 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhen Search Engine Services meet Large Language Models: Visions and Challenges
Paper and Code
Jun 28, 2024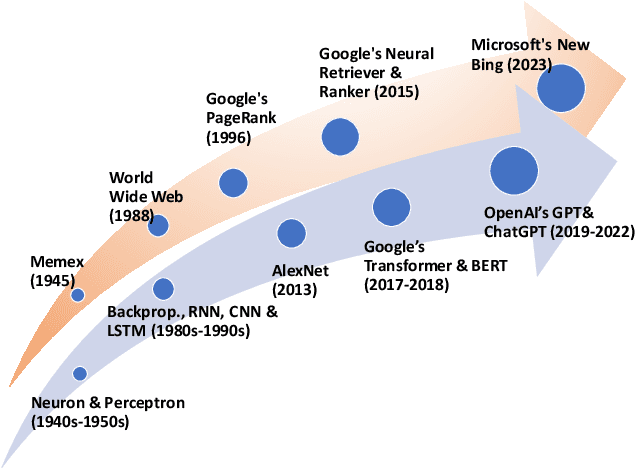
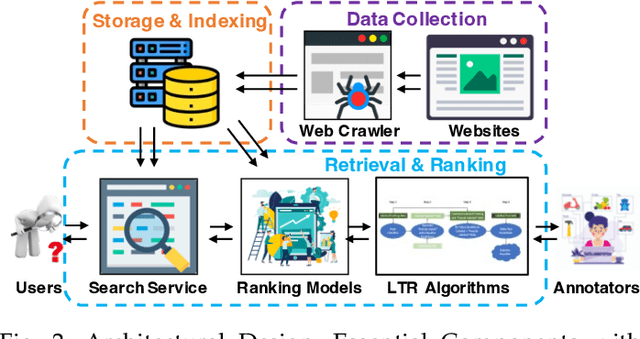
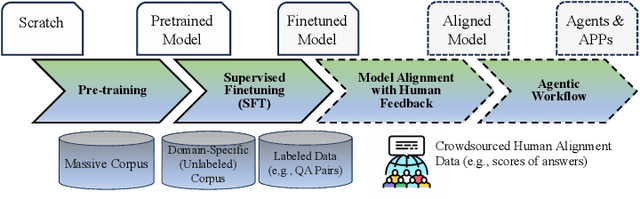
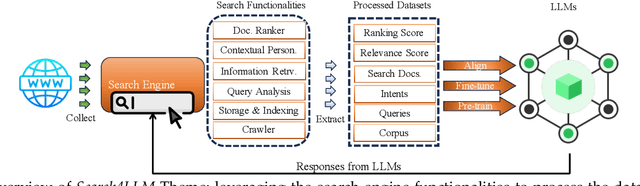
Combining Large Language Models (LLMs) with search engine services marks a significant shift in the field of services computing, opening up new possibilities to enhance how we search for and retrieve information, understand content, and interact with internet services. This paper conducts an in-depth examination of how integrating LLMs with search engines can mutually benefit both technologies. We focus on two main areas: using search engines to improve LLMs (Search4LLM) and enhancing search engine functions using LLMs (LLM4Search). For Search4LLM, we investigate how search engines can provide diverse high-quality datasets for pre-training of LLMs, how they can use the most relevant documents to help LLMs learn to answer queries more accurately, how training LLMs with Learning-To-Rank (LTR) tasks can enhance their ability to respond with greater precision, and how incorporating recent search results can make LLM-generated content more accurate and current. In terms of LLM4Search, we examine how LLMs can be used to summarize content for better indexing by search engines, improve query outcomes through optimization, enhance the ranking of search results by analyzing document relevance, and help in annotating data for learning-to-rank tasks in various learning contexts. However, this promising integration comes with its challenges, which include addressing potential biases and ethical issues in training models, managing the computational and other costs of incorporating LLMs into search services, and continuously updating LLM training with the ever-changing web content. We discuss these challenges and chart out required research directions to address them. We also discuss broader implications for service computing, such as scalability, privacy concerns, and the need to adapt search engine architectures for these advanced models.