 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeProbabilistic Occupancy Grid for Radio-Based SLAM
Mar 03, 2026Sensing is an integral part of 6G and beyond systems, providing exceptional environmental perception along with communication. RF-based sensing often relies on simplified geometric assumptions (e.g., point scatterers or planar surfaces) to model specular multipath and keep inference tractable. However, such representations are not physically informative and fail to accurately capture extended objects with complex shapes and properties. This paper presents a probabilistic occupancy grid framework for radio-based simultaneous localization and mapping (SLAM), jointly reconstructing geometric structures and their radio-related properties. The proposed occupancy grid map representation is integrated into a multipath-based SLAM (MP-SLAM) formulation to enable simultaneous mobile-agent localization and environment mapping using multipath measurements. To connect RF measurements with the grid map, a surface model is employed to describe candidate reflection paths, while occupancy grid cell states capture measurement uncertainties and fine--grained geometric details. Object RF-related properties are modeled via reflection coefficients. The proposed framework offers a principled, proof-of-concept approach to physically interpretable radio-based mapping, and simulation results demonstrate accurate reconstruction of geometry and material properties, as well as high-accuracy localization. In addition, the results highlight the potential to use prior occupancy maps obtained from other radio devices or complementary sensors for subsequent map extension and refinement.
ERNIE 5.0 Technical Report
Feb 04, 2026In this report, we introduce ERNIE 5.0, a natively autoregressive foundation model desinged for unified multimodal understanding and generation across text, image, video, and audio. All modalities are trained from scratch under a unified next-group-of-tokens prediction objective, based on an ultra-sparse mixture-of-experts (MoE) architecture with modality-agnostic expert routing. To address practical challenges in large-scale deployment under diverse resource constraints, ERNIE 5.0 adopts a novel elastic training paradigm. Within a single pre-training run, the model learns a family of sub-models with varying depths, expert capacities, and routing sparsity, enabling flexible trade-offs among performance, model size, and inference latency in memory- or time-constrained scenarios. Moreover, we systematically address the challenges of scaling reinforcement learning to unified foundation models, thereby guaranteeing efficient and stable post-training under ultra-sparse MoE architectures and diverse multimodal settings. Extensive experiments demonstrate that ERNIE 5.0 achieves strong and balanced performance across multiple modalities. To the best of our knowledge, among publicly disclosed models, ERNIE 5.0 represents the first production-scale realization of a trillion-parameter unified autoregressive model that supports both multimodal understanding and generation. To facilitate further research, we present detailed visualizations of modality-agnostic expert routing in the unified model, alongside comprehensive empirical analysis of elastic training, aiming to offer profound insights to the community.
AERO: Autonomous Evolutionary Reasoning Optimization via Endogenous Dual-Loop Feedback
Feb 03, 2026Large Language Models (LLMs) have achieved significant success in complex reasoning but remain bottlenecked by reliance on expert-annotated data and external verifiers. While existing self-evolution paradigms aim to bypass these constraints, they often fail to identify the optimal learning zone and risk reinforcing collective hallucinations and incorrect priors through flawed internal feedback. To address these challenges, we propose \underline{A}utonomous \underline{E}volutionary \underline{R}easoning \underline{O}ptimization (AERO), an unsupervised framework that achieves autonomous reasoning evolution by internalizing self-questioning, answering, and criticism within a synergistic dual-loop system. Inspired by the \textit{Zone of Proximal Development (ZPD)} theory, AERO utilizes entropy-based positioning to target the ``solvability gap'' and employs Independent Counterfactual Correction for robust verification. Furthermore, we introduce a Staggered Training Strategy to synchronize capability growth across functional roles and prevent curriculum collapse. Extensive evaluations across nine benchmarks spanning three domains demonstrate that AERO achieves average performance improvements of 4.57\% on Qwen3-4B-Base and 5.10\% on Qwen3-8B-Base, outperforming competitive baselines. Code is available at https://github.com/mira-ai-lab/AERO.
