 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLate-to-Early Training: LET LLMs Learn Earlier, So Faster and Better
Feb 05, 2026As Large Language Models (LLMs) achieve remarkable empirical success through scaling model and data size, pretraining has become increasingly critical yet computationally prohibitive, hindering rapid development. Despite the availability of numerous pretrained LLMs developed at significant computational expense, a fundamental real-world question remains underexplored: \textit{Can we leverage existing small pretrained models to accelerate the training of larger models?} In this paper, we propose a Late-to-Early Training (LET) paradigm that enables LLMs to explicitly learn later knowledge in earlier steps and earlier layers. The core idea is to guide the early layers of an LLM during early training using representations from the late layers of a pretrained (i.e. late training phase) model. We identify two key mechanisms that drive LET's effectiveness: late-to-early-step learning and late-to-early-layer learning. These mechanisms significantly accelerate training convergence while robustly enhancing both language modeling capabilities and downstream task performance, enabling faster training with superior performance. Extensive experiments on 1.4B and 7B parameter models demonstrate LET's efficiency and effectiveness. Notably, when training a 1.4B LLM on the Pile dataset, our method achieves up to 1.6$\times$ speedup with nearly 5\% improvement in downstream task accuracy compared to standard training, even when using a pretrained model with 10$\times$ fewer parameters than the target model.
PISA: Piecewise Sparse Attention Is Wiser for Efficient Diffusion Transformers
Feb 03, 2026Diffusion Transformers are fundamental for video and image generation, but their efficiency is bottlenecked by the quadratic complexity of attention. While block sparse attention accelerates computation by attending only critical key-value blocks, it suffers from degradation at high sparsity by discarding context. In this work, we discover that attention scores of non-critical blocks exhibit distributional stability, allowing them to be approximated accurately and efficiently rather than discarded, which is essentially important for sparse attention design. Motivated by this key insight, we propose PISA, a training-free Piecewise Sparse Attention that covers the full attention span with sub-quadratic complexity. Unlike the conventional keep-or-drop paradigm that directly drop the non-critical block information, PISA introduces a novel exact-or-approximate strategy: it maintains exact computation for critical blocks while efficiently approximating the remainder through block-wise Taylor expansion. This design allows PISA to serve as a faithful proxy to full attention, effectively bridging the gap between speed and quality. Experimental results demonstrate that PISA achieves 1.91 times and 2.57 times speedups on Wan2.1-14B and Hunyuan-Video, respectively, while consistently maintaining the highest quality among sparse attention methods. Notably, even for image generation on FLUX, PISA achieves a 1.2 times acceleration without compromising visual quality. Code is available at: https://github.com/xie-lab-ml/piecewise-sparse-attention.
