 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLLM Retrieval for Stable and Predictable Ad Recommendations
May 21, 2026Traditional ads recommendation systems have primarily focused on optimizing for prediction accuracy of click or conversion events using canonical metrics such as recall or normalized discounted cumulative gain (NDCG). With the hyper-growth of ads inventory and liquidity with generative AI technologies, the prediction stability and predictability is becoming increasingly critical. Intuitively, prediction stability and predictability can be defined to quantify system robustness with respect to minor/noisy input (ads, creatives) perturbations, the lack of which could lead to advertiser perceivable problems such as repeatability, cold start and under-exploration. In this paper, we introduce a new evaluation framework for quantifying stability and predictability of an ads recommender system, and present an online validated semantic candidate generation framework powered by fine-tuned Large Language Models (LLMs) that showed significant improvement along these metrics by fundamentally improving the semantic-awareness of the system. The approach extracts hierarchical semantic attributes from ad creatives to obtain LLM representations, which serve as the foundation for graph-based expansion, ensuring the retrieved candidates encapsulate semantic variants of an ad, guaranteeing that small creative variants from the advertiser yield consistent and explainable delivery results to the user. We tested this LLM ads retrieval framework in a large-scale industrial ads recommendation system, demonstrating significant improvements across offline and online A/B experiments, showcasing gains in both predictability and traditional performance metrics. Although evaluated in the ads stack, this is a general framework that can be applied broadly to any large-scale recommendation and retrieval systems facing similar scaling and predictability challenges.
Passive Underwater Acoustic Signal Separation based on Feature Decoupling Dual-path Network
Apr 11, 2025Signal separation in the passive underwater acoustic domain has heavily relied on deep learning techniques to isolate ship radiated noise. However, the separation networks commonly used in this domain stem from speech separation applications and may not fully consider the unique aspects of underwater acoustics beforehand, such as the influence of different propagation media, signal frequencies and modulation characteristics. This oversight highlights the need for tailored approaches that account for the specific characteristics of underwater sound propagation. This study introduces a novel temporal network designed to separate ship radiated noise by employing a dual-path model and a feature decoupling approach. The mixed signals' features are transformed into a space where they exhibit greater independence, with each dimension's significance decoupled. Subsequently, a fusion of local and global attention mechanisms is employed in the separation layer. Extensive comparisons showcase the effectiveness of this method when compared to other prevalent network models, as evidenced by its performance in the ShipsEar and DeepShip datasets.
Selecting the Number of Communities for Weighted Degree-Corrected Stochastic Block Models
Jun 08, 2024We investigate how to select the number of communities for weighted networks without a full likelihood modeling. First, we propose a novel weighted degree-corrected stochastic block model (DCSBM), in which the mean adjacency matrix is modeled as the same as in standard DCSBM, while the variance profile matrix is assumed to be related to the mean adjacency matrix through a given variance function. Our method of selection the number of communities is based on a sequential testing framework, in each step the weighed DCSBM is fitted via some spectral clustering method. A key step is to carry out matrix scaling on the estimated variance profile matrix. The resulting scaling factors can be used to normalize the adjacency matrix, from which the testing statistic is obtained. Under mild conditions on the weighted DCSBM, our proposed procedure is shown to be consistent in estimating the true number of communities. Numerical experiments on both simulated and real network data also demonstrate the desirable empirical properties of our method.
