 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePP-OCRv6: From 1.5M to 34.5M Parameters, Surpassing Billion-Scale VLMs on OCR Tasks
Jun 11, 2026Vision-Language Models (VLMs) have achieved impressive results on general vision-language tasks, yet they suffer from hallucination, imprecise localization, and prohibitive computational cost when applied to dedicated OCR scenarios. This paper presents PP-OCRv6, a lightweight OCR system that combines architectural innovation with data-centric optimization. PP-OCRv6 redesigns the backbone, detection neck, and recognition neck around a unified MetaFormer-style building block with structural reparameterization, decoupling spatial token mixing from channel mixing and supporting both tasks through task-specific stride configurations. Three model tiers (medium, small, tiny) share the same block primitives, covering deployment scenarios from server to edge. On our in-house benchmarks, PP-OCRv6_medium achieves 83.2% recognition accuracy and 86.2% detection Hmean, outperforming PP-OCRv5_server by +5.1% and +4.6% respectively while surpassing Qwen3-VL-235B, GPT-5.5, and Gemini-3.1-Pro with orders of magnitude fewer parameters. The tiny tier achieves 3.9$\times$ faster inference than PP-OCRv5_mobile on Intel Xeon CPU while maintaining comparable accuracy.
PaddleOCR-VL-1.6: Expanding the Frontier of Document Parsing with Under-Optimized Region Refinement and Progressive Post-Training
Jun 02, 2026We introduce PaddleOCR-VL-1.6, an upgraded compact document parsing model built upon PaddleOCR-VL-1.5. Although PaddleOCR-VL-1.5 establishes a strong 0.9B baseline, its remaining errors concentrate in under-optimized regions where model behavior is unstable, data coverage is sparse, or supervision is unreliable. Rather than expanding the training corpus indiscriminately, PaddleOCR-VL-1.6 introduces a region-aware data optimization framework that identifies weak regions from the previous model, applies targeted enhancement to these regions, and improves the reliability of supervision signals. It further adopts a progressive post-training recipe based on curated data selection and reinforcement learning, pushing model performance to a higher level through staged optimization. PaddleOCR-VL-1.6 achieves a new state-of-the-art score of 96.33% on OmniDocBench v1.6, demonstrates strong competitiveness against top-tier VLMs, and provides a practical post-training recipe for the PaddleOCR-VL series.
PP-OCRv5: A Specialized 5M-Parameter Model Rivaling Billion-Parameter Vision-Language Models on OCR Tasks
Mar 25, 2026The advent of "OCR 2.0" and large-scale vision-language models (VLMs) has set new benchmarks in text recognition. However, these unified architectures often come with significant computational demands, challenges in precise text localization within complex layouts, and a propensity for textual hallucinations. Revisiting the prevailing notion that model scale is the sole path to high accuracy, this paper introduces PP-OCRv5, a meticulously optimized, lightweight OCR system with merely 5 million parameters. We demonstrate that PP-OCRv5 achieves performance competitive with many billion-parameter VLMs on standard OCR benchmarks, while offering superior localization precision and reduced hallucinations. The cornerstone of our success lies not in architectural expansion but in a data-centric investigation. We systematically dissect the role of training data by quantifying three critical dimensions: data difficulty, data accuracy, and data diversity. Our extensive experiments reveal that with a sufficient volume of high-quality, accurately labeled, and diverse data, the performance ceiling for traditional, efficient two-stage OCR pipelines is far higher than commonly assumed. This work provides compelling evidence for the viability of lightweight, specialized models in the large-model era and offers practical insights into data curation for OCR. The source code and models are publicly available at https://github.com/PaddlePaddle/PaddleOCR.
Boosting Document Parsing Efficiency and Performance with Coarse-to-Fine Visual Processing
Mar 25, 2026Document parsing is a fine-grained task where image resolution significantly impacts performance. While advanced research leveraging vision-language models benefits from high-resolution input to boost model performance, this often leads to a quadratic increase in the number of vision tokens and significantly raises computational costs. We attribute this inefficiency to substantial visual regions redundancy in document images, like background. To tackle this, we propose PaddleOCR-VL, a novel coarse-to-fine architecture that focuses on semantically relevant regions while suppressing redundant ones, thereby improving both efficiency and performance. Specifically, we introduce a lightweight Valid Region Focus Module (VRFM) which leverages localization and contextual relationship prediction capabilities to identify valid vision tokens. Subsequently, we design and train a compact yet powerful 0.9B vision-language model (PaddleOCR-VL-0.9B) to perform detailed recognition, guided by VRFM outputs to avoid direct processing of the entire large image. Extensive experiments demonstrate that PaddleOCR-VL achieves state-of-the-art performance in both page-level parsing and element-level recognition. It significantly outperforms existing solutions, exhibits strong competitiveness against top-tier VLMs, and delivers fast inference while utilizing substantially fewer vision tokens and parameters, highlighting the effectiveness of targeted coarse-to-fine parsing for accurate and efficient document understanding. The source code and models are publicly available at https://github.com/PaddlePaddle/PaddleOCR.
