 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStructure-preserving Image Translation for Depth Estimation in Colonoscopy Video
Aug 19, 2024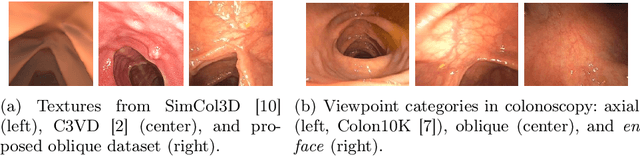
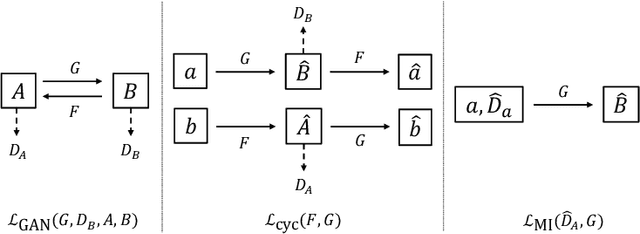


Monocular depth estimation in colonoscopy video aims to overcome the unusual lighting properties of the colonoscopic environment. One of the major challenges in this area is the domain gap between annotated but unrealistic synthetic data and unannotated but realistic clinical data. Previous attempts to bridge this domain gap directly target the depth estimation task itself. We propose a general pipeline of structure-preserving synthetic-to-real (sim2real) image translation (producing a modified version of the input image) to retain depth geometry through the translation process. This allows us to generate large quantities of realistic-looking synthetic images for supervised depth estimation with improved generalization to the clinical domain. We also propose a dataset of hand-picked sequences from clinical colonoscopies to improve the image translation process. We demonstrate the simultaneous realism of the translated images and preservation of depth maps via the performance of downstream depth estimation on various datasets.
Leveraging Near-Field Lighting for Monocular Depth Estimation from Endoscopy Videos
Mar 26, 2024



Monocular depth estimation in endoscopy videos can enable assistive and robotic surgery to obtain better coverage of the organ and detection of various health issues. Despite promising progress on mainstream, natural image depth estimation, techniques perform poorly on endoscopy images due to a lack of strong geometric features and challenging illumination effects. In this paper, we utilize the photometric cues, i.e., the light emitted from an endoscope and reflected by the surface, to improve monocular depth estimation. We first create two novel loss functions with supervised and self-supervised variants that utilize a per-pixel shading representation. We then propose a novel depth refinement network (PPSNet) that leverages the same per-pixel shading representation. Finally, we introduce teacher-student transfer learning to produce better depth maps from both synthetic data with supervision and clinical data with self-supervision. We achieve state-of-the-art results on the C3VD dataset while estimating high-quality depth maps from clinical data. Our code, pre-trained models, and supplementary materials can be found on our project page: https://ppsnet.github.io/
A Surface-normal Based Neural Framework for Colonoscopy Reconstruction
Mar 13, 2023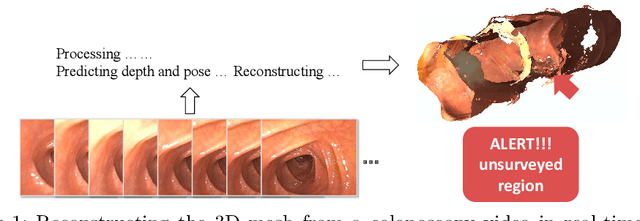
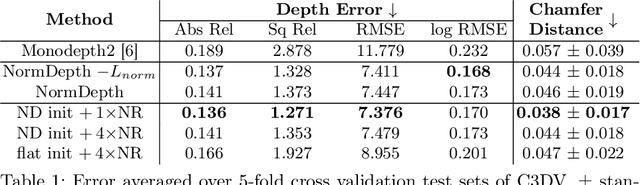
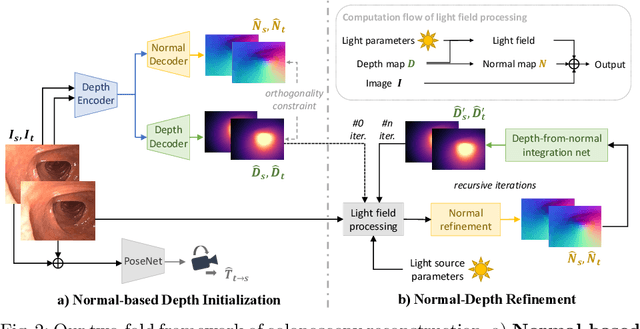
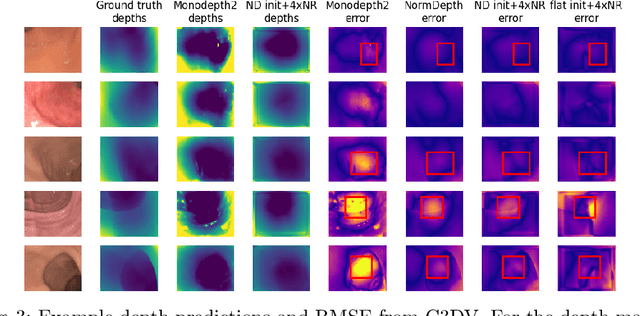
Reconstructing a 3D surface from colonoscopy video is challenging due to illumination and reflectivity variation in the video frame that can cause defective shape predictions. Aiming to overcome this challenge, we utilize the characteristics of surface normal vectors and develop a two-step neural framework that significantly improves the colonoscopy reconstruction quality. The normal-based depth initialization network trained with self-supervised normal consistency loss provides depth map initialization to the normal-depth refinement module, which utilizes the relationship between illumination and surface normals to refine the frame-wise normal and depth predictions recursively. Our framework's depth accuracy performance on phantom colonoscopy data demonstrates the value of exploiting the surface normals in colonoscopy reconstruction, especially on en face views. Due to its low depth error, the prediction result from our framework will require limited post-processing to be clinically applicable for real-time colonoscopy reconstruction.
