 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edgepi-Flow: Policy-Based Few-Step Generation via Imitation Distillation
Oct 16, 2025Few-step diffusion or flow-based generative models typically distill a velocity-predicting teacher into a student that predicts a shortcut towards denoised data. This format mismatch has led to complex distillation procedures that often suffer from a quality-diversity trade-off. To address this, we propose policy-based flow models ($\pi$-Flow). $\pi$-Flow modifies the output layer of a student flow model to predict a network-free policy at one timestep. The policy then produces dynamic flow velocities at future substeps with negligible overhead, enabling fast and accurate ODE integration on these substeps without extra network evaluations. To match the policy's ODE trajectory to the teacher's, we introduce a novel imitation distillation approach, which matches the policy's velocity to the teacher's along the policy's trajectory using a standard $\ell_2$ flow matching loss. By simply mimicking the teacher's behavior, $\pi$-Flow enables stable and scalable training and avoids the quality-diversity trade-off. On ImageNet 256$^2$, it attains a 1-NFE FID of 2.85, outperforming MeanFlow of the same DiT architecture. On FLUX.1-12B and Qwen-Image-20B at 4 NFEs, $\pi$-Flow achieves substantially better diversity than state-of-the-art few-step methods, while maintaining teacher-level quality.
Taming Flow-based I2V Models for Creative Video Editing
Sep 26, 2025Although image editing techniques have advanced significantly, video editing, which aims to manipulate videos according to user intent, remains an emerging challenge. Most existing image-conditioned video editing methods either require inversion with model-specific design or need extensive optimization, limiting their capability of leveraging up-to-date image-to-video (I2V) models to transfer the editing capability of image editing models to the video domain. To this end, we propose IF-V2V, an Inversion-Free method that can adapt off-the-shelf flow-matching-based I2V models for video editing without significant computational overhead. To circumvent inversion, we devise Vector Field Rectification with Sample Deviation to incorporate information from the source video into the denoising process by introducing a deviation term into the denoising vector field. To further ensure consistency with the source video in a model-agnostic way, we introduce Structure-and-Motion-Preserving Initialization to generate motion-aware temporally correlated noise with structural information embedded. We also present a Deviation Caching mechanism to minimize the additional computational cost for denoising vector rectification without significantly impacting editing quality. Evaluations demonstrate that our method achieves superior editing quality and consistency over existing approaches, offering a lightweight plug-and-play solution to realize visual creativity.
