 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePISA: Piecewise Sparse Attention Is Wiser for Efficient Diffusion Transformers
Feb 03, 2026Diffusion Transformers are fundamental for video and image generation, but their efficiency is bottlenecked by the quadratic complexity of attention. While block sparse attention accelerates computation by attending only critical key-value blocks, it suffers from degradation at high sparsity by discarding context. In this work, we discover that attention scores of non-critical blocks exhibit distributional stability, allowing them to be approximated accurately and efficiently rather than discarded, which is essentially important for sparse attention design. Motivated by this key insight, we propose PISA, a training-free Piecewise Sparse Attention that covers the full attention span with sub-quadratic complexity. Unlike the conventional keep-or-drop paradigm that directly drop the non-critical block information, PISA introduces a novel exact-or-approximate strategy: it maintains exact computation for critical blocks while efficiently approximating the remainder through block-wise Taylor expansion. This design allows PISA to serve as a faithful proxy to full attention, effectively bridging the gap between speed and quality. Experimental results demonstrate that PISA achieves 1.91 times and 2.57 times speedups on Wan2.1-14B and Hunyuan-Video, respectively, while consistently maintaining the highest quality among sparse attention methods. Notably, even for image generation on FLUX, PISA achieves a 1.2 times acceleration without compromising visual quality. Code is available at: https://github.com/xie-lab-ml/piecewise-sparse-attention.
Multiphysics Bench: Benchmarking and Investigating Scientific Machine Learning for Multiphysics PDEs
May 23, 2025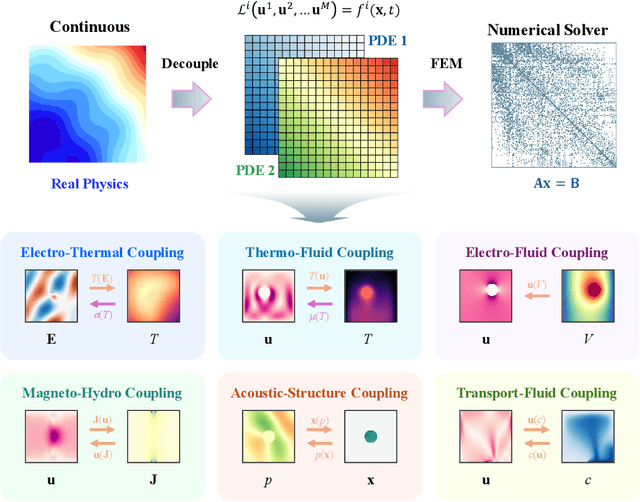



Solving partial differential equations (PDEs) with machine learning has recently attracted great attention, as PDEs are fundamental tools for modeling real-world systems that range from fundamental physical science to advanced engineering disciplines. Most real-world physical systems across various disciplines are actually involved in multiple coupled physical fields rather than a single field. However, previous machine learning studies mainly focused on solving single-field problems, but overlooked the importance and characteristics of multiphysics problems in real world. Multiphysics PDEs typically entail multiple strongly coupled variables, thereby introducing additional complexity and challenges, such as inter-field coupling. Both benchmarking and solving multiphysics problems with machine learning remain largely unexamined. To identify and address the emerging challenges in multiphysics problems, we mainly made three contributions in this work. First, we collect the first general multiphysics dataset, the Multiphysics Bench, that focuses on multiphysics PDE solving with machine learning. Multiphysics Bench is also the most comprehensive PDE dataset to date, featuring the broadest range of coupling types, the greatest diversity of PDE formulations, and the largest dataset scale. Second, we conduct the first systematic investigation on multiple representative learning-based PDE solvers, such as PINNs, FNO, DeepONet, and DiffusionPDE solvers, on multiphysics problems. Unfortunately, naively applying these existing solvers usually show very poor performance for solving multiphysics. Third, through extensive experiments and discussions, we report multiple insights and a bag of useful tricks for solving multiphysics with machine learning, motivating future directions in the study and simulation of complex, coupled physical systems.