ColDE: A Depth Estimation Framework for Colonoscopy Reconstruction
Nov 19, 2021
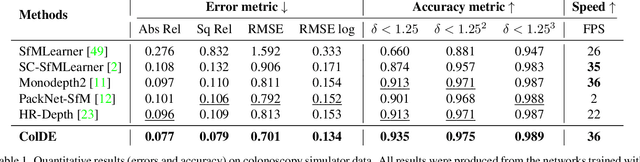
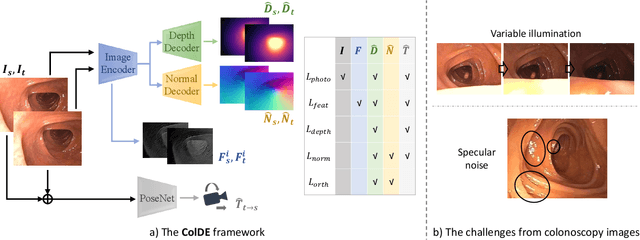
One of the key elements of reconstructing a 3D mesh from a monocular video is generating every frame's depth map. However, in the application of colonoscopy video reconstruction, producing good-quality depth estimation is challenging. Neural networks can be easily fooled by photometric distractions or fail to capture the complex shape of the colon surface, predicting defective shapes that result in broken meshes. Aiming to fundamentally improve the depth estimation quality for colonoscopy 3D reconstruction, in this work we have designed a set of training losses to deal with the special challenges of colonoscopy data. For better training, a set of geometric consistency objectives was developed, using both depth and surface normal information. Also, the classic photometric loss was extended with feature matching to compensate for illumination noise. With the training losses powerful enough, our self-supervised framework named ColDE is able to produce better depth maps of colonoscopy data as compared to the previous work utilizing prior depth knowledge. Used in reconstruction, our network is able to reconstruct good-quality colon meshes in real-time without any post-processing, making it the first to be clinically applicable.
Multi-Pair Two-Way Massive MIMO DF Relaying Over Rician Fading Channels Under Imperfect CSI
Oct 28, 2021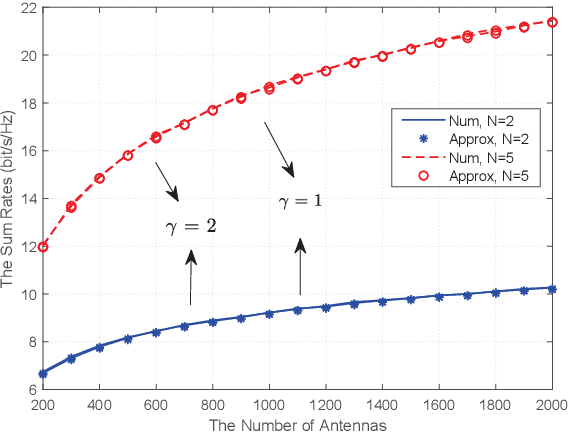
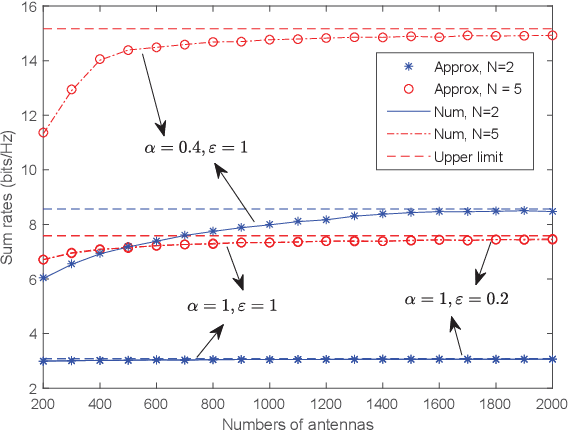
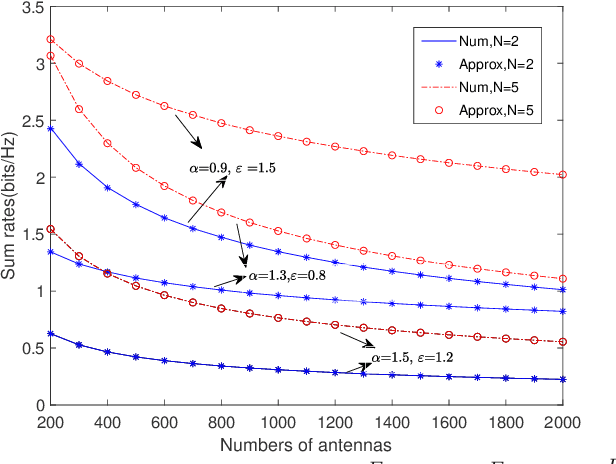
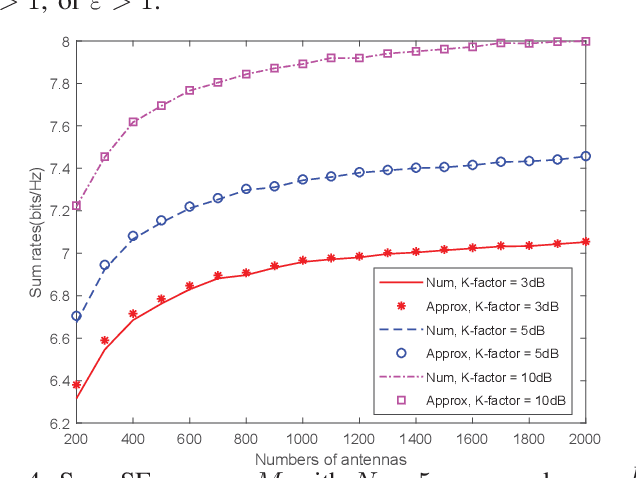
