 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Intelligible Human-Robot Interaction: An Active Inference Approach to Occluded Pedestrian Scenarios
Feb 26, 2026The sudden appearance of occluded pedestrians presents a critical safety challenge in autonomous driving. Conventional rule-based or purely data-driven approaches struggle with the inherent high uncertainty of these long-tail scenarios. To tackle this challenge, we propose a novel framework grounded in Active Inference, which endows the agent with a human-like, belief-driven mechanism. Our framework leverages a Rao-Blackwellized Particle Filter (RBPF) to efficiently estimate the pedestrian's hybrid state. To emulate human-like cognitive processes under uncertainty, we introduce a Conditional Belief Reset mechanism and a Hypothesis Injection technique to explicitly model beliefs about the pedestrian's multiple latent intentions. Planning is achieved via a Cross-Entropy Method (CEM) enhanced Model Predictive Path Integral (MPPI) controller, which synergizes the efficient, iterative search of CEM with the inherent robustness of MPPI. Simulation experiments demonstrate that our approach significantly reduces the collision rate compared to reactive, rule-based, and reinforcement learning (RL) baselines, while also exhibiting explainable and human-like driving behavior that reflects the agent's internal belief state.
Training Report of TeleChat3-MoE
Dec 30, 2025TeleChat3-MoE is the latest series of TeleChat large language models, featuring a Mixture-of-Experts (MoE) architecture with parameter counts ranging from 105 billion to over one trillion,trained end-to-end on Ascend NPU cluster. This technical report mainly presents the underlying training infrastructure that enables reliable and efficient scaling to frontier model sizes. We detail systematic methodologies for operator-level and end-to-end numerical accuracy verification, ensuring consistency across hardware platforms and distributed parallelism strategies. Furthermore, we introduce a suite of performance optimizations, including interleaved pipeline scheduling, attention-aware data scheduling for long-sequence training,hierarchical and overlapped communication for expert parallelism, and DVM-based operator fusion. A systematic parallelization framework, leveraging analytical estimation and integer linear programming, is also proposed to optimize multi-dimensional parallelism configurations. Additionally, we present methodological approaches to cluster-level optimizations, addressing host- and device-bound bottlenecks during large-scale training tasks. These infrastructure advancements yield significant throughput improvements and near-linear scaling on clusters comprising thousands of devices, providing a robust foundation for large-scale language model development on hardware ecosystems.
Technical Report of TeleChat2, TeleChat2.5 and T1
Jul 24, 2025
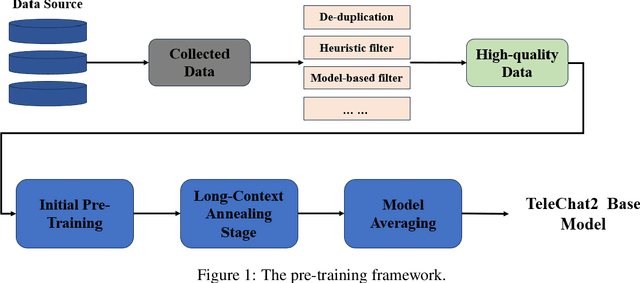

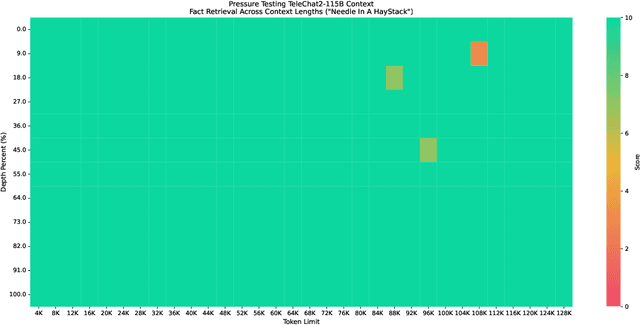
We introduce the latest series of TeleChat models: \textbf{TeleChat2}, \textbf{TeleChat2.5}, and \textbf{T1}, offering a significant upgrade over their predecessor, TeleChat. Despite minimal changes to the model architecture, the new series achieves substantial performance gains through enhanced training strategies in both pre-training and post-training stages. The series begins with \textbf{TeleChat2}, which undergoes pretraining on 10 trillion high-quality and diverse tokens. This is followed by Supervised Fine-Tuning (SFT) and Direct Preference Optimization (DPO) to further enhance its capabilities. \textbf{TeleChat2.5} and \textbf{T1} expand the pipeline by incorporating a continual pretraining phase with domain-specific datasets, combined with reinforcement learning (RL) to improve performance in code generation and mathematical reasoning tasks. The \textbf{T1} variant is designed for complex reasoning, supporting long