GMSA: Enhancing Context Compression via Group Merging and Layer Semantic Alignment
May 18, 2025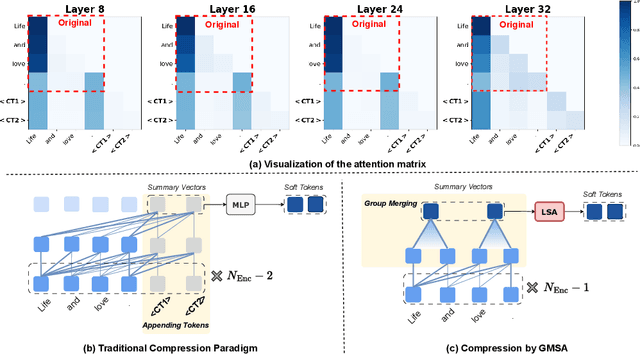
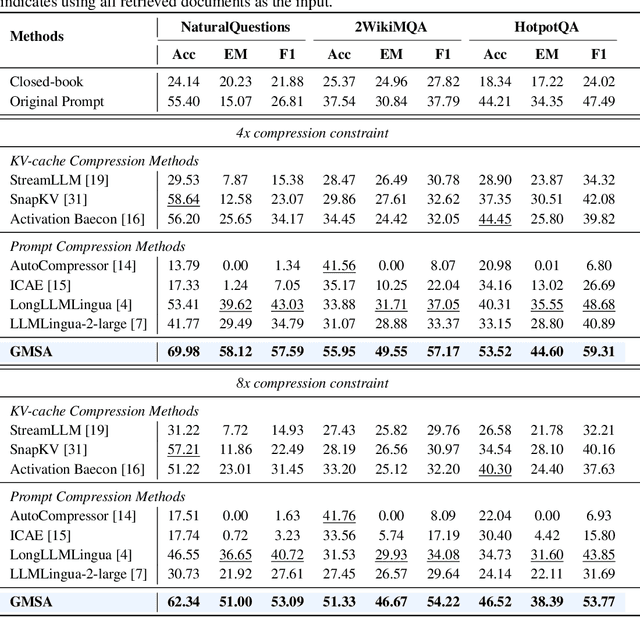
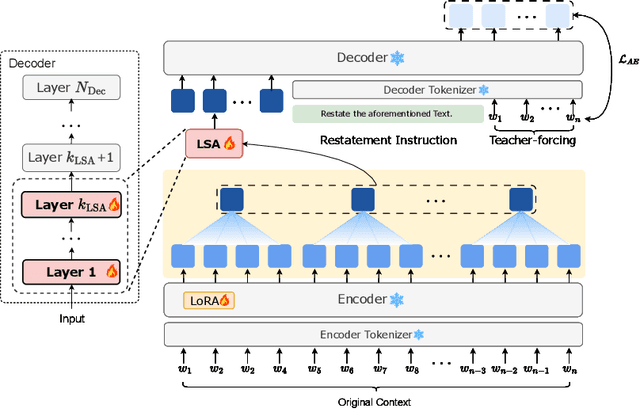

Large language models (LLMs) have achieved impressive performance in a variety of natural language processing (NLP) tasks. However, when applied to long-context scenarios, they face two challenges, i.e., low computational efficiency and much redundant information. This paper introduces GMSA, a context compression framework based on the encoder-decoder architecture, which addresses these challenges by reducing input sequence length and redundant information. Structurally, GMSA has two key components: Group Merging and Layer Semantic Alignment (LSA). Group merging is used to effectively and efficiently extract summary vectors from the original context. Layer semantic alignment, on the other hand, aligns the high-level summary vectors with the low-level primary input semantics, thus bridging the semantic gap between different layers. In the training process, GMSA first learns soft tokens that contain complete semantics through autoencoder training. To furtherly adapt GMSA to downstream tasks, we propose Knowledge Extraction Fine-tuning (KEFT) to extract knowledge from the soft tokens for downstream tasks. We train GMSA by randomly sampling the compression rate for each sample in the dataset. Under this condition, GMSA not only significantly outperforms the traditional compression paradigm in context restoration but also achieves stable and significantly faster convergence with only a few encoder layers. In downstream question-answering (QA) tasks, GMSA can achieve approximately a 2x speedup in end-to-end inference while outperforming both the original input prompts and various state-of-the-art (SOTA) methods by a large margin.