From Macro to Micro: Probing Dataset Diversity in Language Model Fine-Tuning
May 30, 2025Dataset diversity plays a pivotal role for the successful training of many machine learning models, particularly in the supervised fine-tuning (SFT) stage of large language model (LLM) development. Despite increasing recognition of its importance, systematic analyses of dataset diversity still remain underexplored. To address this gap, this work presents a systematic taxonomy of existing diversity-control strategies, which primarily focus on the instruction component, operating at either macroscopic (entire instruction semantics) or mesoscopic levels (instruction units), and furthermore introduces a novel analysis of microscopic diversity within the response component, specifically analyzing the statistical distribution of tokens in SFT training samples. In the experimental evaluation, we construct fixed-size datasets (e.g., 10,000 samples each) from a corpus of 117,000 open-source SFT samples, incorporating six distinct diversity-control strategies spanning macro-, meso-, and microscopic levels applied to both instructions and responses. We then fine-tune LLMs on these datasets to assess the six diversity-control strategies. Results reveal that while macroscopic and mesoscopic strategies lead to higher performance with increasing diversity, the microscopic strategy in responses exhibits both a stronger correlation between model performance and the degree of diversity and superior performance with maximum diversity across all strategies. These findings offer actionable insights for constructing high-performance SFT datasets.
SOLA-GCL: Subgraph-Oriented Learnable Augmentation Method for Graph Contrastive Learning
Mar 13, 2025Graph contrastive learning has emerged as a powerful technique for learning graph representations that are robust and discriminative. However, traditional approaches often neglect the critical role of subgraph structures, particularly the intra-subgraph characteristics and inter-subgraph relationships, which are crucial for generating informative and diverse contrastive pairs. These subgraph features are crucial as they vary significantly across different graph types, such as social networks where they represent communities, and biochemical networks where they symbolize molecular interactions. To address this issue, our work proposes a novel subgraph-oriented learnable augmentation method for graph contrastive learning, termed SOLA-GCL, that centers around subgraphs, taking full advantage of the subgraph information for data augmentation. Specifically, SOLA-GCL initially partitions a graph into multiple densely connected subgraphs based on their intrinsic properties. To preserve and enhance the unique characteristics inherent to subgraphs, a graph view generator optimizes augmentation strategies for each subgraph, thereby generating tailored views for graph contrastive learning. This generator uses a combination of intra-subgraph and inter-subgraph augmentation strategies, including node dropping, feature masking, intra-edge perturbation, inter-edge perturbation, and subgraph swapping. Extensive experiments have been conducted on various graph learning applications, ranging from social networks to molecules, under semi-supervised learning, unsupervised learning, and transfer learning settings to demonstrate the superiority of our proposed approach over the state-of-the-art in GCL.
Pre-trained Molecular Language Models with Random Functional Group Masking
Nov 03, 2024



Recent advancements in computational chemistry have leveraged the power of trans-former-based language models, such as MoLFormer, pre-trained using a vast amount of simplified molecular-input line-entry system (SMILES) sequences, to understand and predict molecular properties and activities, a critical step in fields like drug discovery and materials science. To further improve performance, researchers have introduced graph neural networks with graph-based molecular representations, such as GEM, incorporating the topology, geometry, 2D or even 3D structures of molecules into pre-training. While most of molecular graphs in existing studies were automatically converted from SMILES sequences, it is to assume that transformer-based language models might be able to implicitly learn structure-aware representations from SMILES sequences. In this paper, we propose \ours{} -- a SMILES-based \underline{\em M}olecular \underline{\em L}anguage \underline{\em M}odel, which randomly masking SMILES subsequences corresponding to specific molecular \underline{\em F}unctional \underline{\em G}roups to incorporate structure information of atoms during the pre-training phase. This technique aims to compel the model to better infer molecular structures and properties, thus enhancing its predictive capabilities. Extensive experimental evaluations across 11 benchmark classification and regression tasks in the chemical domain demonstrate the robustness and superiority of \ours{}. Our findings reveal that \ours{} outperforms existing pre-training models, either based on SMILES or graphs, in 9 out of the 11 downstream tasks, ranking as a close second in the remaining ones.