Gaussian Mixture Flow Matching Models
Apr 07, 2025
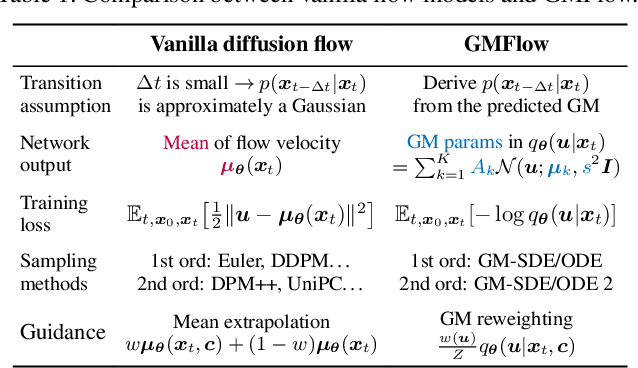

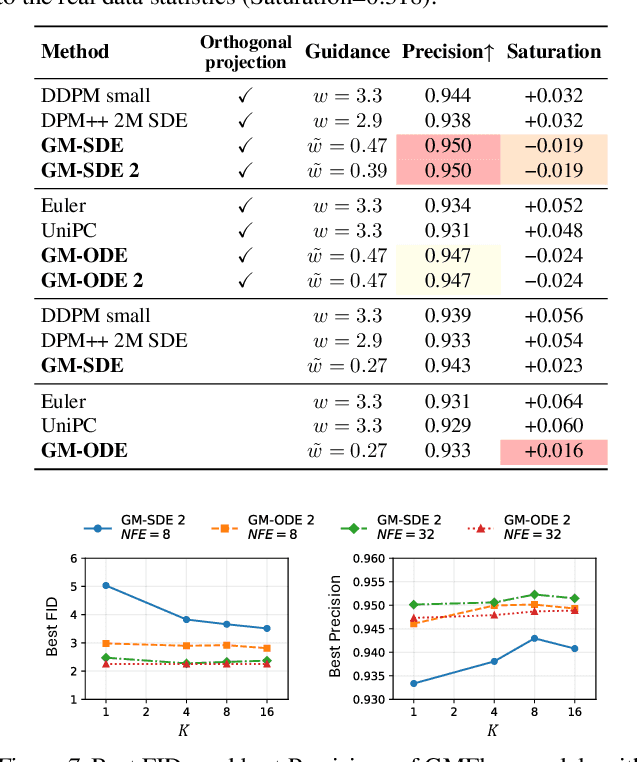
Diffusion models approximate the denoising distribution as a Gaussian and predict its mean, whereas flow matching models reparameterize the Gaussian mean as flow velocity. However, they underperform in few-step sampling due to discretization error and tend to produce over-saturated colors under classifier-free guidance (CFG). To address these limitations, we propose a novel Gaussian mixture flow matching (GMFlow) model: instead of predicting the mean, GMFlow predicts dynamic Gaussian mixture (GM) parameters to capture a multi-modal flow velocity distribution, which can be learned with a KL divergence loss. We demonstrate that GMFlow generalizes previous diffusion and flow matching models where a single Gaussian is learned with an $L_2$ denoising loss. For inference, we derive GM-SDE/ODE solvers that leverage analytic denoising distributions and velocity fields for precise few-step sampling. Furthermore, we introduce a novel probabilistic guidance scheme that mitigates the over-saturation issues of CFG and improves image generation quality. Extensive experiments demonstrate that GMFlow consistently outperforms flow matching baselines in generation quality, achieving a Precision of 0.942 with only 6 sampling steps on ImageNet 256$\times$256.
3D-Adapter: Geometry-Consistent Multi-View Diffusion for High-Quality 3D Generation
Oct 24, 2024
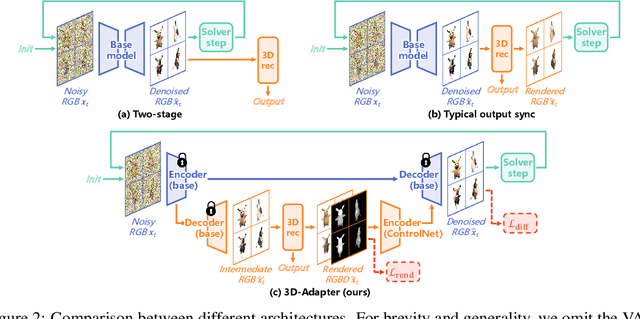
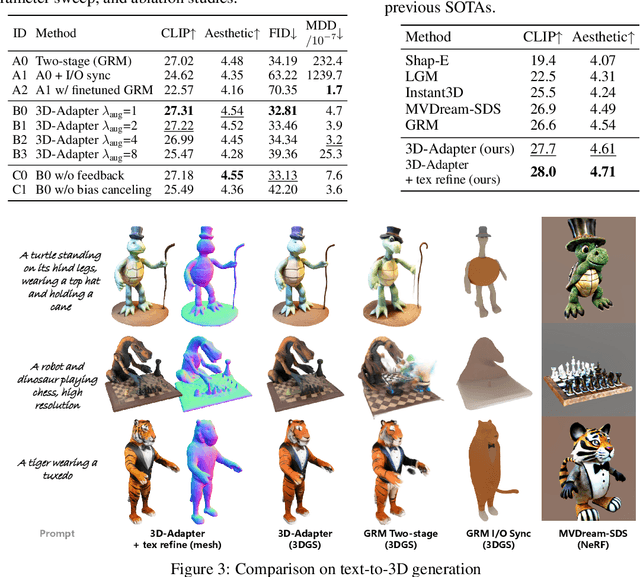
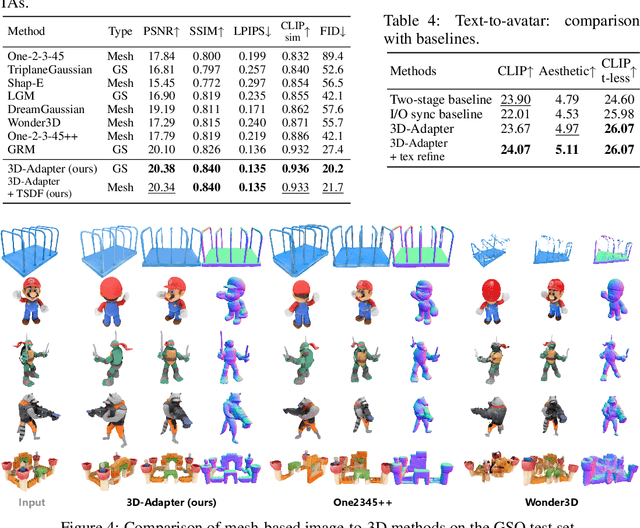
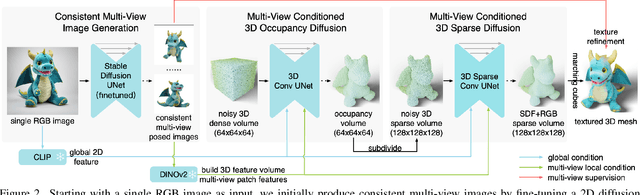
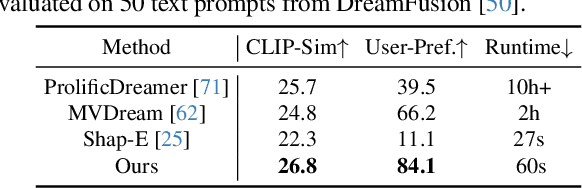
Multi-view image diffusion models have significantly advanced open-domain 3D object generation. However, most existing models rely on 2D network architectures that lack inherent 3D biases, resulting in compromised geometric consistency. To address this challenge, we introduce 3D-Adapter, a plug-in module designed to infuse 3D geometry awareness into pretrained image diffusion models. Central to our approach is the idea of 3D feedback augmentation: for each denoising step in the sampling loop, 3D-Adapter decodes intermediate multi-view features into a coherent 3D representation, then re-encodes the rendered RGBD views to augment the pretrained base model through feature addition. We study two variants of 3D-Adapter: a fast feed-forward version based on Gaussian splatting and a versatile training-free version utilizing neural fields and meshes. Our extensive experiments demonstrate that 3D-Adapter not only greatly enhances the geometry quality of text-to-multi-view models such as Instant3D and Zero123++, but also enables high-quality 3D generation using the plain text-to-image Stable Diffusion. Furthermore, we showcase the broad application potential of 3D-Adapter by presenting high quality results in text-to-3D, image-to-3D, text-to-texture, and text-to-avatar tasks.