CoRe^2: Collect, Reflect and Refine to Generate Better and Faster
Mar 12, 2025Making text-to-image (T2I) generative model sample both fast and well represents a promising research direction. Previous studies have typically focused on either enhancing the visual quality of synthesized images at the expense of sampling efficiency or dramatically accelerating sampling without improving the base model's generative capacity. Moreover, nearly all inference methods have not been able to ensure stable performance simultaneously on both diffusion models (DMs) and visual autoregressive models (ARMs). In this paper, we introduce a novel plug-and-play inference paradigm, CoRe^2, which comprises three subprocesses: Collect, Reflect, and Refine. CoRe^2 first collects classifier-free guidance (CFG) trajectories, and then use collected data to train a weak model that reflects the easy-to-learn contents while reducing number of function evaluations during inference by half. Subsequently, CoRe^2 employs weak-to-strong guidance to refine the conditional output, thereby improving the model's capacity to generate high-frequency and realistic content, which is difficult for the base model to capture. To the best of our knowledge, CoRe^2 is the first to demonstrate both efficiency and effectiveness across a wide range of DMs, including SDXL, SD3.5, and FLUX, as well as ARMs like LlamaGen. It has exhibited significant performance improvements on HPD v2, Pick-of-Pic, Drawbench, GenEval, and T2I-Compbench. Furthermore, CoRe^2 can be seamlessly integrated with the state-of-the-art Z-Sampling, outperforming it by 0.3 and 0.16 on PickScore and AES, while achieving 5.64s time saving using SD3.5.Code is released at https://github.com/xie-lab-ml/CoRe/tree/main.
Learning from Ambiguous Data with Hard Labels
Jan 08, 2025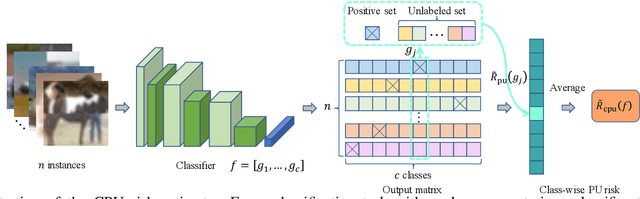

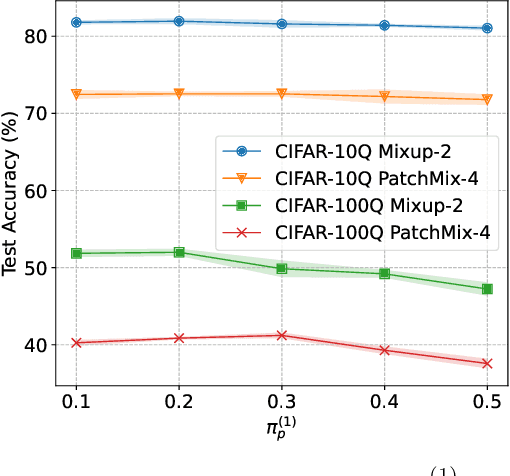
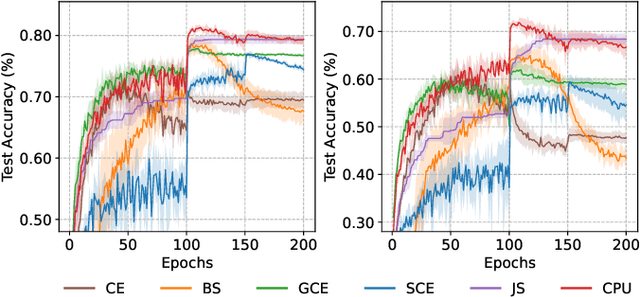
Real-world data often contains intrinsic ambiguity that the common single-hard-label annotation paradigm ignores. Standard training using ambiguous data with these hard labels may produce overly confident models and thus leading to poor generalization. In this paper, we propose a novel framework called Quantized Label Learning (QLL) to alleviate this issue. First, we formulate QLL as learning from (very) ambiguous data with hard labels: ideally, each ambiguous instance should be associated with a ground-truth soft-label distribution describing its corresponding probabilistic weight in each class, however, this is usually not accessible; in practice, we can only observe a quantized label, i.e., a hard label sampled (quantized) from the corresponding ground-truth soft-label distribution, of each instance, which can be seen as a biased approximation of the ground-truth soft-label. Second, we propose a Class-wise Positive-Unlabeled (CPU) risk estimator that allows us to train accurate classifiers from only ambiguous data with quantized labels. Third, to simulate ambiguous datasets with quantized labels in the real world, we design a mixing-based ambiguous data generation procedure for empirical evaluation. Experiments demonstrate that our CPU method can significantly improve model generalization performance and outperform the baselines.
