 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAlignment of Diffusion Models: Fundamentals, Challenges, and Future
Sep 12, 2024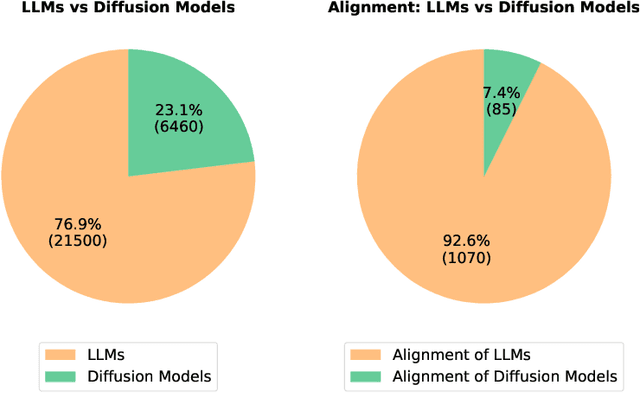
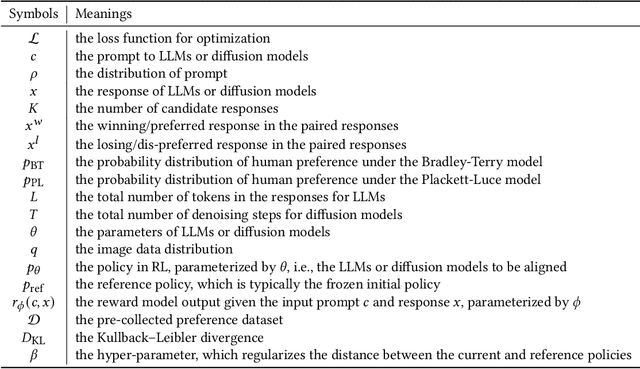
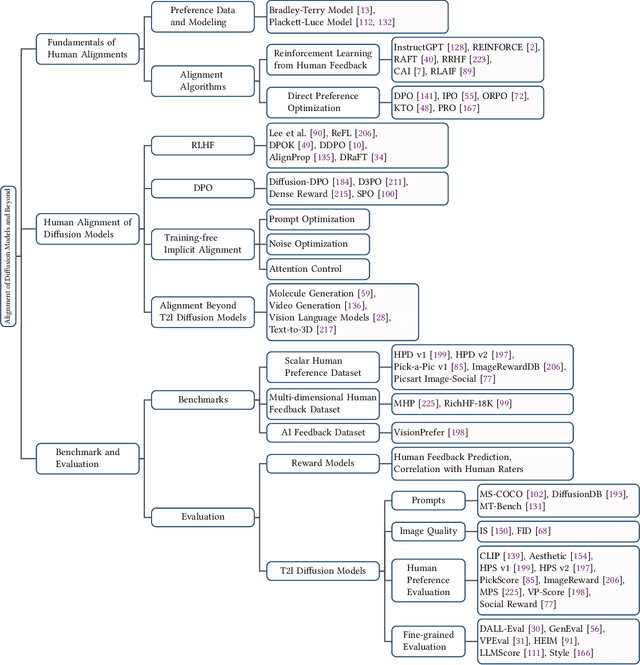
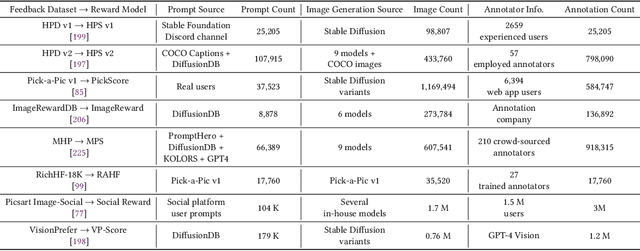
Diffusion models have emerged as the leading paradigm in generative modeling, excelling in various applications. Despite their success, these models often misalign with human intentions, generating outputs that may not match text prompts or possess desired properties. Inspired by the success of alignment in tuning large language models, recent studies have investigated aligning diffusion models with human expectations and preferences. This work mainly reviews alignment of diffusion models, covering advancements in fundamentals of alignment, alignment techniques of diffusion models, preference benchmarks, and evaluation for diffusion models. Moreover, we discuss key perspectives on current challenges and promising future directions on solving the remaining challenges in alignment of diffusion models. To the best of our knowledge, our work is the first comprehensive review paper for researchers and engineers to comprehend, practice, and research alignment of diffusion models.