PosterCraft: Rethinking High-Quality Aesthetic Poster Generation in a Unified Framework
Jun 12, 2025
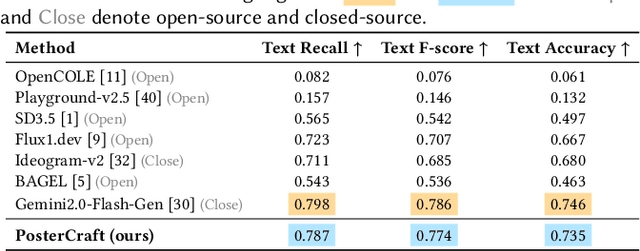
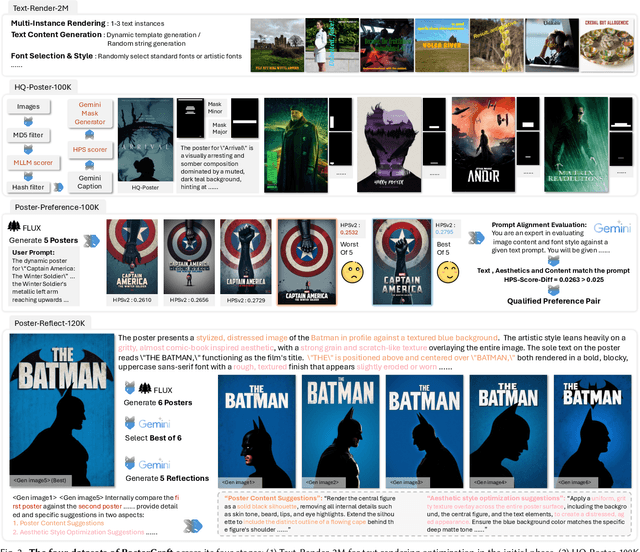
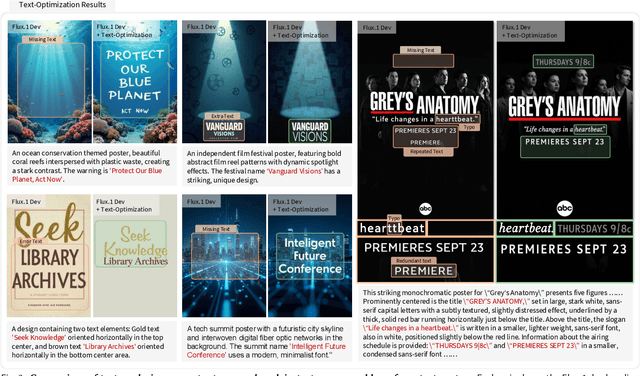
Generating aesthetic posters is more challenging than simple design images: it requires not only precise text rendering but also the seamless integration of abstract artistic content, striking layouts, and overall stylistic harmony. To address this, we propose PosterCraft, a unified framework that abandons prior modular pipelines and rigid, predefined layouts, allowing the model to freely explore coherent, visually compelling compositions. PosterCraft employs a carefully designed, cascaded workflow to optimize the generation of high-aesthetic posters: (i) large-scale text-rendering optimization on our newly introduced Text-Render-2M dataset; (ii) region-aware supervised fine-tuning on HQ-Poster100K; (iii) aesthetic-text-reinforcement learning via best-of-n preference optimization; and (iv) joint vision-language feedback refinement. Each stage is supported by a fully automated data-construction pipeline tailored to its specific needs, enabling robust training without complex architectural modifications. Evaluated on multiple experiments, PosterCraft significantly outperforms open-source baselines in rendering accuracy, layout coherence, and overall visual appeal-approaching the quality of SOTA commercial systems. Our code, models, and datasets can be found in the Project page: https://ephemeral182.github.io/PosterCraft
MagicDistillation: Weak-to-Strong Video Distillation for Large-Scale Portrait Few-Step Synthesis
Mar 17, 2025



Fine-tuning open-source large-scale VDMs for the portrait video synthesis task can result in significant improvements across multiple dimensions, such as visual quality and natural facial motion dynamics. Despite their advancements, how to achieve step distillation and reduce the substantial computational overhead of large-scale VDMs remains unexplored. To fill this gap, this paper proposes Weak-to-Strong Video Distillation (W2SVD) to mitigate both the issue of insufficient training memory and the problem of training collapse observed in vanilla DMD during the training process. Specifically, we first leverage LoRA to fine-tune the fake diffusion transformer (DiT) to address the out-of-memory issue. Then, we employ the W2S distribution matching to adjust the real DiT's parameter, subtly shifting it toward the fake DiT's parameter. This adjustment is achieved by utilizing the weak weight of the low-rank branch, effectively alleviate the conundrum where the video synthesized by the few-step generator deviates from the real data distribution, leading to inaccuracies in the KL divergence approximation. Additionally, we minimize the distance between the fake data distribution and the ground truth distribution to further enhance the visual quality of the synthesized videos. As experimentally demonstrated on HunyuanVideo, W2SVD surpasses the standard Euler, LCM, DMD and even the 28-step standard sampling in FID/FVD and VBench in 1/4-step video synthesis. The project page is in https://w2svd.github.io/W2SVD/.