Towards Automated Data Sciences with Natural Language and SageCopilot: Practices and Lessons Learned
Jul 21, 2024



While the field of NL2SQL has made significant advancements in translating natural language instructions into executable SQL scripts for data querying and processing, achieving full automation within the broader data science pipeline - encompassing data querying, analysis, visualization, and reporting - remains a complex challenge. This study introduces SageCopilot, an advanced, industry-grade system system that automates the data science pipeline by integrating Large Language Models (LLMs), Autonomous Agents (AutoAgents), and Language User Interfaces (LUIs). Specifically, SageCopilot incorporates a two-phase design: an online component refining users' inputs into executable scripts through In-Context Learning (ICL) and running the scripts for results reporting & visualization, and an offline preparing demonstrations requested by ICL in the online phase. A list of trending strategies such as Chain-of-Thought and prompt-tuning have been used to augment SageCopilot for enhanced performance. Through rigorous testing and comparative analysis against prompt-based solutions, SageCopilot has been empirically validated to achieve superior end-to-end performance in generating or executing scripts and offering results with visualization, backed by real-world datasets. Our in-depth ablation studies highlight the individual contributions of various components and strategies used by SageCopilot to the end-to-end correctness for data sciences.
Converging Paradigms: The Synergy of Symbolic and Connectionist AI in LLM-Empowered Autonomous Agents
Jul 11, 2024



This article explores the convergence of connectionist and symbolic artificial intelligence (AI), from historical debates to contemporary advancements. Traditionally considered distinct paradigms, connectionist AI focuses on neural networks, while symbolic AI emphasizes symbolic representation and logic. Recent advancements in large language models (LLMs), exemplified by ChatGPT and GPT-4, highlight the potential of connectionist architectures in handling human language as a form of symbols. The study argues that LLM-empowered Autonomous Agents (LAAs) embody this paradigm convergence. By utilizing LLMs for text-based knowledge modeling and representation, LAAs integrate neuro-symbolic AI principles, showcasing enhanced reasoning and decision-making capabilities. Comparing LAAs with Knowledge Graphs within the neuro-symbolic AI theme highlights the unique strengths of LAAs in mimicking human-like reasoning processes, scaling effectively with large datasets, and leveraging in-context samples without explicit re-training. The research underscores promising avenues in neuro-vector-symbolic integration, instructional encoding, and implicit reasoning, aimed at further enhancing LAA capabilities. By exploring the progression of neuro-symbolic AI and proposing future research trajectories, this work advances the understanding and development of AI technologies.