When Search Engine Services meet Large Language Models: Visions and Challenges
Jun 28, 2024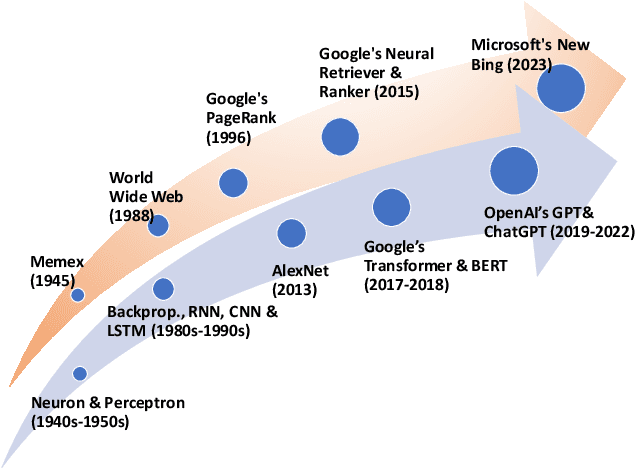
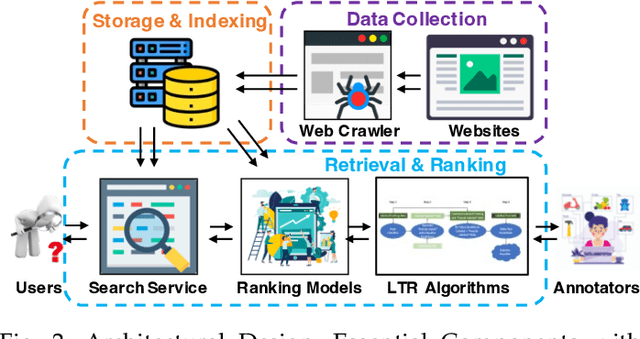
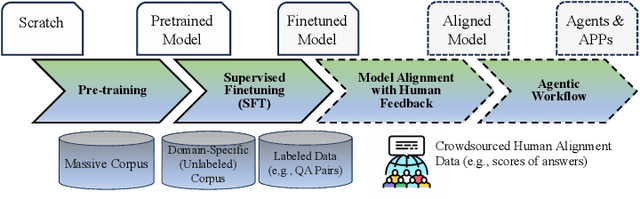
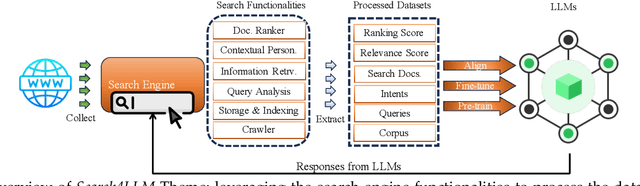
Combining Large Language Models (LLMs) with search engine services marks a significant shift in the field of services computing, opening up new possibilities to enhance how we search for and retrieve information, understand content, and interact with internet services. This paper conducts an in-depth examination of how integrating LLMs with search engines can mutually benefit both technologies. We focus on two main areas: using search engines to improve LLMs (Search4LLM) and enhancing search engine functions using LLMs (LLM4Search). For Search4LLM, we investigate how search engines can provide diverse high-quality datasets for pre-training of LLMs, how they can use the most relevant documents to help LLMs learn to answer queries more accurately, how training LLMs with Learning-To-Rank (LTR) tasks can enhance their ability to respond with greater precision, and how incorporating recent search results can make LLM-generated content more accurate and current. In terms of LLM4Search, we examine how LLMs can be used to summarize content for better indexing by search engines, improve query outcomes through optimization, enhance the ranking of search results by analyzing document relevance, and help in annotating data for learning-to-rank tasks in various learning contexts. However, this promising integration comes with its challenges, which include addressing potential biases and ethical issues in training models, managing the computational and other costs of incorporating LLMs into search services, and continuously updating LLM training with the ever-changing web content. We discuss these challenges and chart out required research directions to address them. We also discuss broader implications for service computing, such as scalability, privacy concerns, and the need to adapt search engine architectures for these advanced models.
