 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAnyHand: A Large-Scale Synthetic Dataset for RGB(-D) Hand Pose Estimation
Mar 26, 2026We present AnyHand, a large-scale synthetic dataset designed to advance the state of the art in 3D hand pose estimation from both RGB-only and RGB-D inputs. While recent works with foundation approaches have shown that an increase in the quantity and diversity of training data can markedly improve performance and robustness in hand pose estimation, existing real-world-collected datasets on this task are limited in coverage, and prior synthetic datasets rarely provide occlusions, arm details, and aligned depth together at scale. To address this bottleneck, our AnyHand contains 2.5M single-hand and 4.1M hand-object interaction RGB-D images, with rich geometric annotations. In the RGB-only setting, we show that extending the original training sets of existing baselines with AnyHand yields significant gains on multiple benchmarks (FreiHAND and HO-3D), even when keeping the architecture and training scheme fixed. More impressively, the model trained with AnyHand shows stronger generalization to the out-of-domain HO-Cap dataset, without any fine-tuning. We also contribute a lightweight depth fusion module that can be easily integrated into existing RGB-based models. Trained with AnyHand, the resulting RGB-D model achieves superior performance on the HO-3D benchmark, showing the benefits of depth integration and the effectiveness of our synthetic data.
UI-Venus-1.5 Technical Report
Feb 09, 2026GUI agents have emerged as a powerful paradigm for automating interactions in digital environments, yet achieving both broad generality and consistently strong task performance remains challenging.In this report, we present UI-Venus-1.5, a unified, end-to-end GUI Agent designed for robust real-world applications.The proposed model family comprises two dense variants (2B and 8B) and one mixture-of-experts variant (30B-A3B) to meet various downstream application scenarios.Compared to our previous version, UI-Venus-1.5 introduces three key technical advances: (1) a comprehensive Mid-Training stage leveraging 10 billion tokens across 30+ datasets to establish foundational GUI semantics; (2) Online Reinforcement Learning with full-trajectory rollouts, aligning training objectives with long-horizon, dynamic navigation in large-scale environments; and (3) a single unified GUI Agent constructed via Model Merging, which synthesizes domain-specific models (grounding, web, and mobile) into one cohesive checkpoint. Extensive evaluations demonstrate that UI-Venus-1.5 establishes new state-of-the-art performance on benchmarks such as ScreenSpot-Pro (69.6%), VenusBench-GD (75.0%), and AndroidWorld (77.6%), significantly outperforming previous strong baselines. In addition, UI-Venus-1.5 demonstrates robust navigation capabilities across a variety of Chinese mobile apps, effectively executing user instructions in real-world scenarios. Code: https://github.com/inclusionAI/UI-Venus; Model: https://huggingface.co/collections/inclusionAI/ui-venus
Integrated Sensing and Communication: Towards Multifunctional Perceptive Network
Oct 16, 2025The capacity-maximization design philosophy has driven the growth of wireless networks for decades. However, with the slowdown in recent data traffic demand, the mobile industry can no longer rely solely on communication services to sustain development. In response, Integrated Sensing and Communications (ISAC) has emerged as a transformative solution, embedding sensing capabilities into communication networks to enable multifunctional wireless systems. This paradigm shift expands the role of networks from sole data transmission to versatile platforms supporting diverse applications. In this review, we provide a bird's-eye view of ISAC for new researchers, highlighting key challenges, opportunities, and application scenarios to guide future exploration in this field.