CoRe^2: Collect, Reflect and Refine to Generate Better and Faster
Mar 12, 2025Making text-to-image (T2I) generative model sample both fast and well represents a promising research direction. Previous studies have typically focused on either enhancing the visual quality of synthesized images at the expense of sampling efficiency or dramatically accelerating sampling without improving the base model's generative capacity. Moreover, nearly all inference methods have not been able to ensure stable performance simultaneously on both diffusion models (DMs) and visual autoregressive models (ARMs). In this paper, we introduce a novel plug-and-play inference paradigm, CoRe^2, which comprises three subprocesses: Collect, Reflect, and Refine. CoRe^2 first collects classifier-free guidance (CFG) trajectories, and then use collected data to train a weak model that reflects the easy-to-learn contents while reducing number of function evaluations during inference by half. Subsequently, CoRe^2 employs weak-to-strong guidance to refine the conditional output, thereby improving the model's capacity to generate high-frequency and realistic content, which is difficult for the base model to capture. To the best of our knowledge, CoRe^2 is the first to demonstrate both efficiency and effectiveness across a wide range of DMs, including SDXL, SD3.5, and FLUX, as well as ARMs like LlamaGen. It has exhibited significant performance improvements on HPD v2, Pick-of-Pic, Drawbench, GenEval, and T2I-Compbench. Furthermore, CoRe^2 can be seamlessly integrated with the state-of-the-art Z-Sampling, outperforming it by 0.3 and 0.16 on PickScore and AES, while achieving 5.64s time saving using SD3.5.Code is released at https://github.com/xie-lab-ml/CoRe/tree/main.
MagicInfinite: Generating Infinite Talking Videos with Your Words and Voice
Mar 07, 2025We present MagicInfinite, a novel diffusion Transformer (DiT) framework that overcomes traditional portrait animation limitations, delivering high-fidelity results across diverse character types-realistic humans, full-body figures, and stylized anime characters. It supports varied facial poses, including back-facing views, and animates single or multiple characters with input masks for precise speaker designation in multi-character scenes. Our approach tackles key challenges with three innovations: (1) 3D full-attention mechanisms with a sliding window denoising strategy, enabling infinite video generation with temporal coherence and visual quality across diverse character styles; (2) a two-stage curriculum learning scheme, integrating audio for lip sync, text for expressive dynamics, and reference images for identity preservation, enabling flexible multi-modal control over long sequences; and (3) region-specific masks with adaptive loss functions to balance global textual control and local audio guidance, supporting speaker-specific animations. Efficiency is enhanced via our innovative unified step and cfg distillation techniques, achieving a 20x inference speed boost over the basemodel: generating a 10 second 540x540p video in 10 seconds or 720x720p in 30 seconds on 8 H100 GPUs, without quality loss. Evaluations on our new benchmark demonstrate MagicInfinite's superiority in audio-lip synchronization, identity preservation, and motion naturalness across diverse scenarios. It is publicly available at https://www.hedra.com/, with examples at https://magicinfinite.github.io/.
Magic 1-For-1: Generating One Minute Video Clips within One Minute
Feb 11, 2025In this technical report, we present Magic 1-For-1 (Magic141), an efficient video generation model with optimized memory consumption and inference latency. The key idea is simple: factorize the text-to-video generation task into two separate easier tasks for diffusion step distillation, namely text-to-image generation and image-to-video generation. We verify that with the same optimization algorithm, the image-to-video task is indeed easier to converge over the text-to-video task. We also explore a bag of optimization tricks to reduce the computational cost of training the image-to-video (I2V) models from three aspects: 1) model convergence speedup by using a multi-modal prior condition injection; 2) inference latency speed up by applying an adversarial step distillation, and 3) inference memory cost optimization with parameter sparsification. With those techniques, we are able to generate 5-second video clips within 3 seconds. By applying a test time sliding window, we are able to generate a minute-long video within one minute with significantly improved visual quality and motion dynamics, spending less than 1 second for generating 1 second video clips on average. We conduct a series of preliminary explorations to find out the optimal tradeoff between computational cost and video quality during diffusion step distillation and hope this could be a good foundation model for open-source explorations. The code and the model weights are available at https://github.com/DA-Group-PKU/Magic-1-For-1.