Feature-context driven Federated Meta-Learning for Rare Disease Prediction
Dec 29, 2021
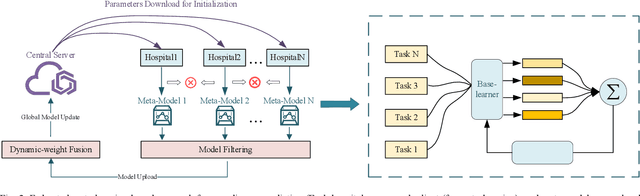
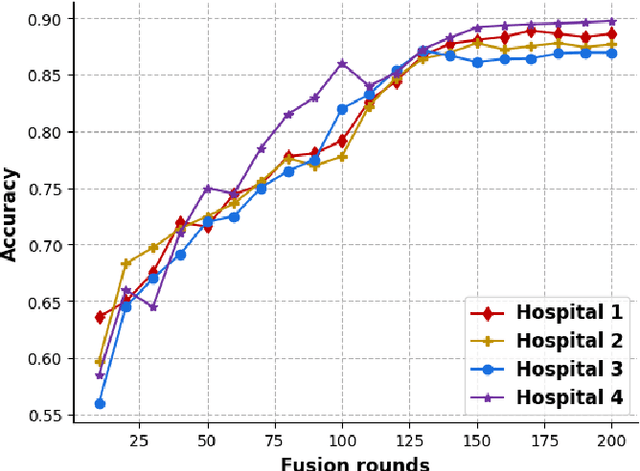
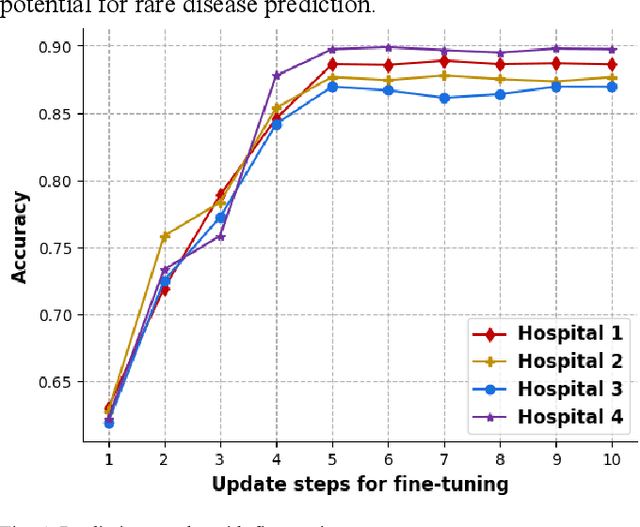
Millions of patients suffer from rare diseases around the world. However, the samples of rare diseases are much smaller than those of common diseases. In addition, due to the sensitivity of medical data, hospitals are usually reluctant to share patient information for data fusion citing privacy concerns. These challenges make it difficult for traditional AI models to extract rare disease features for the purpose of disease prediction. In this paper, we overcome this limitation by proposing a novel approach for rare disease prediction based on federated meta-learning. To improve the prediction accuracy of rare diseases, we design an attention-based meta-learning (ATML) approach which dynamically adjusts the attention to different tasks according to the measured training effect of base learners. Additionally, a dynamic-weight based fusion strategy is proposed to further improve the accuracy of federated learning, which dynamically selects clients based on the accuracy of each local model. Experiments show that with as few as five shots, our approach out-performs the original federated meta-learning algorithm in accuracy and speed. Compared with each hospital's local model, the proposed model's average prediction accuracy increased by 13.28%.