We investigate a multi-pair two-way decode-andforward relaying aided massive multiple-input multiple-output antenna system under Rician fading channels, in which multiple pairs of users exchange information through a relay station having multiple antennas. Imperfect channel state information is considered in the context of maximum-ratio processing. Closedform expressions are derived for approximating the sum spectral efficiency (SE) of the system. Moreover, we obtain the powerscaling laws at the users and the relay station to satisfy a certain SE requirement in three typical scenarios. Finally, simulations validate the accuracy of the derived results.
Lighting Enhancement Aids Reconstruction of Colonoscopic Surfaces
Mar 18, 2021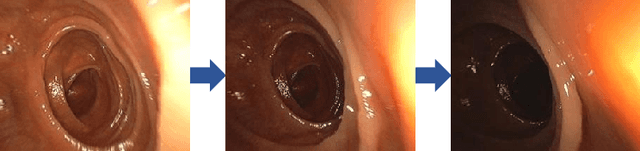
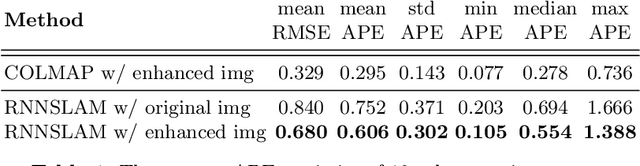

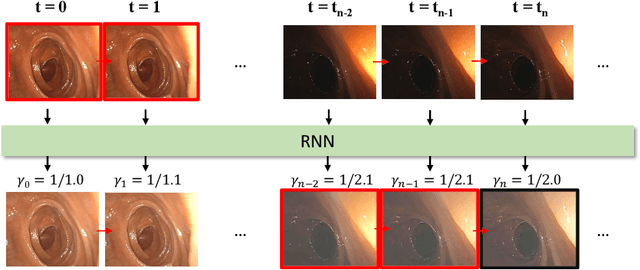
High screening coverage during colonoscopy is crucial to effectively prevent colon cancer. Previous work has allowed alerting the doctor to unsurveyed regions by reconstructing the 3D colonoscopic surface from colonoscopy videos in real-time. However, the lighting inconsistency of colonoscopy videos can cause a key component of the colonoscopic reconstruction system, the SLAM optimization, to fail. In this work we focus on the lighting problem in colonoscopy videos. To successfully improve the lighting consistency of colonoscopy videos, we have found necessary a lighting correction that adapts to the intensity distribution of recent video frames. To achieve this in real-time, we have designed and trained an RNN network. This network adapts the gamma value in a gamma-correction process. Applied in the colonoscopic surface reconstruction system, our light-weight model significantly boosts the reconstruction success rate, making a larger proportion of colonoscopy video segments reconstructable and improving the reconstruction quality of the already reconstructed segments.