 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStormWave: An Open-Source Portable SDR Platform for Over-the-Air Resilience Evaluation of Terrestrial and Aerial Communications
May 05, 2026This paper presents \emph{StormWave}, an open-source, portable software-defined Radio Frequency (RF) interference generation and monitoring platform designed for realistic field-based evaluation of the resilience of wireless communication systems. StormWave enables seamless composition and runtime switching among a wide range of narrowband and wideband waveforms, while supporting multiple digital modulations, adaptive coding, and multi-radio orchestration with real-time spectrum visualization. We evaluate the effectiveness of StormWave through both outdoor ground and air-to-air (A2A) experiments. Ground experiments demonstrate clear waveform- and modulation-dependent interference effects under realistic propagation conditions, while A2A experiments reveal pronounced distance-dependent constellation distortion and access-symbol degradation under active interference. The StormWave source code will be released to the community, with the expectation that StormWave will be used as a flexible, extensible, and field-ready platform for systematically validating interference resilience of wireless systems under realistic operating conditions.
The generalized underlap coefficient with an application in clustering
Feb 25, 2026Quantifying distributional separation across groups is fundamental in statistical learning and scientific discovery, yet most classical discrepancy measures are tailored to two-group comparisons. We generalize the underlap coefficient (UNL), a multi-group separation measure, to multivariate variables. We establish key properties of the UNL and provide an explicit connection to total variation. We further interpret the UNL as a dependence measure between a group label and variables of interest and compare it with mutual information. We propose an efficient importance sampling estimator of the UNL that can be combined with flexible density estimators. The utility of the UNL for assessing partition-covariate dependence in clustering is highlighted in detail, where it is particularly useful for evaluating whether the latent group structure can be explained by specific covariates. Finally we illustrate the application of the UNL in clustering using two real world datasets.
Less Is More -- Until It Breaks: Security Pitfalls of Vision Token Compression in Large Vision-Language Models
Jan 17, 2026Visual token compression is widely adopted to improve the inference efficiency of Large Vision-Language Models (LVLMs), enabling their deployment in latency-sensitive and resource-constrained scenarios. However, existing work has mainly focused on efficiency and performance, while the security implications of visual token compression remain largely unexplored. In this work, we first reveal that visual token compression substantially degrades the robustness of LVLMs: models that are robust under uncompressed inference become highly vulnerable once compression is enabled. These vulnerabilities are state-specific; failure modes emerge only in the compressed setting and completely disappear when compression is disabled, making them particularly hidden and difficult to diagnose. By analyzing the key stages of the compression process, we identify instability in token importance ranking as the primary cause of this robustness degradation. Small and imperceptible perturbations can significantly alter token rankings, leading the compression mechanism to mistakenly discard task-critical information and ultimately causing model failure. Motivated by this observation, we propose a Compression-Aware Attack to systematically study and exploit this vulnerability. CAA directly targets the token selection mechanism and induces failures exclusively under compressed inference. We further extend this approach to more realistic black-box settings and introduce Transfer CAA, where neither the target model nor the compression configuration is accessible. We further evaluate potential defenses and find that they provide only limited protection. Extensive experiments across models, datasets, and compression methods show that visual token compression significantly undermines robustness, revealing a previously overlooked efficiency-security trade-off.
Training Report of TeleChat3-MoE
Dec 30, 2025TeleChat3-MoE is the latest series of TeleChat large language models, featuring a Mixture-of-Experts (MoE) architecture with parameter counts ranging from 105 billion to over one trillion,trained end-to-end on Ascend NPU cluster. This technical report mainly presents the underlying training infrastructure that enables reliable and efficient scaling to frontier model sizes. We detail systematic methodologies for operator-level and end-to-end numerical accuracy verification, ensuring consistency across hardware platforms and distributed parallelism strategies. Furthermore, we introduce a suite of performance optimizations, including interleaved pipeline scheduling, attention-aware data scheduling for long-sequence training,hierarchical and overlapped communication for expert parallelism, and DVM-based operator fusion. A systematic parallelization framework, leveraging analytical estimation and integer linear programming, is also proposed to optimize multi-dimensional parallelism configurations. Additionally, we present methodological approaches to cluster-level optimizations, addressing host- and device-bound bottlenecks during large-scale training tasks. These infrastructure advancements yield significant throughput improvements and near-linear scaling on clusters comprising thousands of devices, providing a robust foundation for large-scale language model development on hardware ecosystems.
