 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrequency-Based Alignment of EEG and Audio Signals Using Contrastive Learning and SincNet for Auditory Attention Detection
Mar 06, 2025Humans exhibit a remarkable ability to focus auditory attention in complex acoustic environments, such as cocktail parties. Auditory attention detection (AAD) aims to identify the attended speaker by analyzing brain signals, such as electroencephalography (EEG) data. Existing AAD algorithms often leverage deep learning's powerful nonlinear modeling capabilities, few consider the neural mechanisms underlying auditory processing in the brain. In this paper, we propose SincAlignNet, a novel network based on an improved SincNet and contrastive learning, designed to align audio and EEG features for auditory attention detection. The SincNet component simulates the brain's processing of audio during auditory attention, while contrastive learning guides the model to learn the relationship between EEG signals and attended speech. During inference, we calculate the cosine similarity between EEG and audio features and also explore direct inference of the attended speaker using EEG data. Cross-trial evaluations results demonstrate that SincAlignNet outperforms state-of-the-art AAD methods on two publicly available datasets, KUL and DTU, achieving average accuracies of 78.3% and 92.2%, respectively, with a 1-second decision window. The model exhibits strong interpretability, revealing that the left and right temporal lobes are more active during both male and female speaker scenarios. Furthermore, we found that using data from only six electrodes near the temporal lobes maintains similar or even better performance compared to using 64 electrodes. These findings indicate that efficient low-density EEG online decoding is achievable, marking an important step toward the practical implementation of neuro-guided hearing aids in real-world applications. Code is available at: https://github.com/LiaoEuan/SincAlignNet.
Towards Automated Data Sciences with Natural Language and SageCopilot: Practices and Lessons Learned
Jul 21, 2024



While the field of NL2SQL has made significant advancements in translating natural language instructions into executable SQL scripts for data querying and processing, achieving full automation within the broader data science pipeline - encompassing data querying, analysis, visualization, and reporting - remains a complex challenge. This study introduces SageCopilot, an advanced, industry-grade system system that automates the data science pipeline by integrating Large Language Models (LLMs), Autonomous Agents (AutoAgents), and Language User Interfaces (LUIs). Specifically, SageCopilot incorporates a two-phase design: an online component refining users' inputs into executable scripts through In-Context Learning (ICL) and running the scripts for results reporting & visualization, and an offline preparing demonstrations requested by ICL in the online phase. A list of trending strategies such as Chain-of-Thought and prompt-tuning have been used to augment SageCopilot for enhanced performance. Through rigorous testing and comparative analysis against prompt-based solutions, SageCopilot has been empirically validated to achieve superior end-to-end performance in generating or executing scripts and offering results with visualization, backed by real-world datasets. Our in-depth ablation studies highlight the individual contributions of various components and strategies used by SageCopilot to the end-to-end correctness for data sciences.
CLDTA: Contrastive Learning based on Diagonal Transformer Autoencoder for Cross-Dataset EEG Emotion Recognition
Jun 12, 2024



Recent advances in non-invasive EEG technology have broadened its application in emotion recognition, yielding a multitude of related datasets. Yet, deep learning models struggle to generalize across these datasets due to variations in acquisition equipment and emotional stimulus materials. To address the pressing need for a universal model that fluidly accommodates diverse EEG dataset formats and bridges the gap between laboratory and real-world data, we introduce a novel deep learning framework: the Contrastive Learning based Diagonal Transformer Autoencoder (CLDTA), tailored for EEG-based emotion recognition. The CLDTA employs a diagonal masking strategy within its encoder to extracts full-channel EEG data's brain network knowledge, facilitating transferability to the datasets with fewer channels. And an information separation mechanism improves model interpretability by enabling straightforward visualization of brain networks. The CLDTA framework employs contrastive learning to distill subject-independent emotional representations and uses a calibration prediction process to enable rapid adaptation of the model to new subjects with minimal samples, achieving accurate emotion recognition. Our analysis across the SEED, SEED-IV, SEED-V, and DEAP datasets highlights CLDTA's consistent performance and proficiency in detecting both task-specific and general features of EEG signals related to emotions, underscoring its potential to revolutionize emotion recognition research.