Loss-Aware Curriculum Learning for Chinese Grammatical Error Correction
Dec 31, 2024Chinese grammatical error correction (CGEC) aims to detect and correct errors in the input Chinese sentences. Recently, Pre-trained Language Models (PLMS) have been employed to improve the performance. However, current approaches ignore that correction difficulty varies across different instances and treat these samples equally, enhancing the challenge of model learning. To address this problem, we propose a multi-granularity Curriculum Learning (CL) framework. Specifically, we first calculate the correction difficulty of these samples and feed them into the model from easy to hard batch by batch. Then Instance-Level CL is employed to help the model optimize in the appropriate direction automatically by regulating the loss function. Extensive experimental results and comprehensive analyses of various datasets prove the effectiveness of our method.
Zigzag Diffusion Sampling: Diffusion Models Can Self-Improve via Self-Reflection
Dec 17, 2024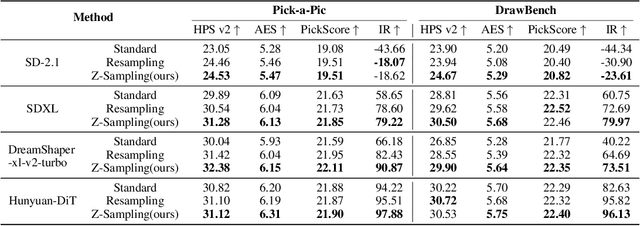


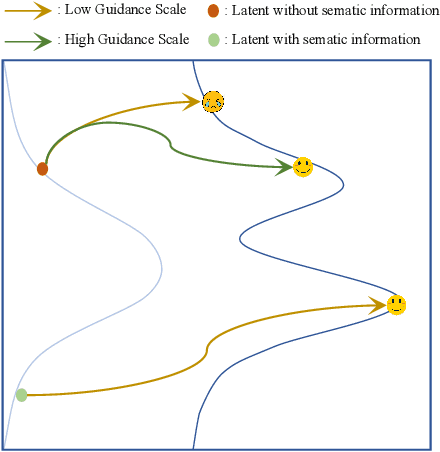
Diffusion models, the most popular generative paradigm so far, can inject conditional information into the generation path to guide the latent towards desired directions. However, existing text-to-image diffusion models often fail to maintain high image quality and high prompt-image alignment for those challenging prompts. To mitigate this issue and enhance existing pretrained diffusion models, we mainly made three contributions in this paper. First, we propose diffusion self-reflection that alternately performs denoising and inversion and demonstrate that such diffusion self-reflection can leverage the guidance gap between denoising and inversion to capture prompt-related semantic information with theoretical and empirical evidence. Second, motivated by theoretical analysis, we derive Zigzag Diffusion Sampling (Z-Sampling), a novel self-reflection-based diffusion sampling method that leverages the guidance gap between denosing and inversion to accumulate semantic information step by step along the sampling path, leading to improved sampling results. Moreover, as a plug-and-play method, Z-Sampling can be generally applied to various diffusion models (e.g., accelerated ones and Transformer-based ones) with very limited coding and computational costs. Third, our extensive experiments demonstrate that Z-Sampling can generally and significantly enhance generation quality across various benchmark datasets, diffusion models, and performance evaluation metrics. For example, DreamShaper with Z-Sampling can self-improve with the HPSv2 winning rate up to 94% over the original results. Moreover, Z-Sampling can further enhance existing diffusion models combined with other orthogonal methods, including Diffusion-DPO.