BenchLink: An SoC-Based Benchmark for Resilient Communication Links in GPS-Denied Environments
Dec 24, 2025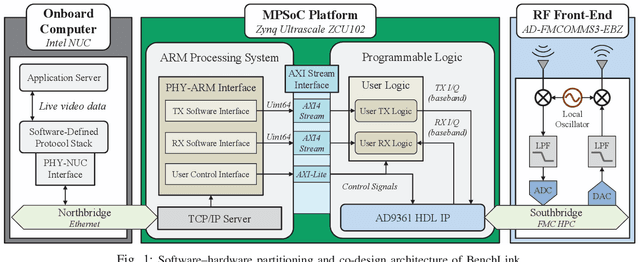
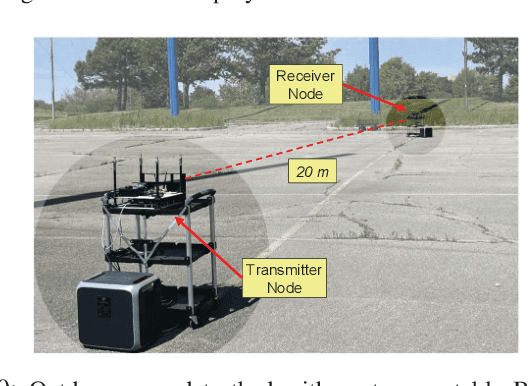
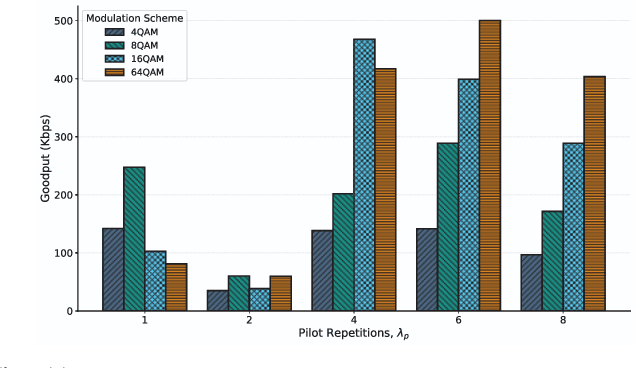

Accurate timing and synchronization, typically enabled by GPS, are essential for modern wireless communication systems. However, many emerging applications must operate in GPS-denied environments where signals are unreliable or disrupted, resulting in oscillator drift and carrier frequency impairments. To address these challenges, we present BenchLink, a System-on-Chip (SoC)-based benchmark for resilient communication links that functions without GPS and supports adaptive pilot density and modulation. Unlike traditional General Purpose Processor (GPP)-based software-defined radios (e.g. USRPs), the SoC-based design allows for more precise latency control. We implement and evaluate BenchLink on Zynq UltraScale+ MPSoCs, and demonstrate its effectiveness in both ground and aerial environments. A comprehensive dataset has also been collected under various conditions. We will make both the SoC-based link design and dataset available to the wireless community. BenchLink is expected to facilitate future research on data-driven link adaptation, resilient synchronization in GPS-denied scenarios, and emerging applications that require precise latency control, such as integrated radar sensing and communication.
One Tool Is Enough: Reinforcement Learning for Repository-Level LLM Agents
Dec 24, 2025Locating the files and functions requiring modification in large open-source software (OSS) repositories is challenging due to their scale and structural complexity. Existing large language model (LLM)-based methods typically treat this as a repository-level retrieval task and rely on multiple auxiliary tools, which overlook code execution logic and complicate model control. We propose RepoNavigator, an LLM agent equipped with a single execution-aware tool-jumping to the definition of an invoked symbol. This unified design reflects the actual flow of code execution while simplifying tool manipulation. RepoNavigator is trained end-to-end via Reinforcement Learning (RL) directly from a pretrained model, without any closed-source distillation. Experiments demonstrate that RL-trained RepoNavigator achieves state-of-the-art performance, with the 7B model outperforming 14B baselines, the 14B model surpassing 32B competitors, and even the 32B model exceeding closed-source models such as Claude-3.7. These results confirm that integrating a single, structurally grounded tool with RL training provides an efficient and scalable solution for repository-level issue localization.
