 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBag of Design Choices for Inference of High-Resolution Masked Generative Transformer
Paper and Code
Nov 16, 2024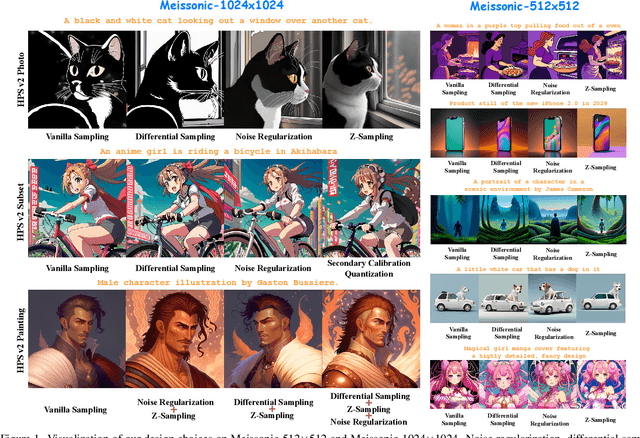

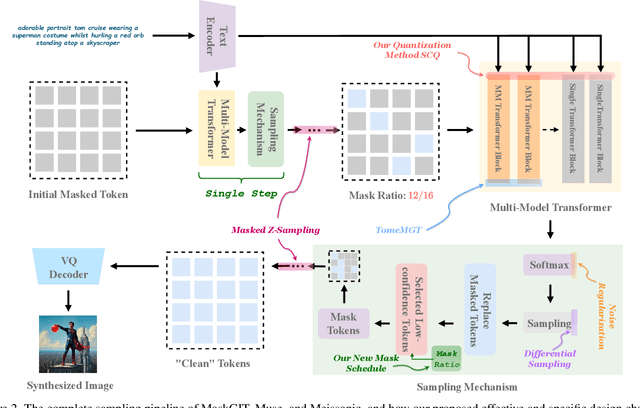
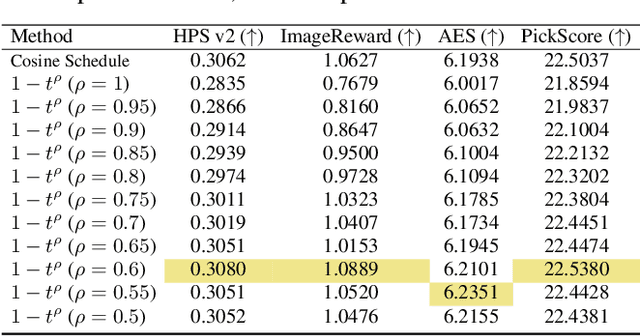
Text-to-image diffusion models (DMs) develop at an unprecedented pace, supported by thorough theoretical exploration and empirical analysis. Unfortunately, the discrepancy between DMs and autoregressive models (ARMs) complicates the path toward achieving the goal of unified vision and language generation. Recently, the masked generative Transformer (MGT) serves as a promising intermediary between DM and ARM by predicting randomly masked image tokens (i.e., masked image modeling), combining the efficiency of DM with the discrete token nature of ARM. However, we find that the comprehensive analyses regarding the inference for MGT are virtually non-existent, and thus we aim to present positive design choices to fill this gap. We modify and re-design a set of DM-based inference techniques for MGT and further elucidate their performance on MGT. We also discuss the approach to correcting token's distribution to enhance inference. Extensive experiments and empirical analyses lead to concrete and effective design choices, and these design choices can be merged to achieve further performance gains. For instance, in terms of enhanced inference, we achieve winning rates of approximately 70% compared to vanilla sampling on HPS v2 with the recent SOTA MGT Meissonic. Our contributions have the potential to further enhance the capabilities and future development of MGTs.