GRM: Large Gaussian Reconstruction Model for Efficient 3D Reconstruction and Generation
Mar 21, 2024



We introduce GRM, a large-scale reconstructor capable of recovering a 3D asset from sparse-view images in around 0.1s. GRM is a feed-forward transformer-based model that efficiently incorporates multi-view information to translate the input pixels into pixel-aligned Gaussians, which are unprojected to create a set of densely distributed 3D Gaussians representing a scene. Together, our transformer architecture and the use of 3D Gaussians unlock a scalable and efficient reconstruction framework. Extensive experimental results demonstrate the superiority of our method over alternatives regarding both reconstruction quality and efficiency. We also showcase the potential of GRM in generative tasks, i.e., text-to-3D and image-to-3D, by integrating it with existing multi-view diffusion models. Our project website is at: https://justimyhxu.github.io/projects/grm/.
Generic 3D Diffusion Adapter Using Controlled Multi-View Editing
Mar 19, 2024



Open-domain 3D object synthesis has been lagging behind image synthesis due to limited data and higher computational complexity. To bridge this gap, recent works have investigated multi-view diffusion but often fall short in either 3D consistency, visual quality, or efficiency. This paper proposes MVEdit, which functions as a 3D counterpart of SDEdit, employing ancestral sampling to jointly denoise multi-view images and output high-quality textured meshes. Built on off-the-shelf 2D diffusion models, MVEdit achieves 3D consistency through a training-free 3D Adapter, which lifts the 2D views of the last timestep into a coherent 3D representation, then conditions the 2D views of the next timestep using rendered views, without uncompromising visual quality. With an inference time of only 2-5 minutes, this framework achieves better trade-off between quality and speed than score distillation. MVEdit is highly versatile and extendable, with a wide range of applications including text/image-to-3D generation, 3D-to-3D editing, and high-quality texture synthesis. In particular, evaluations demonstrate state-of-the-art performance in both image-to-3D and text-guided texture generation tasks. Additionally, we introduce a method for fine-tuning 2D latent diffusion models on small 3D datasets with limited resources, enabling fast low-resolution text-to-3D initialization.