Population-Evolve: a Parallel Sampling and Evolutionary Method for LLM Math Reasoning
Dec 22, 2025Test-time scaling has emerged as a promising direction for enhancing the reasoning capabilities of Large Language Models in last few years. In this work, we propose Population-Evolve, a training-free method inspired by Genetic Algorithms to optimize LLM reasoning. Our approach maintains a dynamic population of candidate solutions for each problem via parallel reasoning. By incorporating an evolve prompt, the LLM self-evolves its population in all iterations. Upon convergence, the final answer is derived via majority voting. Furthermore, we establish a unification framework that interprets existing test-time scaling strategies through the lens of genetic algorithms. Empirical results demonstrate that Population-Evolve achieves superior accuracy with low performance variance and computational efficiency. Our findings highlight the potential of evolutionary strategies to unlock the reasoning power of LLMs during inference.
Character-Level Perturbations Disrupt LLM Watermarks
Sep 11, 2025Large Language Model (LLM) watermarking embeds detectable signals into generated text for copyright protection, misuse prevention, and content detection. While prior studies evaluate robustness using watermark removal attacks, these methods are often suboptimal, creating the misconception that effective removal requires large perturbations or powerful adversaries. To bridge the gap, we first formalize the system model for LLM watermark, and characterize two realistic threat models constrained on limited access to the watermark detector. We then analyze how different types of perturbation vary in their attack range, i.e., the number of tokens they can affect with a single edit. We observe that character-level perturbations (e.g., typos, swaps, deletions, homoglyphs) can influence multiple tokens simultaneously by disrupting the tokenization process. We demonstrate that character-level perturbations are significantly more effective for watermark removal under the most restrictive threat model. We further propose guided removal attacks based on the Genetic Algorithm (GA) that uses a reference detector for optimization. Under a practical threat model with limited black-box queries to the watermark detector, our method demonstrates strong removal performance. Experiments confirm the superiority of character-level perturbations and the effectiveness of the GA in removing watermarks under realistic constraints. Additionally, we argue there is an adversarial dilemma when considering potential defenses: any fixed defense can be bypassed by a suitable perturbation strategy. Motivated by this principle, we propose an adaptive compound character-level attack. Experimental results show that this approach can effectively defeat the defenses. Our findings highlight significant vulnerabilities in existing LLM watermark schemes and underline the urgency for the development of new robust mechanisms.
Technical Report of TeleChat2, TeleChat2.5 and T1
Jul 24, 2025
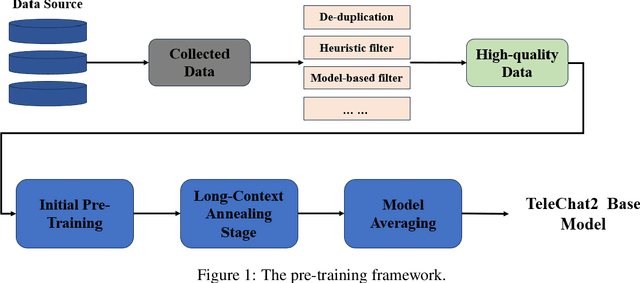

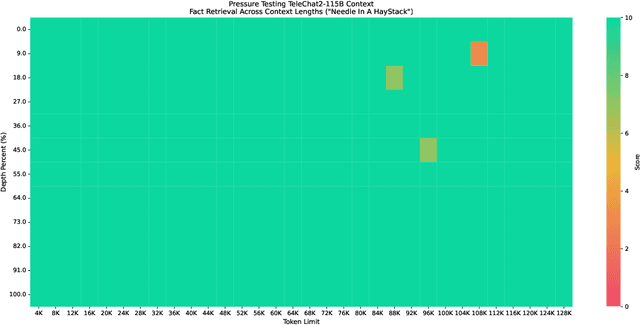