Opinion Extraction as A Structured Sentiment Analysis using Transformers
Dec 09, 2021

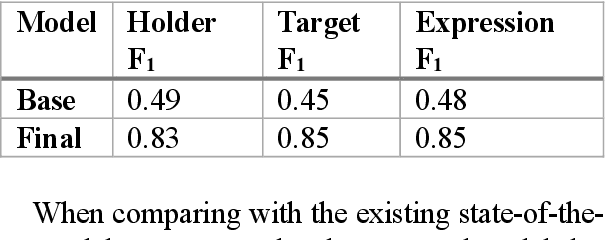
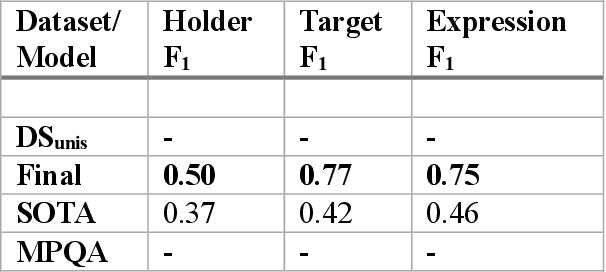
Relationship extraction and named entity recognition have always been considered as two distinct tasks that require different input data, labels, and models. However, both are essential for structured sentiment analysis. We believe that both tasks can be combined into a single stacked model with the same input data. We performed different experiments to find the best model to extract multiple opinion tuples from a single sentence. The opinion tuples will consist of holders, targets, and expressions. With the opinion tuples, we will be able to extract the relationship we need.
Cross-modality Knowledge Transfer for Prostate Segmentation from CT Scans
Sep 11, 2019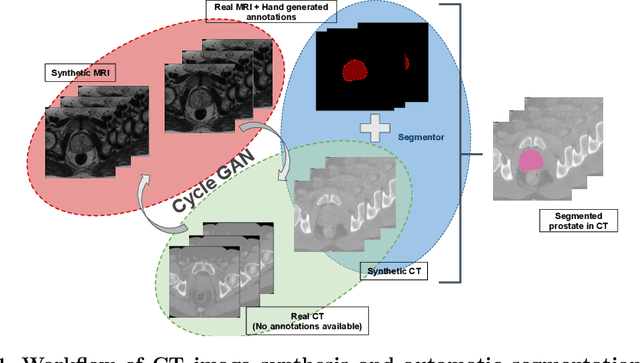
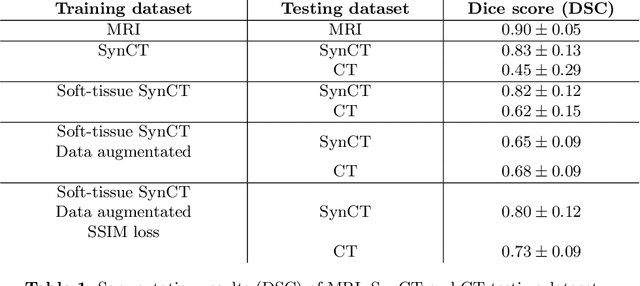

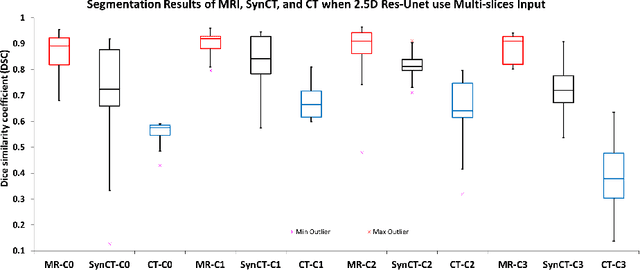
Creating large scale high-quality annotations is a known challenge in medical imaging. In this work, based on the CycleGAN algorithm, we propose leveraging annotations from one modality to be useful in other modalities. More specifically, the proposed algorithm creates highly realistic synthetic CT images (SynCT) from prostate MR images using unpaired data sets. By using SynCT images (without segmentation labels) and MR images (with segmentation labels available), we have trained a deep segmentation network for precise delineation of prostate from real CT scans. For the generator in our CycleGAN, the cycle consistency term is used to guarantee that SynCT shares the identical manually-drawn, high-quality masks originally delineated on MR images. Further, we introduce a cost function based on structural similarity index (SSIM) to improve the anatomical similarity between real and synthetic images. For segmentation followed by the SynCT generation from CycleGAN, automatic delineation is achieved through a 2.5D Residual U-Net. Quantitative evaluation demonstrates comparable segmentation results between our SynCT and radiologist drawn masks for real CT images, solving an important problem in medical image segmentation field when ground truth annotations are not available for the modality of interest.