Zigzag Diffusion Sampling: Diffusion Models Can Self-Improve via Self-Reflection
Dec 17, 2024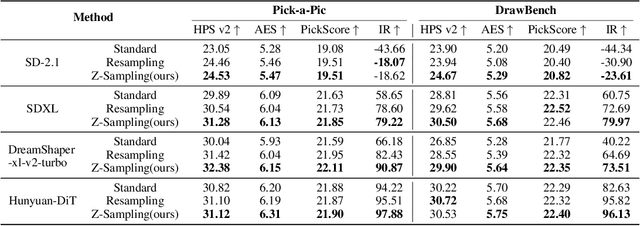


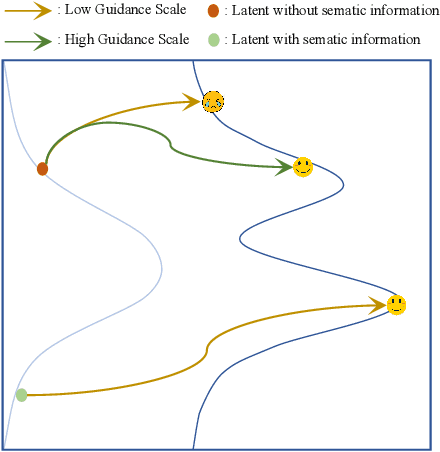
Diffusion models, the most popular generative paradigm so far, can inject conditional information into the generation path to guide the latent towards desired directions. However, existing text-to-image diffusion models often fail to maintain high image quality and high prompt-image alignment for those challenging prompts. To mitigate this issue and enhance existing pretrained diffusion models, we mainly made three contributions in this paper. First, we propose diffusion self-reflection that alternately performs denoising and inversion and demonstrate that such diffusion self-reflection can leverage the guidance gap between denoising and inversion to capture prompt-related semantic information with theoretical and empirical evidence. Second, motivated by theoretical analysis, we derive Zigzag Diffusion Sampling (Z-Sampling), a novel self-reflection-based diffusion sampling method that leverages the guidance gap between denosing and inversion to accumulate semantic information step by step along the sampling path, leading to improved sampling results. Moreover, as a plug-and-play method, Z-Sampling can be generally applied to various diffusion models (e.g., accelerated ones and Transformer-based ones) with very limited coding and computational costs. Third, our extensive experiments demonstrate that Z-Sampling can generally and significantly enhance generation quality across various benchmark datasets, diffusion models, and performance evaluation metrics. For example, DreamShaper with Z-Sampling can self-improve with the HPSv2 winning rate up to 94% over the original results. Moreover, Z-Sampling can further enhance existing diffusion models combined with other orthogonal methods, including Diffusion-DPO.
DELT: A Simple Diversity-driven EarlyLate Training for Dataset Distillation
Nov 29, 2024Recent advances in dataset distillation have led to solutions in two main directions. The conventional batch-to-batch matching mechanism is ideal for small-scale datasets and includes bi-level optimization methods on models and syntheses, such as FRePo, RCIG, and RaT-BPTT, as well as other methods like distribution matching, gradient matching, and weight trajectory matching. Conversely, batch-to-global matching typifies decoupled methods, which are particularly advantageous for large-scale datasets. This approach has garnered substantial interest within the community, as seen in SRe$^2$L, G-VBSM, WMDD, and CDA. A primary challenge with the second approach is the lack of diversity among syntheses within each class since samples are optimized independently and the same global supervision signals are reused across different synthetic images. In this study, we propose a new Diversity-driven EarlyLate Training (DELT) scheme to enhance the diversity of images in batch-to-global matching with less computation. Our approach is conceptually simple yet effective, it partitions predefined IPC samples into smaller subtasks and employs local optimizations to distill each subset into distributions from distinct phases, reducing the uniformity induced by the unified optimization process. These distilled images from the subtasks demonstrate effective generalization when applied to the entire task. We conduct extensive experiments on CIFAR, Tiny-ImageNet, ImageNet-1K, and its sub-datasets. Our approach outperforms the previous state-of-the-art by 2$\sim$5% on average across different datasets and IPCs (images per class), increasing diversity per class by more than 5% while reducing synthesis time by up to 39.3% for enhancing the training efficiency. Code is available at: https://github.com/VILA-Lab/DELT.
