive 3D-AUCp of 0.84 on synthetic data. These results demonstrate accurate and efficient egocentric event-based hand tracking suitable for on-device XR applications. The dataset and code are available at https://github.com/zen5x5/EvHand-FPV.
Group Sequence Policy Optimization
Jul 24, 2025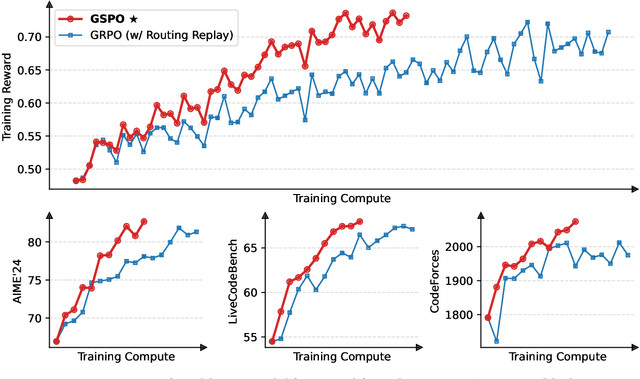
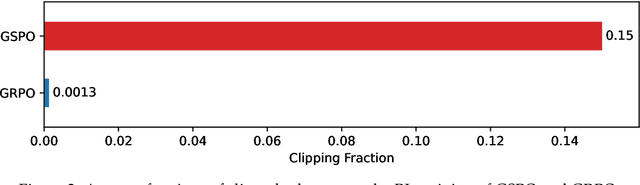
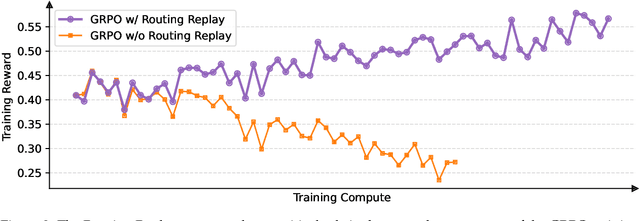
This paper introduces Group Sequence Policy Optimization (GSPO), our stable, efficient, and performant reinforcement learning algorithm for training large language models. Unlike previous algorithms that adopt token-level importance ratios, GSPO defines the importance ratio based on sequence likelihood and performs sequence-level clipping, rewarding, and optimization. We demonstrate that GSPO achieves superior training efficiency and performance compared to the GRPO algorithm, notably stabilizes Mixture-of-Experts (MoE) RL training, and has the potential for simplifying the design of RL infrastructure. These merits of GSPO have contributed to the remarkable improvements in the latest Qwen3 models.