Chain-of-Thought (CoT) reasoning and demonstrating substantial improvements in mathematics and coding. In contrast, \textbf{TeleChat2.5} prioritizes speed, delivering rapid inference. Both flagship models of \textbf{T1} and \textbf{TeleChat2.5} are dense Transformer-based architectures with 115B parameters, showcasing significant advancements in reasoning and general task performance compared to the original TeleChat. Notably, \textbf{T1-115B} outperform proprietary models such as OpenAI's o1-mini and GPT-4o. We publicly release \textbf{TeleChat2}, \textbf{TeleChat2.5} and \textbf{T1}, including post-trained versions with 35B and 115B parameters, to empower developers and researchers with state-of-the-art language models tailored for diverse applications.
52B to 1T: Lessons Learned via Tele-FLM Series
Jul 03, 2024



Large Language Models (LLMs) represent a significant stride toward Artificial General Intelligence. As scaling laws underscore the potential of increasing model sizes, the academic community has intensified its investigations into LLMs with capacities exceeding 50 billion parameters. This technical report builds on our prior work with Tele-FLM (also known as FLM-2), a publicly available 52-billion-parameter model. We delve into two primary areas: we first discuss our observation of Supervised Fine-tuning (SFT) on Tele-FLM-52B, which supports the "less is more" approach for SFT data construction; second, we demonstrate our experiments and analyses on the best practices for progressively growing a model from 52 billion to 102 billion, and subsequently to 1 trillion parameters. We will open-source a 1T model checkpoint, namely Tele-FLM-1T, to advance further training and research.
Tele-FLM Technical Report
Apr 25, 2024



Large language models (LLMs) have showcased profound capabilities in language understanding and generation, facilitating a wide array of applications. However, there is a notable paucity of detailed, open-sourced methodologies on efficiently scaling LLMs beyond 50 billion parameters with minimum trial-and-error cost and computational resources. In this report, we introduce Tele-FLM (aka FLM-2), a 52B open-sourced multilingual large language model that features a stable, efficient pre-training paradigm and enhanced factual judgment capabilities. Tele-FLM demonstrates superior multilingual language modeling abilities, measured by BPB on textual corpus. Besides, in both English and Chinese foundation model evaluation, it is comparable to strong open-sourced models that involve larger pre-training FLOPs, such as Llama2-70B and DeepSeek-67B. In addition to the model weights, we share the core designs, engineering practices, and training details, which we expect to benefit both the academic and industrial communities.
TeleChat Technical Report
Jan 08, 2024



In this technical report, we present TeleChat, a collection of large language models (LLMs) with parameters of 3 billion, 7 billion and 12 billion. It includes pretrained language models as well as fine-tuned chat models that is aligned with human preferences. TeleChat is initially pretrained on an extensive corpus containing a diverse collection of texts from both English and Chinese languages, including trillions of tokens. Subsequently, the model undergoes fine-tuning to align with human preferences, following a detailed methodology that we describe. We evaluate the performance of TeleChat on various tasks, including language understanding, mathematics, reasoning, code generation, and knowledge-based question answering. Our findings indicate that TeleChat achieves comparable performance to other open-source models of similar size across a wide range of public benchmarks. To support future research and applications utilizing LLMs, we release the fine-tuned model checkpoints of TeleChat's 7B and 12B variant, along with code and a portion of our pretraining data, to the public community.