Bag of Design Choices for Inference of High-Resolution Masked Generative Transformer
Nov 16, 2024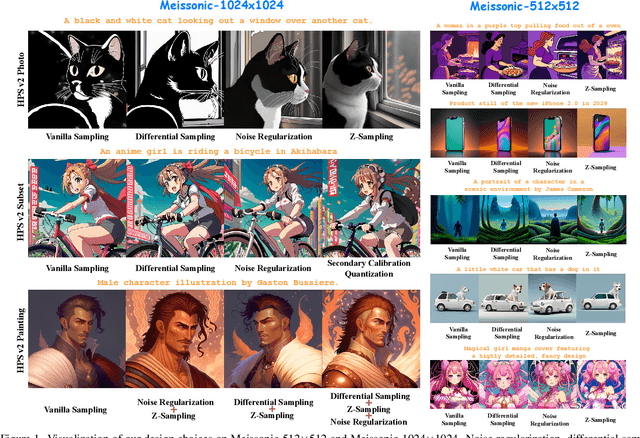

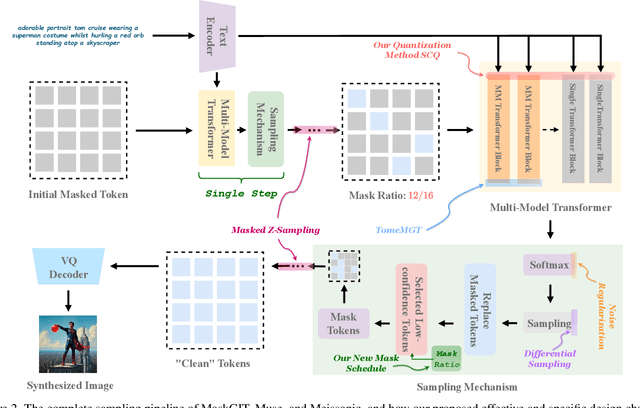
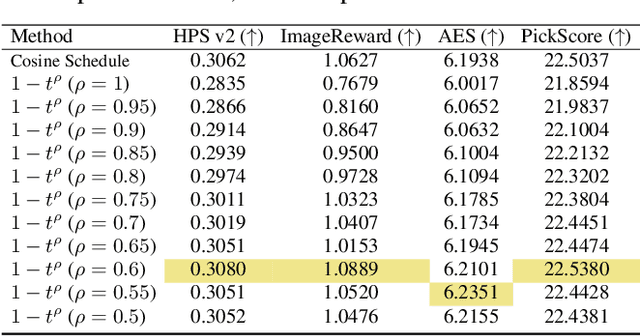
Text-to-image diffusion models (DMs) develop at an unprecedented pace, supported by thorough theoretical exploration and empirical analysis. Unfortunately, the discrepancy between DMs and autoregressive models (ARMs) complicates the path toward achieving the goal of unified vision and language generation. Recently, the masked generative Transformer (MGT) serves as a promising intermediary between DM and ARM by predicting randomly masked image tokens (i.e., masked image modeling), combining the efficiency of DM with the discrete token nature of ARM. However, we find that the comprehensive analyses regarding the inference for MGT are virtually non-existent, and thus we aim to present positive design choices to fill this gap. We modify and re-design a set of DM-based inference techniques for MGT and further elucidate their performance on MGT. We also discuss the approach to correcting token's distribution to enhance inference. Extensive experiments and empirical analyses lead to concrete and effective design choices, and these design choices can be merged to achieve further performance gains. For instance, in terms of enhanced inference, we achieve winning rates of approximately 70% compared to vanilla sampling on HPS v2 with the recent SOTA MGT Meissonic. Our contributions have the potential to further enhance the capabilities and future development of MGTs.