Learning Adaptive Dexterous Grasping from Single Demonstrations
Mar 26, 2025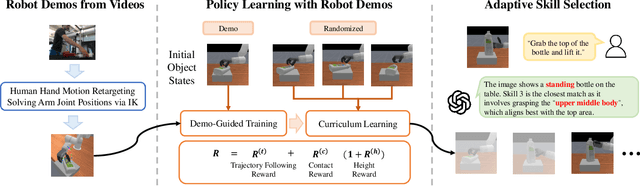

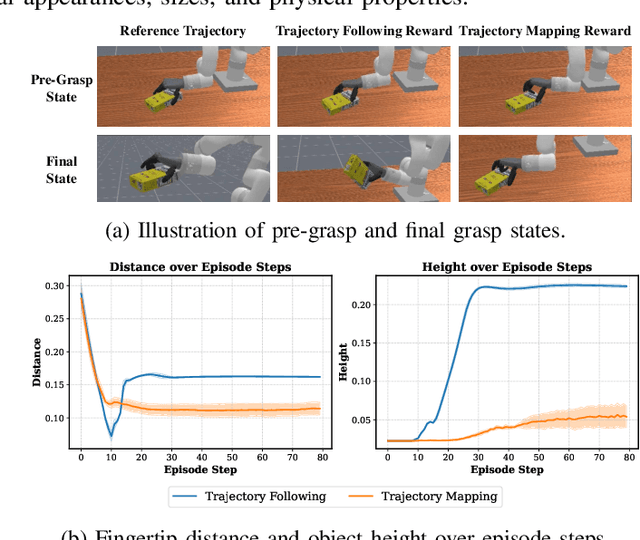
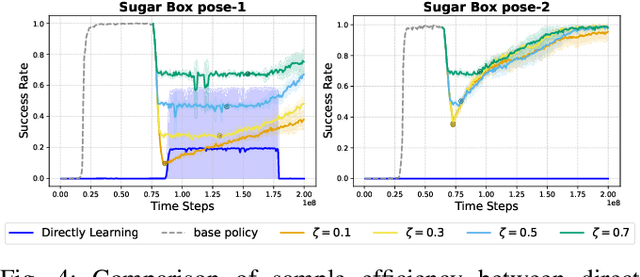
How can robots learn dexterous grasping skills efficiently and apply them adaptively based on user instructions? This work tackles two key challenges: efficient skill acquisition from limited human demonstrations and context-driven skill selection. We introduce AdaDexGrasp, a framework that learns a library of grasping skills from a single human demonstration per skill and selects the most suitable one using a vision-language model (VLM). To improve sample efficiency, we propose a trajectory following reward that guides reinforcement learning (RL) toward states close to a human demonstration while allowing flexibility in exploration. To learn beyond the single demonstration, we employ curriculum learning, progressively increasing object pose variations to enhance robustness. At deployment, a VLM retrieves the appropriate skill based on user instructions, bridging low-level learned skills with high-level intent. We evaluate AdaDexGrasp in both simulation and real-world settings, showing that our approach significantly improves RL efficiency and enables learning human-like grasp strategies across varied object configurations. Finally, we demonstrate zero-shot transfer of our learned policies to a real-world PSYONIC Ability Hand, with a 90% success rate across objects, significantly outperforming the baseline.
3D-Adapter: Geometry-Consistent Multi-View Diffusion for High-Quality 3D Generation
Oct 24, 2024
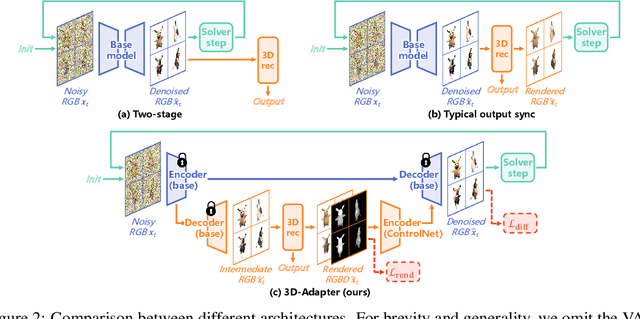
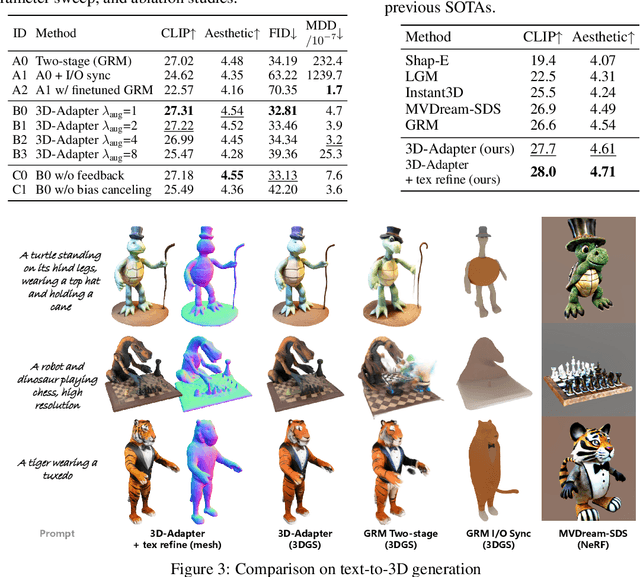
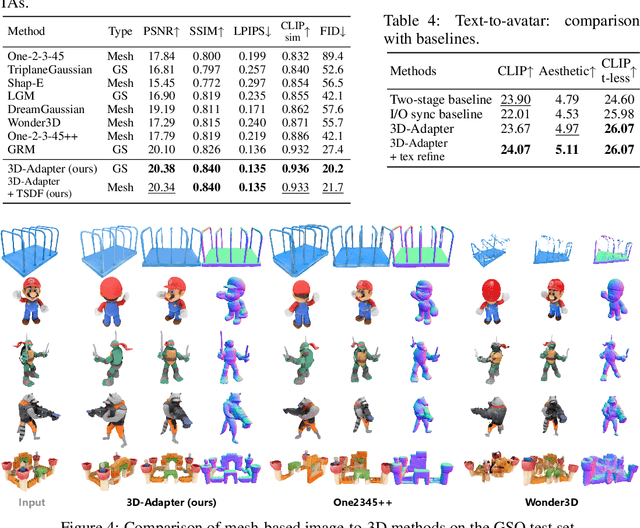
Multi-view image diffusion models have significantly advanced open-domain 3D object generation. However, most existing models rely on 2D network architectures that lack inherent 3D biases, resulting in compromised geometric consistency. To address this challenge, we introduce 3D-Adapter, a plug-in module designed to infuse 3D geometry awareness into pretrained image diffusion models. Central to our approach is the idea of 3D feedback augmentation: for each denoising step in the sampling loop, 3D-Adapter decodes intermediate multi-view features into a coherent 3D representation, then re-encodes the rendered RGBD views to augment the pretrained base model through feature addition. We study two variants of 3D-Adapter: a fast feed-forward version based on Gaussian splatting and a versatile training-free version utilizing neural fields and meshes. Our extensive experiments demonstrate that 3D-Adapter not only greatly enhances the geometry quality of text-to-multi-view models such as Instant3D and Zero123++, but also enables high-quality 3D generation using the plain text-to-image Stable Diffusion. Furthermore, we showcase the broad application potential of 3D-Adapter by presenting high quality results in text-to-3D, image-to-3D, text-to-texture, and text-to-avatar tasks.
ManiSkill3: GPU Parallelized Robotics Simulation and Rendering for Generalizable Embodied AI