We introduce the latest series of TeleChat models: \textbf{TeleChat2}, \textbf{TeleChat2.5}, and \textbf{T1}, offering a significant upgrade over their predecessor, TeleChat. Despite minimal changes to the model architecture, the new series achieves substantial performance gains through enhanced training strategies in both pre-training and post-training stages. The series begins with \textbf{TeleChat2}, which undergoes pretraining on 10 trillion high-quality and diverse tokens. This is followed by Supervised Fine-Tuning (SFT) and Direct Preference Optimization (DPO) to further enhance its capabilities. \textbf{TeleChat2.5} and \textbf{T1} expand the pipeline by incorporating a continual pretraining phase with domain-specific datasets, combined with reinforcement learning (RL) to improve performance in code generation and mathematical reasoning tasks. The \textbf{T1} variant is designed for complex reasoning, supporting long Chain-of-Thought (CoT) reasoning and demonstrating substantial improvements in mathematics and coding. In contrast, \textbf{TeleChat2.5} prioritizes speed, delivering rapid inference. Both flagship models of \textbf{T1} and \textbf{TeleChat2.5} are dense Transformer-based architectures with 115B parameters, showcasing significant advancements in reasoning and general task performance compared to the original TeleChat. Notably, \textbf{T1-115B} outperform proprietary models such as OpenAI's o1-mini and GPT-4o. We publicly release \textbf{TeleChat2}, \textbf{TeleChat2.5} and \textbf{T1}, including post-trained versions with 35B and 115B parameters, to empower developers and researchers with state-of-the-art language models tailored for diverse applications.
When Better Features Mean Greater Risks: The Performance-Privacy Trade-Off in Contrastive Learning
Jun 06, 2025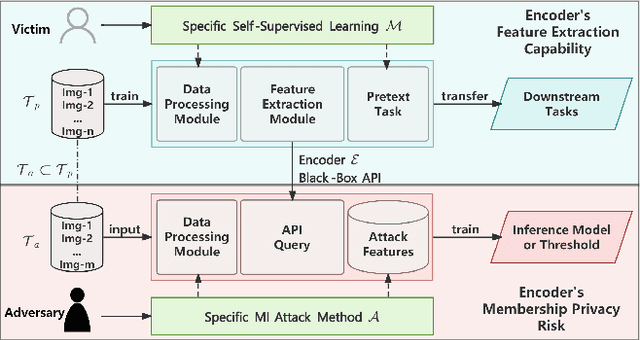

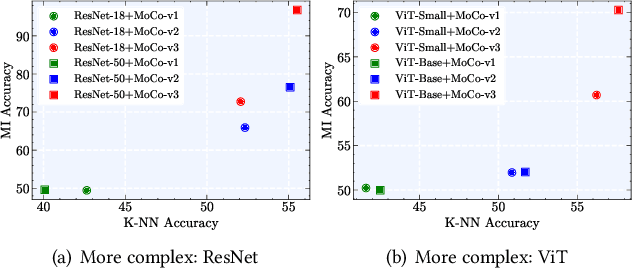

With the rapid advancement of deep learning technology, pre-trained encoder models have demonstrated exceptional feature extraction capabilities, playing a pivotal role in the research and application of deep learning. However, their widespread use has raised significant concerns about the risk of training data privacy leakage. This paper systematically investigates the privacy threats posed by membership inference attacks (MIAs) targeting encoder models, focusing on contrastive learning frameworks. Through experimental analysis, we reveal the significant impact of model architecture complexity on membership privacy leakage: As more advanced encoder frameworks improve feature-extraction performance, they simultaneously exacerbate privacy-leakage risks. Furthermore, this paper proposes a novel membership inference attack method based on the p-norm of feature vectors, termed the Embedding Lp-Norm Likelihood Attack (LpLA). This method infers membership status, by leveraging the statistical distribution characteristics of the p-norm of feature vectors. Experimental results across multiple datasets and model architectures demonstrate that LpLA outperforms existing methods in attack performance and robustness, particularly under limited attack knowledge and query volumes. This study not only uncovers the potential risks of privacy leakage in contrastive learning frameworks, but also provides a practical basis for privacy protection research in encoder models. We hope that this work will draw greater attention to the privacy risks associated with self-supervised learning models and shed light on the importance of a balance between model utility and training data privacy. Our code is publicly available at: https://github.com/SeroneySun/LpLA_code.