Golden Noise for Diffusion Models: A Learning Framework
Nov 14, 2024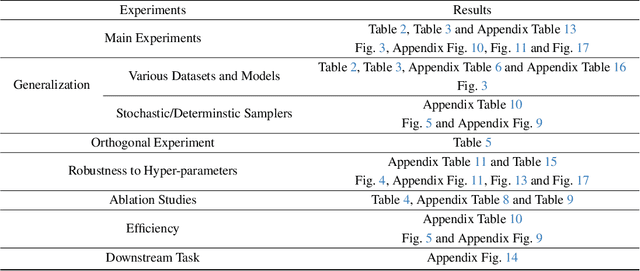

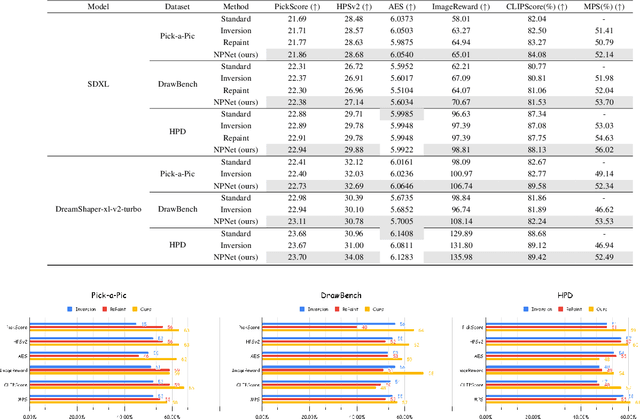
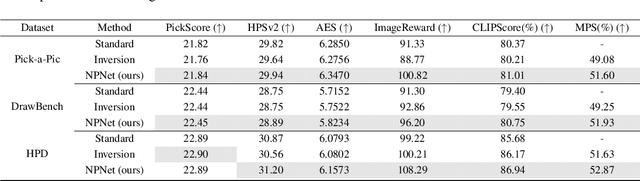
Text-to-image diffusion model is a popular paradigm that synthesizes personalized images by providing a text prompt and a random Gaussian noise. While people observe that some noises are ``golden noises'' that can achieve better text-image alignment and higher human preference than others, we still lack a machine learning framework to obtain those golden noises. To learn golden noises for diffusion sampling, we mainly make three contributions in this paper. First, we identify a new concept termed the \textit{noise prompt}, which aims at turning a random Gaussian noise into a golden noise by adding a small desirable perturbation derived from the text prompt. Following the concept, we first formulate the \textit{noise prompt learning} framework that systematically learns ``prompted'' golden noise associated with a text prompt for diffusion models. Second, we design a noise prompt data collection pipeline and collect a large-scale \textit{noise prompt dataset}~(NPD) that contains 100k pairs of random noises and golden noises with the associated text prompts. With the prepared NPD as the training dataset, we trained a small \textit{noise prompt network}~(NPNet) that can directly learn to transform a random noise into a golden noise. The learned golden noise perturbation can be considered as a kind of prompt for noise, as it is rich in semantic information and tailored to the given text prompt. Third, our extensive experiments demonstrate the impressive effectiveness and generalization of NPNet on improving the quality of synthesized images across various diffusion models, including SDXL, DreamShaper-xl-v2-turbo, and Hunyuan-DiT. Moreover, NPNet is a small and efficient controller that acts as a plug-and-play module with very limited additional inference and computational costs, as it just provides a golden noise instead of a random noise without accessing the original pipeline.