Oct 01, 2024



Simulation has enabled unprecedented compute-scalable approaches to robot learning. However, many existing simulation frameworks typically support a narrow range of scenes/tasks and lack features critical for scaling generalizable robotics and sim2real. We introduce and open source ManiSkill3, the fastest state-visual GPU parallelized robotics simulator with contact-rich physics targeting generalizable manipulation. ManiSkill3 supports GPU parallelization of many aspects including simulation+rendering, heterogeneous simulation, pointclouds/voxels visual input, and more. Simulation with rendering on ManiSkill3 can run 10-1000x faster with 2-3x less GPU memory usage than other platforms, achieving up to 30,000+ FPS in benchmarked environments due to minimal python/pytorch overhead in the system, simulation on the GPU, and the use of the SAPIEN parallel rendering system. Tasks that used to take hours to train can now take minutes. We further provide the most comprehensive range of GPU parallelized environments/tasks spanning 12 distinct domains including but not limited to mobile manipulation for tasks such as drawing, humanoids, and dextrous manipulation in realistic scenes designed by artists or real-world digital twins. In addition, millions of demonstration frames are provided from motion planning, RL, and teleoperation. ManiSkill3 also provides a comprehensive set of baselines that span popular RL and learning-from-demonstrations algorithms.
SpaRP: Fast 3D Object Reconstruction and Pose Estimation from Sparse Views
Aug 19, 2024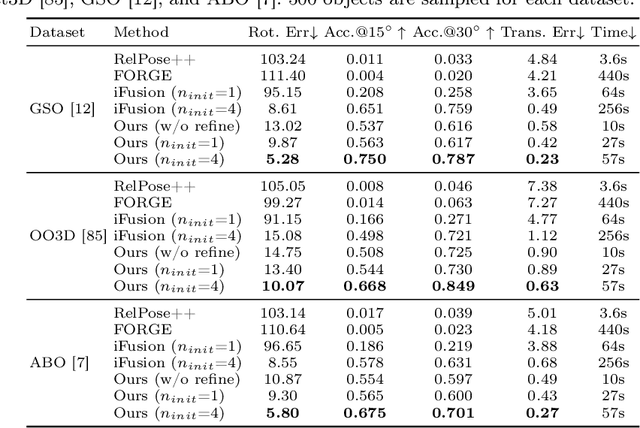

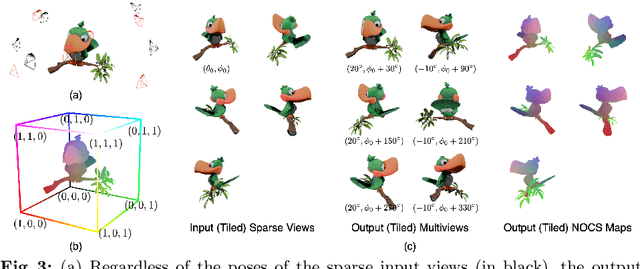

Open-world 3D generation has recently attracted considerable attention. While many single-image-to-3D methods have yielded visually appealing outcomes, they often lack sufficient controllability and tend to produce hallucinated regions that may not align with users' expectations. In this paper, we explore an important scenario in which the input consists of one or a few unposed 2D images of a single object, with little or no overlap. We propose a novel method, SpaRP, to reconstruct a 3D textured mesh and estimate the relative camera poses for these sparse-view images. SpaRP distills knowledge from 2D diffusion models and finetunes them to implicitly deduce the 3D spatial relationships between the sparse views. The diffusion model is trained to jointly predict surrogate representations for camera poses and multi-view images of the object under known poses, integrating all information from the input sparse views. These predictions are then leveraged to accomplish 3D reconstruction and pose estimation, and the reconstructed 3D model can be used to further refine the camera poses of input views. Through extensive experiments on three datasets, we demonstrate that our method not only significantly outperforms baseline methods in terms of 3D reconstruction quality and pose prediction accuracy but also exhibits strong efficiency. It requires only about 20 seconds to produce a textured mesh and camera poses for the input views. Project page: https://chaoxu.xyz/sparp.