Torch2Chip: An End-to-end Customizable Deep Neural Network Compression and Deployment Toolkit for Prototype Hardware Accelerator Design
May 06, 2024



The development of model compression is continuously motivated by the evolution of various neural network accelerators with ASIC or FPGA. On the algorithm side, the ultimate goal of quantization or pruning is accelerating the expensive DNN computations on low-power hardware. However, such a "design-and-deploy" workflow faces under-explored challenges in the current hardware-algorithm co-design community. First, although the state-of-the-art quantization algorithm can achieve low precision with negligible degradation of accuracy, the latest deep learning framework (e.g., PyTorch) can only support non-customizable 8-bit precision, data format, and parameter extraction. Secondly, the objective of quantization is to enable the computation with low-precision data. However, the current SoTA algorithm treats the quantized integer as an intermediate result, while the final output of the quantizer is the "discretized" floating-point values, ignoring the practical needs and adding additional workload to hardware designers for integer parameter extraction and layer fusion. Finally, the compression toolkits designed by the industry are constrained to their in-house product or a handful of algorithms. The limited degree of freedom in the current toolkit and the under-explored customization hinder the prototype ASIC or FPGA-based accelerator design. To resolve these challenges, we propose Torch2Chip, an open-sourced, fully customizable, and high-performance toolkit that supports user-designed compression followed by automatic model fusion and parameter extraction. Torch2Chip incorporates the hierarchical design workflow, and the user-customized compression algorithm will be directly packed into the deployment-ready format for prototype chip verification with either CNN or vision transformer (ViT). The code is available at https://github.com/SeoLabCornell/torch2chip.
SGMM: Stochastic Approximation to Generalized Method of Moments
Aug 25, 2023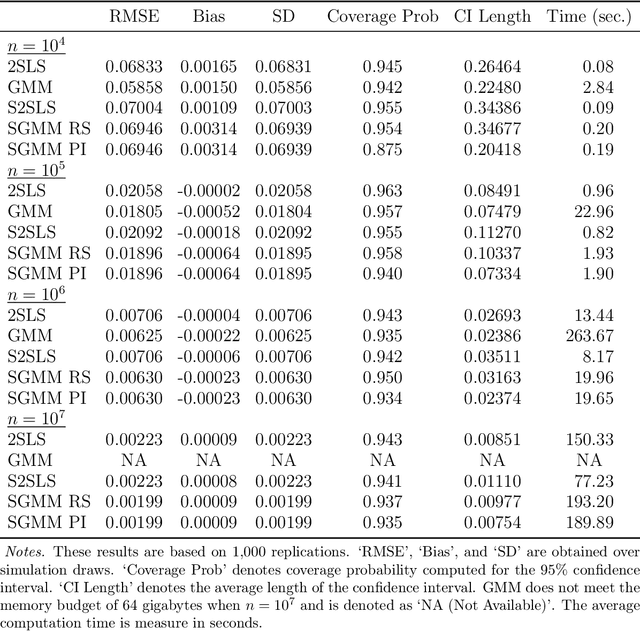
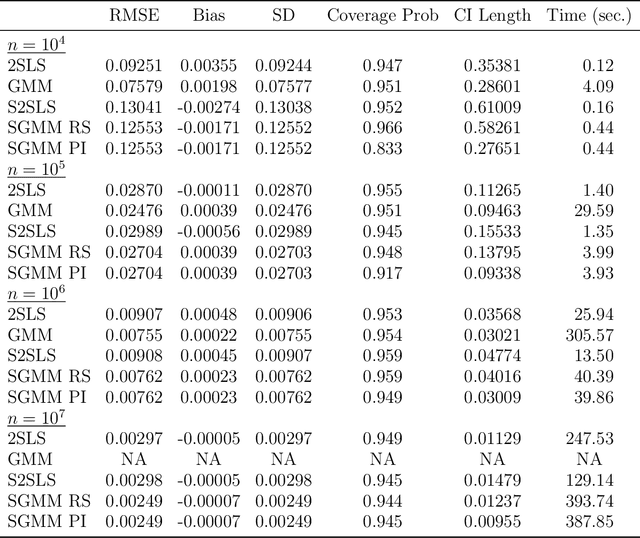
We introduce a new class of algorithms, Stochastic Generalized Method of Moments (SGMM), for estimation and inference on (overidentified) moment restriction models. Our SGMM is a novel stochastic approximation alternative to the popular Hansen (1982) (offline) GMM, and offers fast and scalable implementation with the ability to handle streaming datasets in real time. We establish the almost sure convergence, and the (functional) central limit theorem for the inefficient online 2SLS and the efficient SGMM. Moreover, we propose online versions of the Durbin-Wu-Hausman and Sargan-Hansen tests that can be seamlessly integrated within the SGMM framework. Extensive Monte Carlo simulations show that as the sample size increases, the SGMM matches the standard (offline) GMM in terms of estimation accuracy and gains over computational efficiency, indicating its practical value for both large-scale and online datasets. We demonstrate the efficacy of our approach by a proof of concept using two well known empirical examples with large sample sizes.