One-2-3-45++: Fast Single Image to 3D Objects with Consistent Multi-View Generation and 3D Diffusion
Nov 14, 2023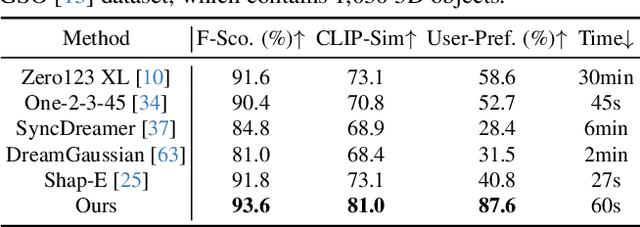
Recent advancements in open-world 3D object generation have been remarkable, with image-to-3D methods offering superior fine-grained control over their text-to-3D counterparts. However, most existing models fall short in simultaneously providing rapid generation speeds and high fidelity to input images - two features essential for practical applications. In this paper, we present One-2-3-45++, an innovative method that transforms a single image into a detailed 3D textured mesh in approximately one minute. Our approach aims to fully harness the extensive knowledge embedded in 2D diffusion models and priors from valuable yet limited 3D data. This is achieved by initially finetuning a 2D diffusion model for consistent multi-view image generation, followed by elevating these images to 3D with the aid of multi-view conditioned 3D native diffusion models. Extensive experimental evaluations demonstrate that our method can produce high-quality, diverse 3D assets that closely mirror the original input image. Our project webpage: https://sudo-ai-3d.github.io/One2345plus_page.
Zero123++: a Single Image to Consistent Multi-view Diffusion Base Model
Oct 23, 2023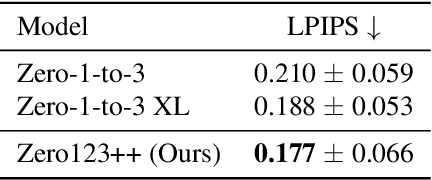
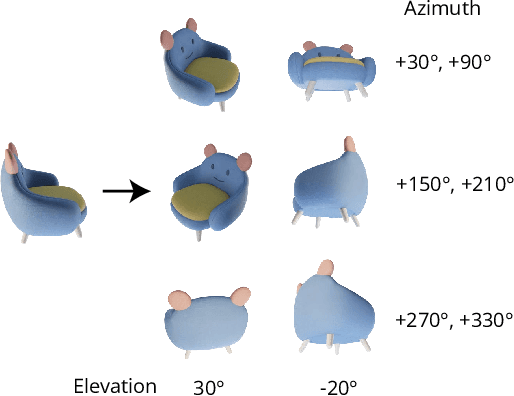
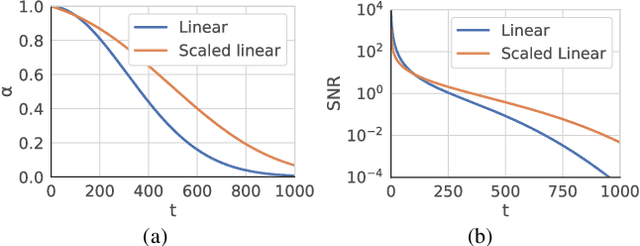

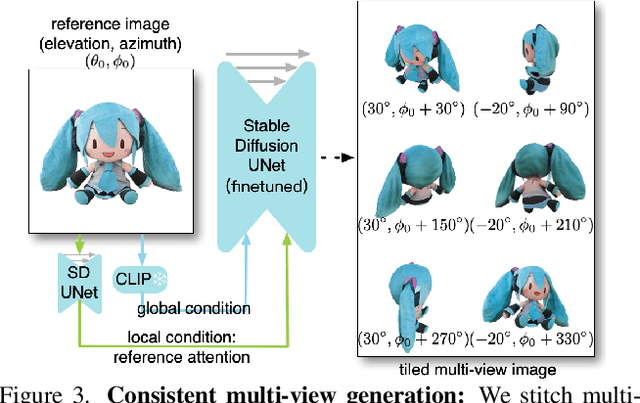
We report Zero123++, an image-conditioned diffusion model for generating 3D-consistent multi-view images from a single input view. To take full advantage of pretrained 2D generative priors, we develop various conditioning and training schemes to minimize the effort of finetuning from off-the-shelf image diffusion models such as Stable Diffusion. Zero123++ excels in producing high-quality, consistent multi-view images from a single image, overcoming common issues like texture degradation and geometric misalignment. Furthermore, we showcase the feasibility of training a ControlNet on Zero123++ for enhanced control over the generation process. The code is available at https://github.com/SUDO-AI-3D/zero123plus.