When Search Engine Services meet Large Language Models: Visions and Challenges
Jun 28, 2024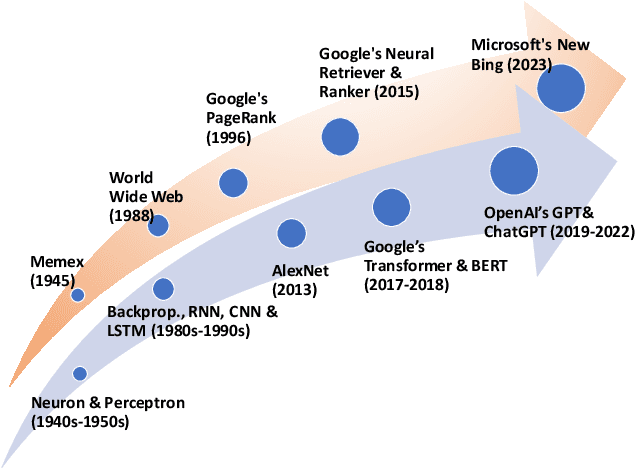
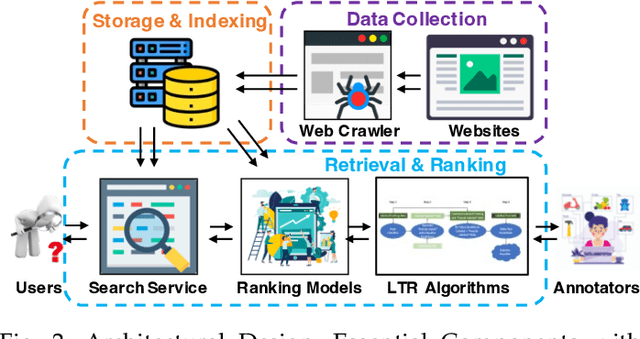
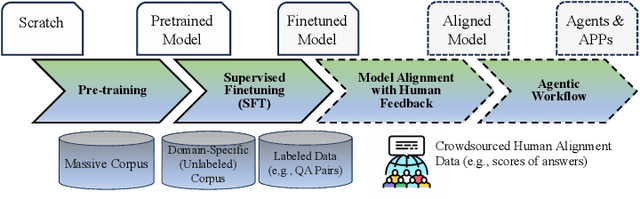
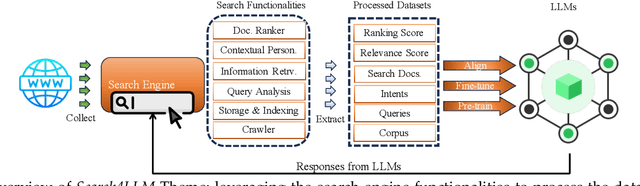
Combining Large Language Models (LLMs) with search engine services marks a significant shift in the field of services computing, opening up new possibilities to enhance how we search for and retrieve information, understand content, and interact with internet services. This paper conducts an in-depth examination of how integrating LLMs with search engines can mutually benefit both technologies. We focus on two main areas: using search engines to improve LLMs (Search4LLM) and enhancing search engine functions using LLMs (LLM4Search). For Search4LLM, we investigate how search engines can provide diverse high-quality datasets for pre-training of LLMs, how they can use the most relevant documents to help LLMs learn to answer queries more accurately, how training LLMs with Learning-To-Rank (LTR) tasks can enhance their ability to respond with greater precision, and how incorporating recent search results can make LLM-generated content more accurate and current. In terms of LLM4Search, we examine how LLMs can be used to summarize content for better indexing by search engines, improve query outcomes through optimization, enhance the ranking of search results by analyzing document relevance, and help in annotating data for learning-to-rank tasks in various learning contexts. However, this promising integration comes with its challenges, which include addressing potential biases and ethical issues in training models, managing the computational and other costs of incorporating LLMs into search services, and continuously updating LLM training with the ever-changing web content. We discuss these challenges and chart out required research directions to address them. We also discuss broader implications for service computing, such as scalability, privacy concerns, and the need to adapt search engine architectures for these advanced models.
Tokenization Falling Short: The Curse of Tokenization
Jun 17, 2024Language models typically tokenize raw text into sequences of subword identifiers from a predefined vocabulary, a process inherently sensitive to typographical errors, length variations, and largely oblivious to the internal structure of tokens-issues we term the curse of tokenization. In this study, we delve into these drawbacks and demonstrate that large language models (LLMs) remain susceptible to these problems. This study systematically investigates these challenges and their impact on LLMs through three critical research questions: (1) complex problem solving, (2) token structure probing, and (3) resilience to typographical variation. Our findings reveal that scaling model parameters can mitigate the issue of tokenization; however, LLMs still suffer from biases induced by typos and other text format variations. Our experiments show that subword regularization such as BPE-dropout can mitigate this issue. We will release our code and data to facilitate further research.