Inference on Time Series Nonparametric Conditional Moment Restrictions Using General Sieves
Jan 03, 2023General nonlinear sieve learnings are classes of nonlinear sieves that can approximate nonlinear functions of high dimensional variables much more flexibly than various linear sieves (or series). This paper considers general nonlinear sieve quasi-likelihood ratio (GN-QLR) based inference on expectation functionals of time series data, where the functionals of interest are based on some nonparametric function that satisfy conditional moment restrictions and are learned using multilayer neural networks. While the asymptotic normality of the estimated functionals depends on some unknown Riesz representer of the functional space, we show that the optimally weighted GN-QLR statistic is asymptotically Chi-square distributed, regardless whether the expectation functional is regular (root-$n$ estimable) or not. This holds when the data are weakly dependent beta-mixing condition. We apply our method to the off-policy evaluation in reinforcement learning, by formulating the Bellman equation into the conditional moment restriction framework, so that we can make inference about the state-specific value functional using the proposed GN-QLR method with time series data. In addition, estimating the averaged partial means and averaged partial derivatives of nonparametric instrumental variables and quantile IV models are also presented as leading examples. Finally, a Monte Carlo study shows the finite sample performance of the procedure
Fast and Robust Online Inference with Stochastic Gradient Descent via Random Scaling
Jun 21, 2021
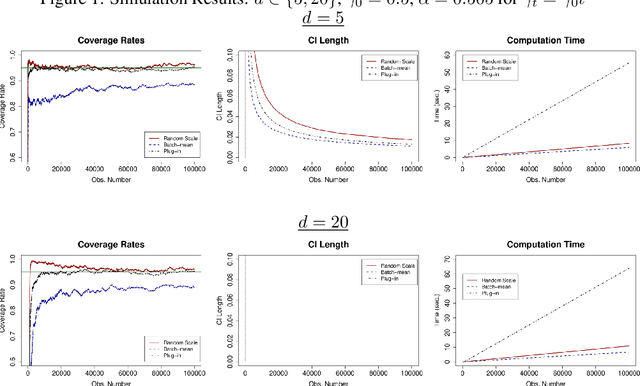
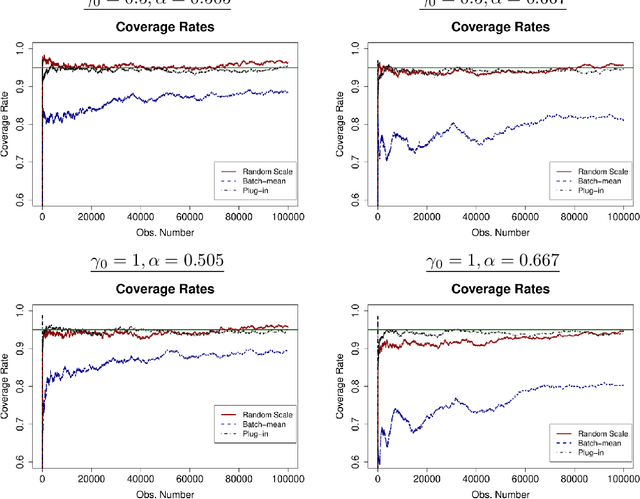
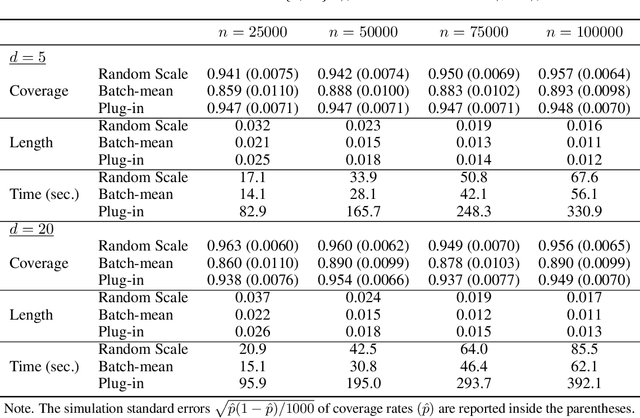
We develop a new method of online inference for a vector of parameters estimated by the Polyak-Ruppert averaging procedure of stochastic gradient descent (SGD) algorithms. We leverage insights from time series regression in econometrics and construct asymptotically pivotal statistics via random scaling. Our approach is fully operational with online data and is rigorously underpinned by a functional central limit theorem. Our proposed inference method has a couple of key advantages over the existing methods. First, the test statistic is computed in an online fashion with only SGD iterates and the critical values can be obtained without any resampling methods, thereby allowing for efficient implementation suitable for massive online data. Second, there is no need to estimate the asymptotic variance and our inference method is shown to be robust to changes in the tuning parameters for SGD algorithms in simulation experiments with synthetic data.
