 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAS-ASR: A Lightweight Framework for Aphasia-Specific Automatic Speech Recognition
Jun 06, 2025This paper proposes AS-ASR, a lightweight aphasia-specific speech recognition framework based on Whisper-tiny, tailored for low-resource deployment on edge devices. Our approach introduces a hybrid training strategy that systematically combines standard and aphasic speech at varying ratios, enabling robust generalization, and a GPT-4-based reference enhancement method that refines noisy aphasic transcripts, improving supervision quality. We conduct extensive experiments across multiple data mixing configurations and evaluation settings. Results show that our fine-tuned model significantly outperforms the zero-shot baseline, reducing WER on aphasic speech by over 30% while preserving performance on standard speech. The proposed framework offers a scalable, efficient solution for real-world disordered speech recognition.
HandsOnVLM: Vision-Language Models for Hand-Object Interaction Prediction
Dec 17, 2024



How can we predict future interaction trajectories of human hands in a scene given high-level colloquial task specifications in the form of natural language? In this paper, we extend the classic hand trajectory prediction task to two tasks involving explicit or implicit language queries. Our proposed tasks require extensive understanding of human daily activities and reasoning abilities about what should be happening next given cues from the current scene. We also develop new benchmarks to evaluate the proposed two tasks, Vanilla Hand Prediction (VHP) and Reasoning-Based Hand Prediction (RBHP). We enable solving these tasks by integrating high-level world knowledge and reasoning capabilities of Vision-Language Models (VLMs) with the auto-regressive nature of low-level ego-centric hand trajectories. Our model, HandsOnVLM is a novel VLM that can generate textual responses and produce future hand trajectories through natural-language conversations. Our experiments show that HandsOnVLM outperforms existing task-specific methods and other VLM baselines on proposed tasks, and demonstrates its ability to effectively utilize world knowledge for reasoning about low-level human hand trajectories based on the provided context. Our website contains code and detailed video results \url{https://www.chenbao.tech/handsonvlm/}
ManiSkill3: GPU Parallelized Robotics Simulation and Rendering for Generalizable Embodied AI
Oct 01, 2024



Simulation has enabled unprecedented compute-scalable approaches to robot learning. However, many existing simulation frameworks typically support a narrow range of scenes/tasks and lack features critical for scaling generalizable robotics and sim2real. We introduce and open source ManiSkill3, the fastest state-visual GPU parallelized robotics simulator with contact-rich physics targeting generalizable manipulation. ManiSkill3 supports GPU parallelization of many aspects including simulation+rendering, heterogeneous simulation, pointclouds/voxels visual input, and more. Simulation with rendering on ManiSkill3 can run 10-1000x faster with 2-3x less GPU memory usage than other platforms, achieving up to 30,000+ FPS in benchmarked environments due to minimal python/pytorch overhead in the system, simulation on the GPU, and the use of the SAPIEN parallel rendering system. Tasks that used to take hours to train can now take minutes. We further provide the most comprehensive range of GPU parallelized environments/tasks spanning 12 distinct domains including but not limited to mobile manipulation for tasks such as drawing, humanoids, and dextrous manipulation in realistic scenes designed by artists or real-world digital twins. In addition, millions of demonstration frames are provided from motion planning, RL, and teleoperation. ManiSkill3 also provides a comprehensive set of baselines that span popular RL and learning-from-demonstrations algorithms.
GenSim: Generating Robotic Simulation Tasks via Large Language Models
Oct 02, 2023