Mining the Explainability and Generalization: Fact Verification Based on Self-Instruction
May 23, 2024Fact-checking based on commercial LLMs has become mainstream. Although these methods offer high explainability, it falls short in accuracy compared to traditional fine-tuning approaches, and data security is also a significant concern. In this paper, we propose a self-instruction based fine-tuning approach for fact-checking that balances accuracy and explainability. Our method consists of Data Augmentation and Improved DPO fine-tuning. The former starts by instructing the model to generate both positive and negative explanations based on claim-evidence pairs and labels, then sampling the dataset according to our customized difficulty standards. The latter employs our proposed improved DPO to fine-tune the model using the generated samples. We fine-tune the smallest-scale LLaMA-7B model and evaluate it on the challenging fact-checking datasets FEVEROUS and HOVER, utilizing four fine-tuning methods and three few-shot learning methods for comparison. The experiments demonstrate that our approach not only retains accuracy comparable to, or even surpassing, traditional fine-tuning methods, but also generates fluent explanation text. Moreover, it also exhibit high generalization performance. Our method is the first to leverage self-supervised learning for fact-checking and innovatively combines contrastive learning and improved DPO in fine-tuning LLMs, as shown in the experiments.
Generic 3D Diffusion Adapter Using Controlled Multi-View Editing
Mar 19, 2024



Open-domain 3D object synthesis has been lagging behind image synthesis due to limited data and higher computational complexity. To bridge this gap, recent works have investigated multi-view diffusion but often fall short in either 3D consistency, visual quality, or efficiency. This paper proposes MVEdit, which functions as a 3D counterpart of SDEdit, employing ancestral sampling to jointly denoise multi-view images and output high-quality textured meshes. Built on off-the-shelf 2D diffusion models, MVEdit achieves 3D consistency through a training-free 3D Adapter, which lifts the 2D views of the last timestep into a coherent 3D representation, then conditions the 2D views of the next timestep using rendered views, without uncompromising visual quality. With an inference time of only 2-5 minutes, this framework achieves better trade-off between quality and speed than score distillation. MVEdit is highly versatile and extendable, with a wide range of applications including text/image-to-3D generation, 3D-to-3D editing, and high-quality texture synthesis. In particular, evaluations demonstrate state-of-the-art performance in both image-to-3D and text-guided texture generation tasks. Additionally, we introduce a method for fine-tuning 2D latent diffusion models on small 3D datasets with limited resources, enabling fast low-resolution text-to-3D initialization.
Delving into Discrete Normalizing Flows on SO Manifold for Probabilistic Rotation Modeling
Apr 08, 2023Normalizing flows (NFs) provide a powerful tool to construct an expressive distribution by a sequence of trackable transformations of a base distribution and form a probabilistic model of underlying data. Rotation, as an important quantity in computer vision, graphics, and robotics, can exhibit many ambiguities when occlusion and symmetry occur and thus demands such probabilistic models. Though much progress has been made for NFs in Euclidean space, there are no effective normalizing flows without discontinuity or many-to-one mapping tailored for SO(3) manifold. Given the unique non-Euclidean properties of the rotation manifold, adapting the existing NFs to SO(3) manifold is non-trivial. In this paper, we propose a novel normalizing flow on SO(3) by combining a Mobius transformation-based coupling layer and a quaternion affine transformation. With our proposed rotation normalizing flows, one can not only effectively express arbitrary distributions on SO(3), but also conditionally build the target distribution given input observations. Extensive experiments show that our rotation normalizing flows significantly outperform the baselines on both unconditional and conditional tasks.