Sophisticated deep learning with on-chip optical diffractive tensor processing
Dec 20, 2022



The ever-growing deep learning technologies are making revolutionary changes for modern life. However, conventional computing architectures are designed to process sequential and digital programs, being extremely burdened with performing massive parallel and adaptive deep learning applications. Photonic integrated circuits provide an efficient approach to mitigate bandwidth limitations and power-wall brought by its electronic counterparts, showing great potential in ultrafast and energy-free high-performance computing. Here, we propose an optical computing architecture enabled by on-chip diffraction to implement convolutional acceleration, termed optical convolution unit (OCU). We demonstrate that any real-valued convolution kernels can be exploited by OCU with a prominent computational throughput boosting via the concept of structral re-parameterization. With OCU as the fundamental unit, we build an optical convolutional neural network (oCNN) to implement two popular deep learning tasks: classification and regression. For classification, Fashion-MNIST and CIFAR-4 datasets are tested with accuracy of 91.63% and 86.25%, respectively. For regression, we build an optical denoising convolutional neural network (oDnCNN) to handle Gaussian noise in gray scale images with noise level {\sigma} = 10, 15, 20, resulting clean images with average PSNR of 31.70dB, 29.39dB and 27.72dB, respectively. The proposed OCU presents remarkable performance of low energy consumption and high information density due to its fully passive nature and compact footprint, providing a highly parallel while lightweight solution for future computing architecture to handle high dimensional tensors in deep learning.
MonoRUn: Monocular 3D Object Detection by Reconstruction and Uncertainty Propagation
Mar 24, 2021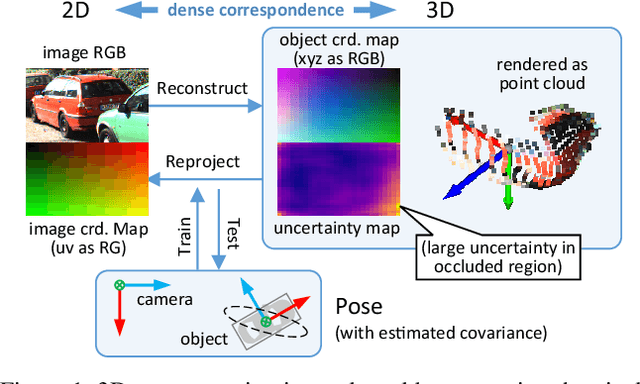
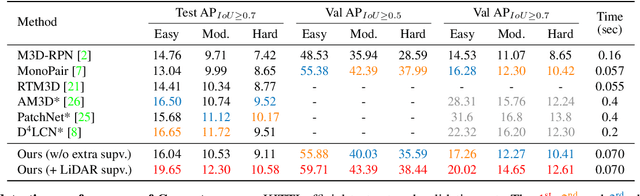
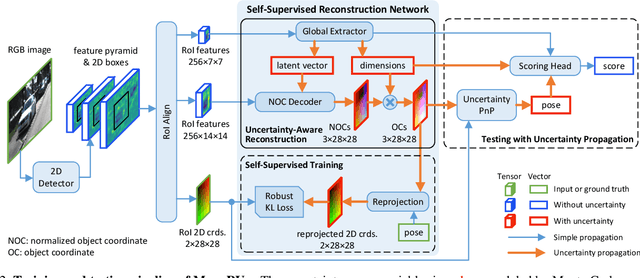
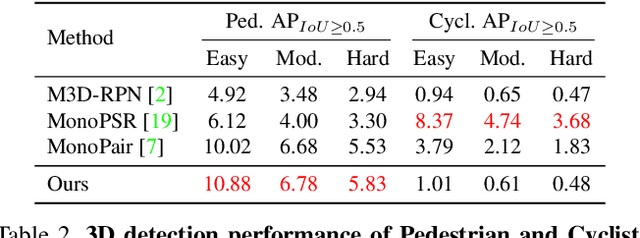
Object localization in 3D space is a challenging aspect in monocular 3D object detection. Recent advances in 6DoF pose estimation have shown that predicting dense 2D-3D correspondence maps between image and object 3D model and then estimating object pose via Perspective-n-Point (PnP) algorithm can achieve remarkable localization accuracy. Yet these methods rely on training with ground truth of object geometry, which is difficult to acquire in real outdoor scenes. To address this issue, we propose MonoRUn, a novel detection framework that learns dense correspondences and geometry in a self-supervised manner, with simple 3D bounding box annotations. To regress the pixel-related 3D object coordinates, we employ a regional reconstruction network with uncertainty awareness. For self-supervised training, the predicted 3D coordinates are projected back to the image plane. A Robust KL loss is proposed to minimize the uncertainty-weighted reprojection error. During testing phase, we exploit the network uncertainty by propagating it through all downstream modules. More specifically, the uncertainty-driven PnP algorithm is leveraged to estimate object pose and its covariance. Extensive experiments demonstrate that our proposed approach outperforms current state-of-the-art methods on KITTI benchmark.