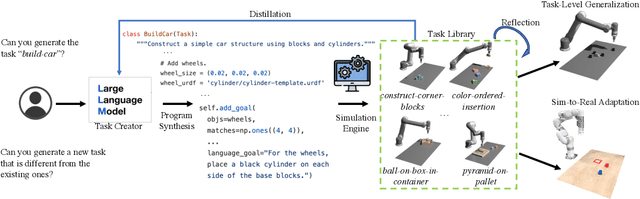
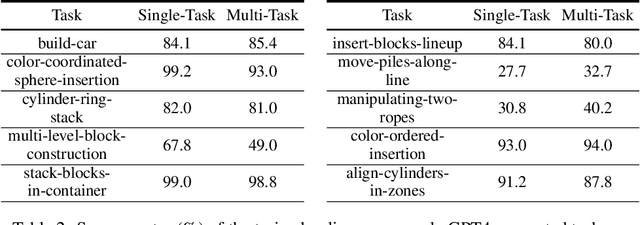
Collecting large amounts of real-world interaction data to train general robotic policies is often prohibitively expensive, thus motivating the use of simulation data. However, existing methods for data generation have generally focused on scene-level diversity (e.g., object instances and poses) rather than task-level diversity, due to the human effort required to come up with and verify novel tasks. This has made it challenging for policies trained on simulation data to demonstrate significant task-level generalization. In this paper, we propose to automatically generate rich simulation environments and expert demonstrations by exploiting a large language models' (LLM) grounding and coding ability. Our approach, dubbed GenSim, has two modes: goal-directed generation, wherein a target task is given to the LLM and the LLM proposes a task curriculum to solve the target task, and exploratory generation, wherein the LLM bootstraps from previous tasks and iteratively proposes novel tasks that would be helpful in solving more complex tasks. We use GPT4 to expand the existing benchmark by ten times to over 100 tasks, on which we conduct supervised finetuning and evaluate several LLMs including finetuned GPTs and Code Llama on code generation for robotic simulation tasks. Furthermore, we observe that LLMs-generated simulation programs can enhance task-level generalization significantly when used for multitask policy training. We further find that with minimal sim-to-real adaptation, the multitask policies pretrained on GPT4-generated simulation tasks exhibit stronger transfer to unseen long-horizon tasks in the real world and outperform baselines by 25%. See the project website (https://liruiw.github.io/gensim) for code, demos, and videos.
DexArt: Benchmarking Generalizable Dexterous Manipulation with Articulated Objects
May 09, 2023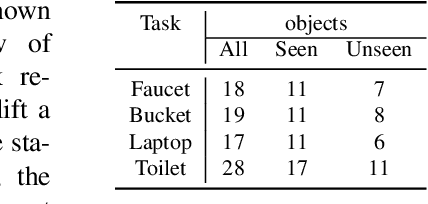



To enable general-purpose robots, we will require the robot to operate daily articulated objects as humans do. Current robot manipulation has heavily relied on using a parallel gripper, which restricts the robot to a limited set of objects. On the other hand, operating with a multi-finger robot hand will allow better approximation to human behavior and enable the robot to operate on diverse articulated objects. To this end, we propose a new benchmark called DexArt, which involves Dexterous manipulation with Articulated objects in a physical simulator. In our benchmark, we define multiple complex manipulation tasks, and the robot hand will need to manipulate diverse articulated objects within each task. Our main focus is to evaluate the generalizability of the learned policy on unseen articulated objects. This is very challenging given the high degrees of freedom of both hands and objects. We use Reinforcement Learning with 3D representation learning to achieve generalization. Through extensive studies, we provide new insights into how 3D representation learning affects decision making in RL with 3D point cloud inputs. More details can be found at https://www.chenbao.tech/dexart/.
MMFL-Net: Multi-scale and Multi-granularity Feature Learning for Cross-domain Fashion Retrieval
Oct 27, 2022Instance-level image retrieval in fashion is a challenging issue owing to its increasing importance in real-scenario visual fashion search. Cross-domain fashion retrieval aims to match the unconstrained customer images as queries for photographs provided by retailers; however, it is a difficult task due to a wide range of consumer-to-shop (C2S) domain discrepancies and also considering that clothing image is vulnerable to various non-rigid deformations. To this end, we propose a novel multi-scale and multi-granularity feature learning network (MMFL-Net), which can jointly learn global-local aggregation feature representations of clothing images in a unified framework, aiming to train a cross-domain model for C2S fashion visual similarity. First, a new semantic-spatial feature fusion part is designed to bridge the semantic-spatial gap by applying top-down and bottom-up bidirectional multi-scale feature fusion. Next, a multi-branch deep network architecture is introduced to capture global salient, part-informed, and local detailed information, and extracting robust and discrimination feature embedding by integrating the similarity learning of coarse-to-fine embedding with the multiple granularities. Finally, the improved trihard loss, center loss, and multi-task classification loss are adopted for our MMFL-Net, which can jointly optimize intra-class and inter-class distance and thus explicitly improve intra-class compactness and inter-class discriminability between its visual representations for feature learning. Furthermore, our proposed model also combines the multi-task attribute recognition and classification module with multi-label semantic attributes and product ID labels. Experimental results demonstrate that our proposed MMFL-Net achieves significant improvement over the state-of-the-art methods on the two datasets, DeepFashion-C2S and Street2Shop.
* 27 pages, 12 figures, Published by <Multimedia Tools and Applications>