ERNIE 5.0 Technical Report
Feb 04, 2026In this report, we introduce ERNIE 5.0, a natively autoregressive foundation model desinged for unified multimodal understanding and generation across text, image, video, and audio. All modalities are trained from scratch under a unified next-group-of-tokens prediction objective, based on an ultra-sparse mixture-of-experts (MoE) architecture with modality-agnostic expert routing. To address practical challenges in large-scale deployment under diverse resource constraints, ERNIE 5.0 adopts a novel elastic training paradigm. Within a single pre-training run, the model learns a family of sub-models with varying depths, expert capacities, and routing sparsity, enabling flexible trade-offs among performance, model size, and inference latency in memory- or time-constrained scenarios. Moreover, we systematically address the challenges of scaling reinforcement learning to unified foundation models, thereby guaranteeing efficient and stable post-training under ultra-sparse MoE architectures and diverse multimodal settings. Extensive experiments demonstrate that ERNIE 5.0 achieves strong and balanced performance across multiple modalities. To the best of our knowledge, among publicly disclosed models, ERNIE 5.0 represents the first production-scale realization of a trillion-parameter unified autoregressive model that supports both multimodal understanding and generation. To facilitate further research, we present detailed visualizations of modality-agnostic expert routing in the unified model, alongside comprehensive empirical analysis of elastic training, aiming to offer profound insights to the community.
PaddleOCR-VL-1.5: Towards a Multi-Task 0.9B VLM for Robust In-the-Wild Document Parsing
Jan 29, 2026We introduce PaddleOCR-VL-1.5, an upgraded model achieving a new state-of-the-art (SOTA) accuracy of 94.5% on OmniDocBench v1.5. To rigorously evaluate robustness against real-world physical distortions, including scanning, skew, warping, screen-photography, and illumination, we propose the Real5-OmniDocBench benchmark. Experimental results demonstrate that this enhanced model attains SOTA performance on the newly curated benchmark. Furthermore, we extend the model's capabilities by incorporating seal recognition and text spotting tasks, while remaining a 0.9B ultra-compact VLM with high efficiency. Code: https://github.com/PaddlePaddle/PaddleOCR
PaddleOCR-VL: Boosting Multilingual Document Parsing via a 0.9B Ultra-Compact Vision-Language Model
Oct 16, 2025In this report, we propose PaddleOCR-VL, a SOTA and resource-efficient model tailored for document parsing. Its core component is PaddleOCR-VL-0.9B, a compact yet powerful vision-language model (VLM) that integrates a NaViT-style dynamic resolution visual encoder with the ERNIE-4.5-0.3B language model to enable accurate element recognition. This innovative model efficiently supports 109 languages and excels in recognizing complex elements (e.g., text, tables, formulas, and charts), while maintaining minimal resource consumption. Through comprehensive evaluations on widely used public benchmarks and in-house benchmarks, PaddleOCR-VL achieves SOTA performance in both page-level document parsing and element-level recognition. It significantly outperforms existing solutions, exhibits strong competitiveness against top-tier VLMs, and delivers fast inference speeds. These strengths make it highly suitable for practical deployment in real-world scenarios.
Neural Tangent Knowledge Distillation for Optical Convolutional Networks
Aug 11, 2025Hybrid Optical Neural Networks (ONNs, typically consisting of an optical frontend and a digital backend) offer an energy-efficient alternative to fully digital deep networks for real-time, power-constrained systems. However, their adoption is limited by two main challenges: the accuracy gap compared to large-scale networks during training, and discrepancies between simulated and fabricated systems that further degrade accuracy. While previous work has proposed end-to-end optimizations for specific datasets (e.g., MNIST) and optical systems, these approaches typically lack generalization across tasks and hardware designs. To address these limitations, we propose a task-agnostic and hardware-agnostic pipeline that supports image classification and segmentation across diverse optical systems. To assist optical system design before training, we estimate achievable model accuracy based on user-specified constraints such as physical size and the dataset. For training, we introduce Neural Tangent Knowledge Distillation (NTKD), which aligns optical models with electronic teacher networks, thereby narrowing the accuracy gap. After fabrication, NTKD also guides fine-tuning of the digital backend to compensate for implementation errors. Experiments on multiple datasets (e.g., MNIST, CIFAR, Carvana Masking) and hardware configurations show that our pipeline consistently improves ONN performance and enables practical deployment in both pre-fabrication simulations and physical implementations.