Interpretable Machine Learning for COVID-19: An Empirical Study on Severity Prediction Task
Oct 17, 2020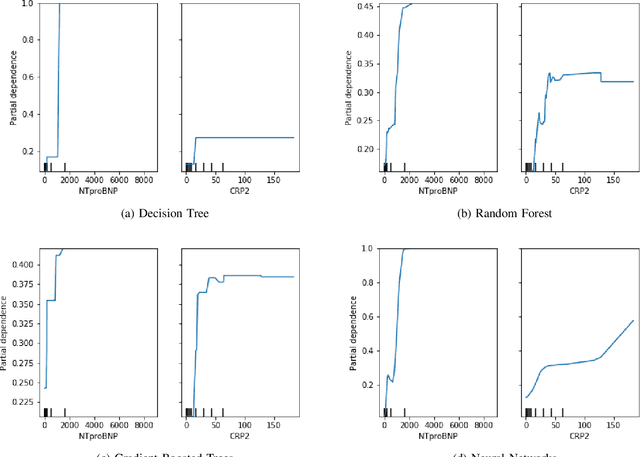
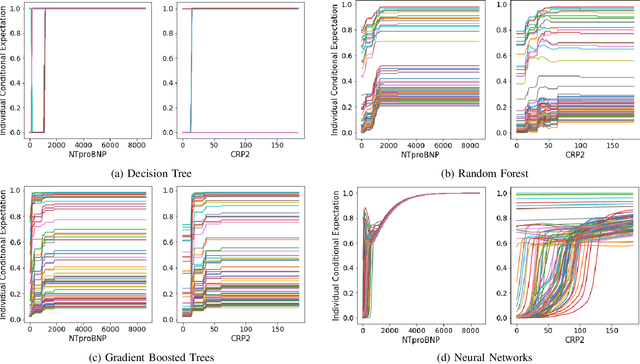
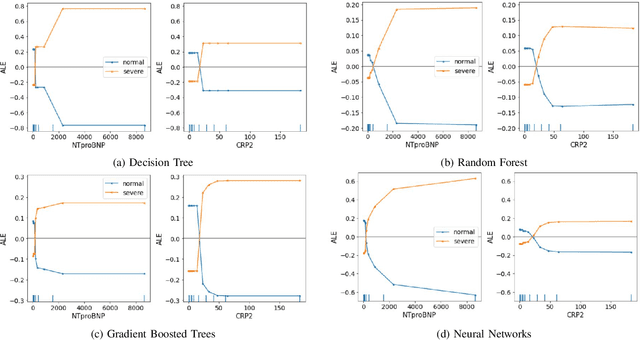
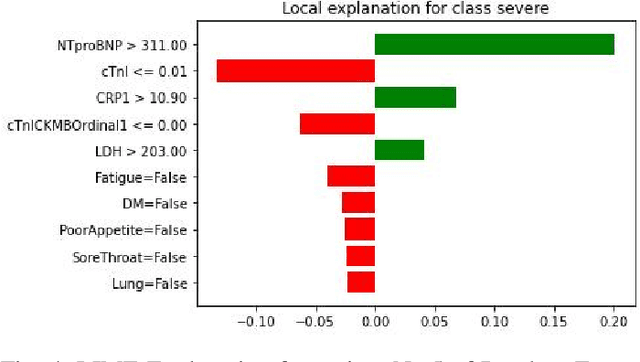
Black-box nature hinders the deployment of many high-accuracy models in medical diagnosis. It is risky to put one's life in the hands of models that medical researchers do not trust. However, to understand the mechanism of a new virus, such as COVID-19, machine learning models may catch important symptoms that medical practitioners do not notice due to the surge of infected patients during a pandemic. In this work, the interpretation of machine learning models reveals that a high C-reactive protein (CRP) corresponds to severe infection, and severe patients usually go through a cardiac injury, which is consistent with well-established medical knowledge. Additionally, through the interpretation of machine learning models, we find phlegm and diarrhea are two important symptoms, without which indicate a high risk of turning severe. These two symptoms are not recognized at the early stage of the outbreak, whereas our findings are corroborated by later autopsies of COVID-19 patients. We find patients with a high N-terminal pro B-type natriuretic peptide (NTproBNP) have a significantly increased risk of death which does not receive much attention initially but proves true by the following-up study. Thus, we suggest interpreting machine learning models can offer help to diagnosis at the early stage of an outbreak.