NAST: Non-Autoregressive Spatial-Temporal Transformer for Time Series Forecasting
Feb 10, 2021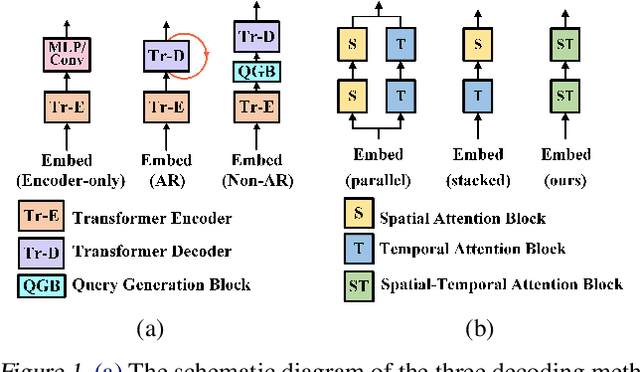
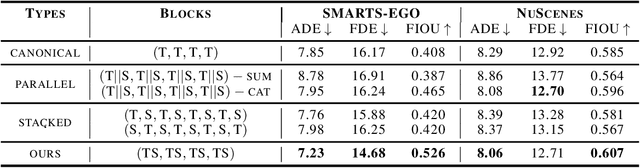
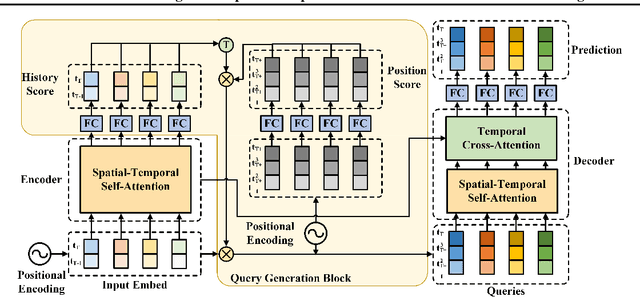
Although Transformer has made breakthrough success in widespread domains especially in Natural Language Processing (NLP), applying it to time series forecasting is still a great challenge. In time series forecasting, the autoregressive decoding of canonical Transformer models could introduce huge accumulative errors inevitably. Besides, utilizing Transformer to deal with spatial-temporal dependencies in the problem still faces tough difficulties.~To tackle these limitations, this work is the first attempt to propose a Non-Autoregressive Transformer architecture for time series forecasting, aiming at overcoming the time delay and accumulative error issues in the canonical Transformer. Moreover, we present a novel spatial-temporal attention mechanism, building a bridge by a learned temporal influence map to fill the gaps between the spatial and temporal attention, so that spatial and temporal dependencies can be processed integrally. Empirically, we evaluate our model on diversified ego-centric future localization datasets and demonstrate state-of-the-art performance on both real-time and accuracy.