RAG+: Enhancing Retrieval-Augmented Generation with Application-Aware Reasoning
Jun 13, 2025The integration of external knowledge through Retrieval-Augmented Generation (RAG) has become foundational in enhancing large language models (LLMs) for knowledge-intensive tasks. However, existing RAG paradigms often overlook the cognitive step of applying knowledge, leaving a gap between retrieved facts and task-specific reasoning. In this work, we introduce RAG+, a principled and modular extension that explicitly incorporates application-aware reasoning into the RAG pipeline. RAG+ constructs a dual corpus consisting of knowledge and aligned application examples, created either manually or automatically, and retrieves both jointly during inference. This design enables LLMs not only to access relevant information but also to apply it within structured, goal-oriented reasoning processes. Experiments across mathematical, legal, and medical domains, conducted on multiple models, demonstrate that RAG+ consistently outperforms standard RAG variants, achieving average improvements of 3-5%, and peak gains up to 7.5% in complex scenarios. By bridging retrieval with actionable application, RAG+ advances a more cognitively grounded framework for knowledge integration, representing a step toward more interpretable and capable LLMs.
Fair Dynamic Spectrum Access via Fully Decentralized Multi-Agent Reinforcement Learning
Mar 31, 2025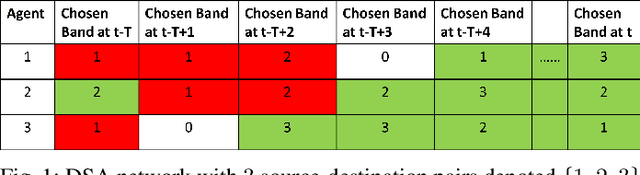
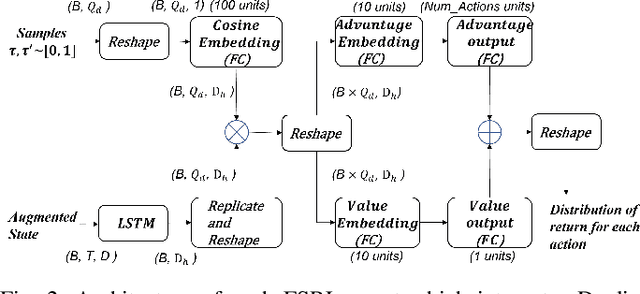
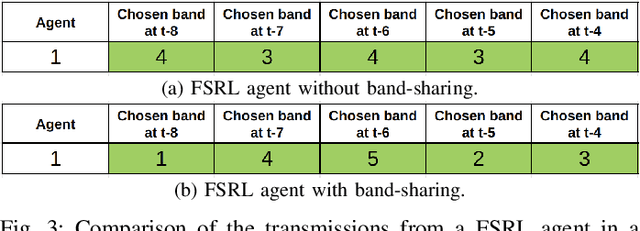
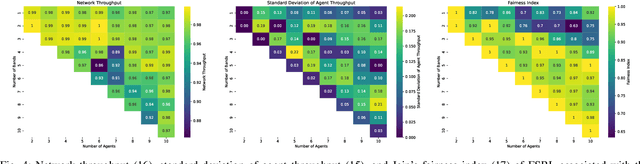
We consider a decentralized wireless network with several source-destination pairs sharing a limited number of orthogonal frequency bands. Sources learn to adapt their transmissions (specifically, their band selection strategy) over time, in a decentralized manner, without sharing information with each other. Sources can only observe the outcome of their own transmissions (i.e., success or collision), having no prior knowledge of the network size or of the transmission strategy of other sources. The goal of each source is to maximize their own throughput while striving for network-wide fairness. We propose a novel fully decentralized Reinforcement Learning (RL)-based solution that achieves fairness without coordination. The proposed Fair Share RL (FSRL) solution combines: (i) state augmentation with a semi-adaptive time reference; (ii) an architecture that leverages risk control and time difference likelihood; and (iii) a fairness-driven reward structure. We evaluate FSRL in more than 50 network settings with different number of agents, different amounts of available spectrum, in the presence of jammers, and in an ad-hoc setting. Simulation results suggest that, when we compare FSRL with a common baseline RL algorithm from the literature, FSRL can be up to 89.0% fairer (as measured by Jain's fairness index) in stringent settings with several sources and a single frequency band, and 48.1% fairer on average.