Single-Stage Diffusion NeRF: A Unified Approach to 3D Generation and Reconstruction
Apr 17, 2023



3D-aware image synthesis encompasses a variety of tasks, such as scene generation and novel view synthesis from images. Despite numerous task-specific methods, developing a comprehensive model remains challenging. In this paper, we present SSDNeRF, a unified approach that employs an expressive diffusion model to learn a generalizable prior of neural radiance fields (NeRF) from multi-view images of diverse objects. Previous studies have used two-stage approaches that rely on pretrained NeRFs as real data to train diffusion models. In contrast, we propose a new single-stage training paradigm with an end-to-end objective that jointly optimizes a NeRF auto-decoder and a latent diffusion model, enabling simultaneous 3D reconstruction and prior learning, even from sparsely available views. At test time, we can directly sample the diffusion prior for unconditional generation, or combine it with arbitrary observations of unseen objects for NeRF reconstruction. SSDNeRF demonstrates robust results comparable to or better than leading task-specific methods in unconditional generation and single/sparse-view 3D reconstruction.
EPro-PnP: Generalized End-to-End Probabilistic Perspective-n-Points for Monocular Object Pose Estimation
Mar 22, 2023
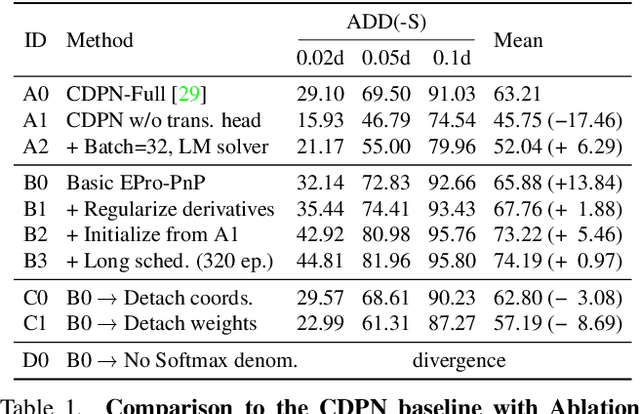
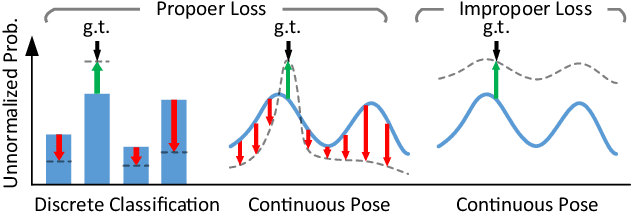
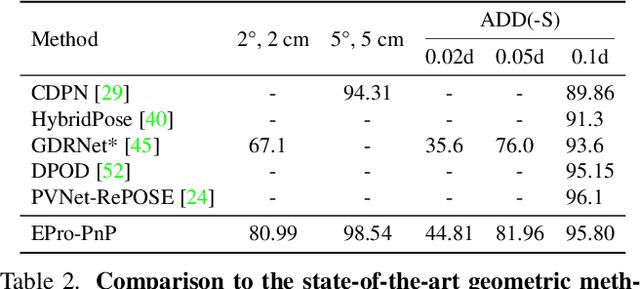
Locating 3D objects from a single RGB image via Perspective-n-Point (PnP) is a long-standing problem in computer vision. Driven by end-to-end deep learning, recent studies suggest interpreting PnP as a differentiable layer, allowing for partial learning of 2D-3D point correspondences by backpropagating the gradients of pose loss. Yet, learning the entire correspondences from scratch is highly challenging, particularly for ambiguous pose solutions, where the globally optimal pose is theoretically non-differentiable w.r.t. the points. In this paper, we propose the EPro-PnP, a probabilistic PnP layer for general end-to-end pose estimation, which outputs a distribution of pose with differentiable probability density on the SE(3) manifold. The 2D-3D coordinates and corresponding weights are treated as intermediate variables learned by minimizing the KL divergence between the predicted and target pose distribution. The underlying principle generalizes previous approaches, and resembles the attention mechanism. EPro-PnP can enhance existing correspondence networks, closing the gap between PnP-based method and the task-specific leaders on the LineMOD 6DoF pose estimation benchmark. Furthermore, EPro-PnP helps to explore new possibilities of network design, as we demonstrate a novel deformable correspondence network with the state-of-the-art pose accuracy on the nuScenes 3D object detection benchmark. Our code is available at https://github.com/tjiiv-cprg/EPro-PnP-v2.