Bag of Design Choices for Inference of High-Resolution Masked Generative Transformer
Nov 16, 2024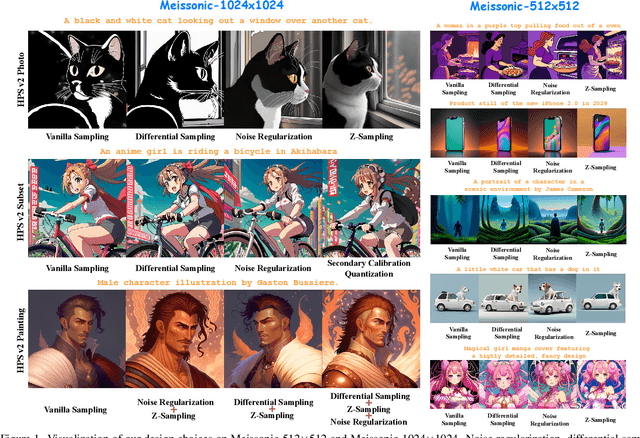

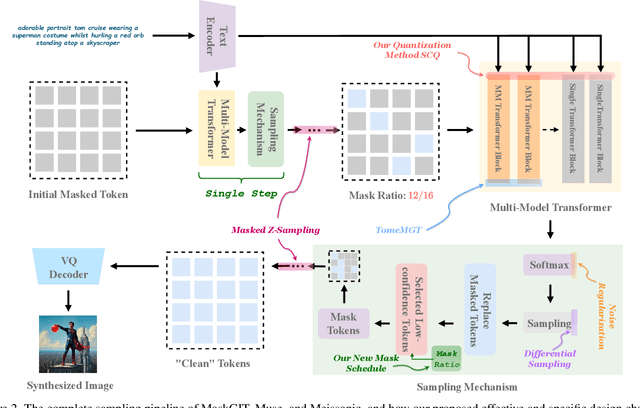
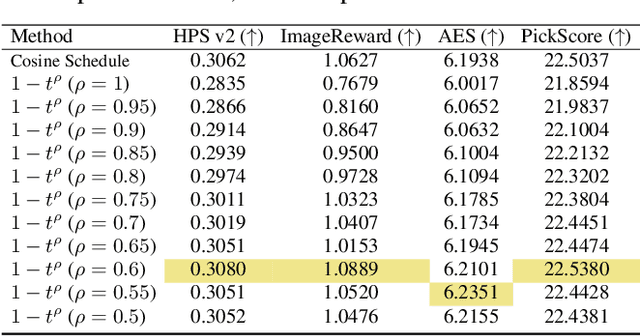
Text-to-image diffusion models (DMs) develop at an unprecedented pace, supported by thorough theoretical exploration and empirical analysis. Unfortunately, the discrepancy between DMs and autoregressive models (ARMs) complicates the path toward achieving the goal of unified vision and language generation. Recently, the masked generative Transformer (MGT) serves as a promising intermediary between DM and ARM by predicting randomly masked image tokens (i.e., masked image modeling), combining the efficiency of DM with the discrete token nature of ARM. However, we find that the comprehensive analyses regarding the inference for MGT are virtually non-existent, and thus we aim to present positive design choices to fill this gap. We modify and re-design a set of DM-based inference techniques for MGT and further elucidate their performance on MGT. We also discuss the approach to correcting token's distribution to enhance inference. Extensive experiments and empirical analyses lead to concrete and effective design choices, and these design choices can be merged to achieve further performance gains. For instance, in terms of enhanced inference, we achieve winning rates of approximately 70% compared to vanilla sampling on HPS v2 with the recent SOTA MGT Meissonic. Our contributions have the potential to further enhance the capabilities and future development of MGTs.