SPFCN: Select and Prune the Fully Convolutional Networks for Real-time Parking Slot Detection
Mar 25, 2020
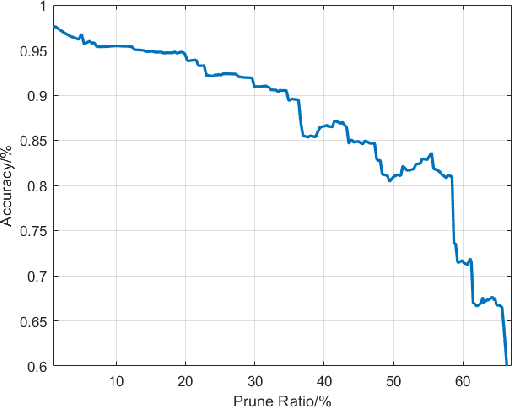
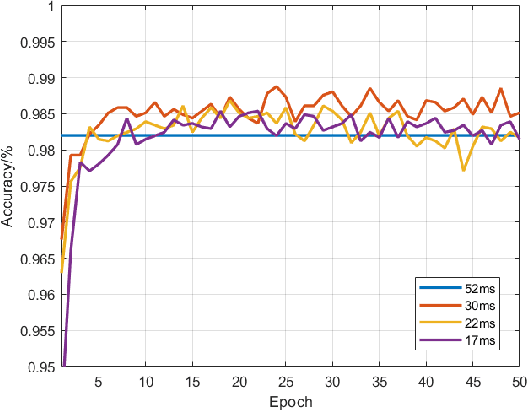
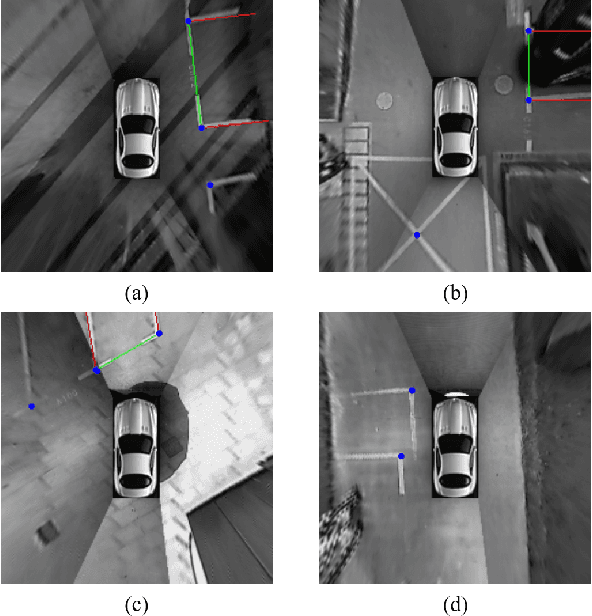
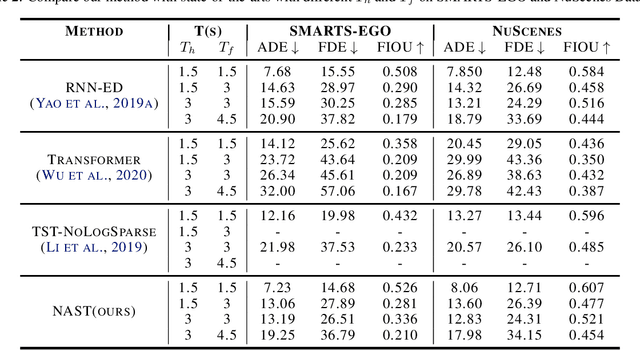
For passenger cars equipped with automatic parking function, convolutional neural networks are employed to detect parking slots on the panoramic surround view, which is an overhead image synthesized by four calibrated fish-eye images, The accuracy is obtained at the price of low speed or expensive computation equipments, which are sensitive for many car manufacturers. In this paper, the same accuracy is challenged by the proposed parking slot detector, which leverages deep convolutional networks for the faster speed and smaller model while keep the accuracy by simultaneously training and pruning it. To achieve the optimal trade-off, we developed a strategy to select the best receptive fields and prune the redundant channels automatically during training. The proposed model is capable of jointly detecting corners and line features of parking slots while running efficiently in real time on average CPU. Even without any specific computing devices, the model outperforms existing counterparts, at a frame rate of about 30 FPS on a 2.3 GHz CPU core, getting parking slot corner localization error of 1.51$\pm$2.14 cm (std. err.) and slot detection accuracy of 98\%, generally satisfying the requirements in both speed and accuracy on on-board mobile terminals.