Energy and Age Pareto Optimal Trajectories in UAV-assisted Wireless Data Collection
Jun 07, 2021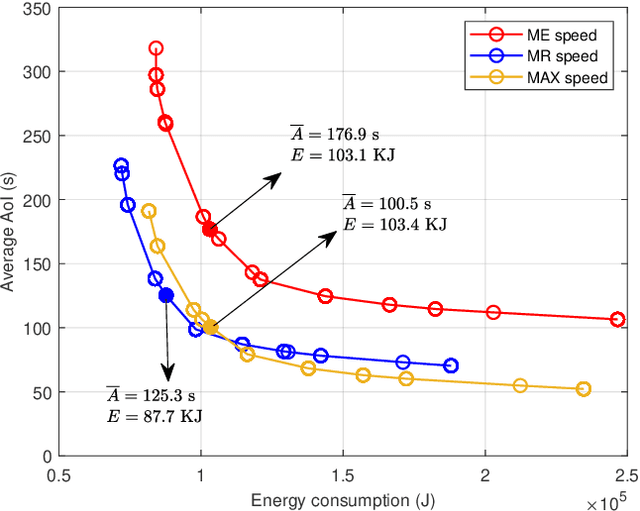
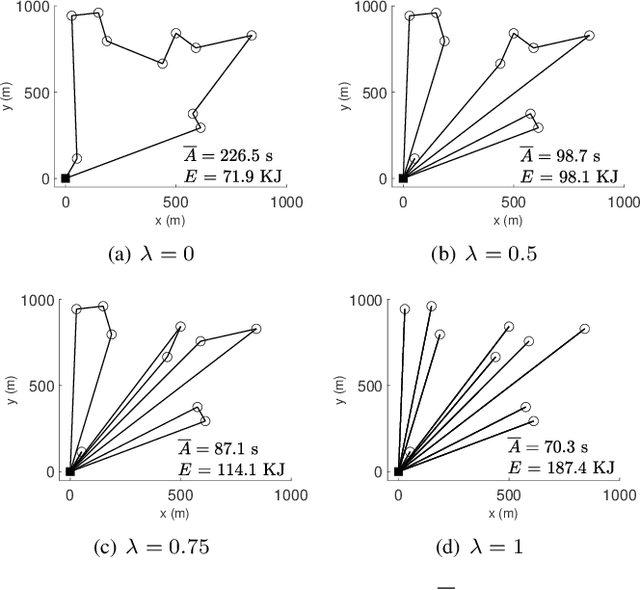
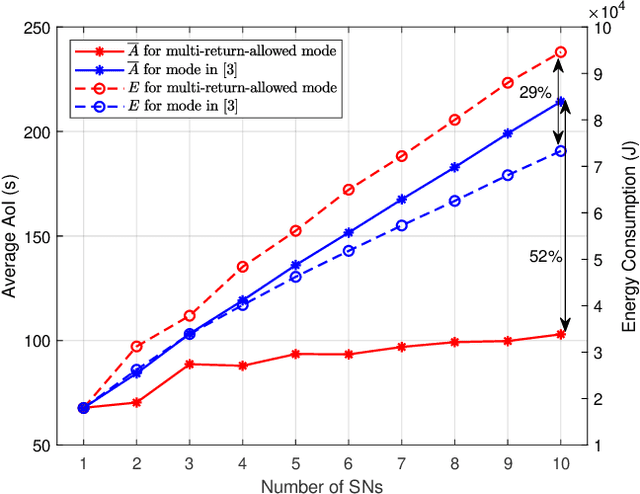

This paper studies an unmanned aerial vehicle (UAV)-assisted wireless network, where a UAV is dispatched to gather information from ground sensor nodes (SN) and transfer the collected data to the depot. The information freshness is captured by the age of information (AoI) metric, whilst the energy consumption of the UAV is seen as another performance criterion. Most importantly, the AoI and energy efficiency are inherently competing metrics, since decreasing the AoI requires the UAV returning to the depot more frequently, leading to a higher energy consumption. To this end, we design UAV paths that optimize these two competing metrics and reveal the Pareto frontier. To formulate this problem, a multi-objective mixed integer linear programming (MILP) is proposed with a flow-based constraint set and we apply Bender's decomposition on the proposed formulation. The overall outcome shows that the proposed method allows deriving non-dominated solutions for decision making for UAV based wireless data collection. Numerical results are provided to corroborate our study by presenting the Pareto front of the two objectives and the effect on the UAV trajectory.
Recent Developments on Factor Models and its Applications in Econometric Learning
Sep 21, 2020

This paper makes a selective survey on the recent development of the factor model and its application on statistical learnings. We focus on the perspective of the low-rank structure of factor models, and particularly draws attentions to estimating the model from the low-rank recovery point of view. The survey mainly consists of three parts: the first part is a review on new factor estimations based on modern techniques on recovering low-rank structures of high-dimensional models. The second part discusses statistical inferences of several factor-augmented models and applications in econometric learning models. The final part summarizes new developments dealing with unbalanced panels from the matrix completion perspective.