IV-Mixed Sampler: Leveraging Image Diffusion Models for Enhanced Video Synthesis
Oct 05, 2024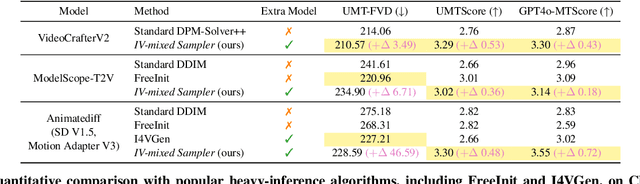
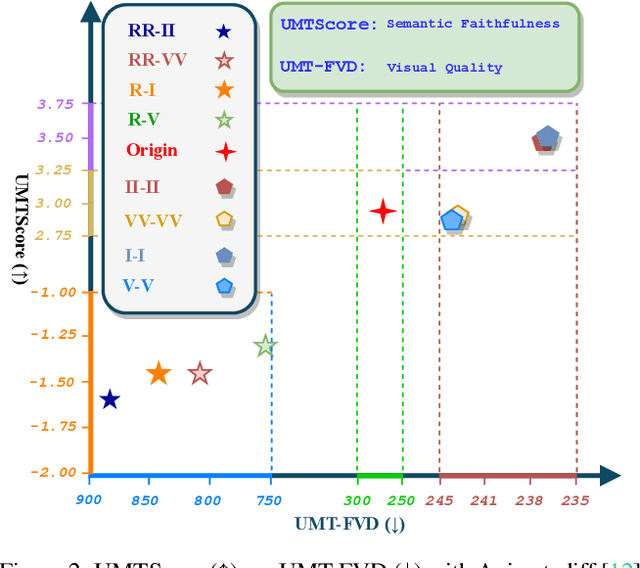
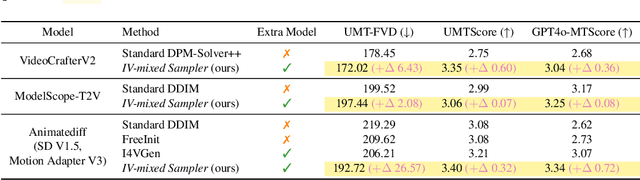
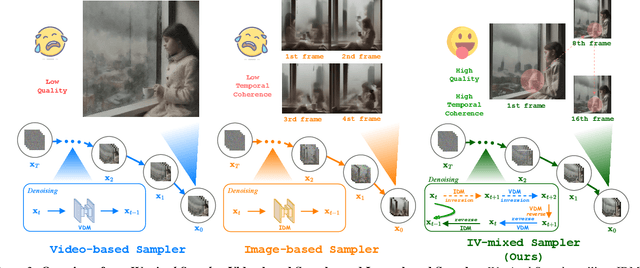
The multi-step sampling mechanism, a key feature of visual diffusion models, has significant potential to replicate the success of OpenAI's Strawberry in enhancing performance by increasing the inference computational cost. Sufficient prior studies have demonstrated that correctly scaling up computation in the sampling process can successfully lead to improved generation quality, enhanced image editing, and compositional generalization. While there have been rapid advancements in developing inference-heavy algorithms for improved image generation, relatively little work has explored inference scaling laws in video diffusion models (VDMs). Furthermore, existing research shows only minimal performance gains that are perceptible to the naked eye. To address this, we design a novel training-free algorithm IV-Mixed Sampler that leverages the strengths of image diffusion models (IDMs) to assist VDMs surpass their current capabilities. The core of IV-Mixed Sampler is to use IDMs to significantly enhance the quality of each video frame and VDMs ensure the temporal coherence of the video during the sampling process. Our experiments have demonstrated that IV-Mixed Sampler achieves state-of-the-art performance on 4 benchmarks including UCF-101-FVD, MSR-VTT-FVD, Chronomagic-Bench-150, and Chronomagic-Bench-1649. For example, the open-source Animatediff with IV-Mixed Sampler reduces the UMT-FVD score from 275.2 to 228.6, closing to 223.1 from the closed-source Pika-2.0.