 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhat Limits Vision-and-Language Navigation ?
May 13, 2026Vision-and-Language Navigation (VLN) is a cornerstone of embodied intelligence. However, current agents often suffer from significant performance degradation when transitioning from simulation to real-world deployment, primarily due to perceptual instability (e.g., lighting variations and motion blur) and under-specified instructions. While existing methods attempt to bridge this gap by scaling up model size and training data, we argue that the bottleneck lies in the lack of robust spatial grounding and cross-domain priors. In this paper, we propose StereoNav, a robust Vision-Language-Action framework designed to enhance real-world navigation consistency. To address the inherent gap between synthetic training and physical execution, we introduce Target-Location Priors as a persistent bridge. These priors provide stable visual guidance that remains invariant across domains, effectively grounding the agent even when instructions are vague. Furthermore, to mitigate visual disturbances like motion blur and illumination shifts, StereoNav leverages stereo vision to construct a unified representation of semantics and geometry, enabling precise action prediction through enhanced depth awareness. Extensive experiments on R2R-CE and RxR-CE demonstrate that StereoNav achieves state-of-the-art egocentric RGB performance, with SR and SPL scores of 81.1% and 68.3%, and 67.5% and 52.0%, respectively, while using significantly fewer parameters and less training data than prior scaling-based approaches. More importantly, real-world robotic deployments confirm that StereoNav substantially improves navigation reliability in complex, unstructured environments. Project page: https://yunheng-wang.github.io/stereonav-public.github.io.
UniGround: Universal 3D Visual Grounding via Training-Free Scene Parsing
Mar 09, 2026Understanding and localizing objects in complex 3D environments from natural language descriptions, known as 3D Visual Grounding (3DVG), is a foundational challenge in embodied AI, with broad implications for robotics, augmented reality, and human-machine interaction. Large-scale pre-trained foundation models have driven significant progress on this front, enabling open-vocabulary 3DVG that allows systems to locate arbitrary objects in a given scene. However, their reliance on pre-trained models constrains 3D perception and reasoning within the inherited knowledge boundaries, resulting in limited generalization to unseen spatial relationships and poor robustness to out-of-distribution scenes. In this paper, we replace this constrained perception with training-free visual and geometric reasoning, thereby unlocking open-world 3DVG that enables the localization of any object in any scene beyond the training data. Specifically, the proposed UniGround operates in two stages: a Global Candidate Filtering stage that constructs scene candidates through training-free 3D topology and multi-view semantic encoding, and a Local Precision Grounding stage that leverages multi-scale visual prompting and structured reasoning to precisely identify the target object. Experiments on ScanRefer and EmbodiedScan show that UniGround achieves 46.1\%/34.1\% Acc@0.25/0.5 on ScanRefer and 28.7\% Acc@0.25 on EmbodiedScan, establishing a new state-of-the-art among zero-shot methods on EmbodiedScan without any 3D supervision. We further evaluate UniGround in real-world environments under uncontrolled reconstruction conditions and substantial domain shift, showing training-free reasoning generalizes robustly beyond curated benchmarks.
Spherical Latent Motion Prior for Physics-Based Simulated Humanoid Control
Mar 01, 2026Learning motion priors for physics-based humanoid control is an active research topic. Existing approaches mainly include variational autoencoders (VAE) and adversarial motion priors (AMP). VAE introduces information loss, and random latent sampling may sometimes produce invalid behaviors. AMP suffers from mode collapse and struggles to capture diverse motion skills. We present the Spherical Latent Motion Prior (SLMP), a two-stage method for learning motion priors. In the first stage, we train a high-quality motion tracking controller. In the second stage, we distill the tracking controller into a spherical latent space. A combination of distillation, a discriminator, and a discriminator-guided local semantic consistency constraint shapes a structured latent action space, allowing stable random sampling without information loss. To evaluate SLMP, we collect a two-hour human combat motion capture dataset and show that SLMP preserves fine motion detail without information loss, and random sampling yields semantically valid and stable behaviors. When applied to a two-agent physics-based combat task, SLMP produces human-like and physically plausible combat behaviors only using simple rule-based rewards. Furthermore, SLMP generalizes across different humanoid robot morphologies, demonstrating its transferability beyond a single simulated avatar.
Iterative Closed-Loop Motion Synthesis for Scaling the Capabilities of Humanoid Control
Feb 25, 2026Physics-based humanoid control relies on training with motion datasets that have diverse data distributions. However, the fixed difficulty distribution of datasets limits the performance ceiling of the trained control policies. Additionally, the method of acquiring high-quality data through professional motion capture systems is constrained by costs, making it difficult to achieve large-scale scalability. To address these issues, we propose a closed-loop automated motion data generation and iterative framework. It can generate high-quality motion data with rich action semantics, including martial arts, dance, combat, sports, gymnastics, and more. Furthermore, our framework enables difficulty iteration of policies and data through physical metrics and objective evaluations, allowing the trained tracker to break through its original difficulty limits. On the PHC single-primitive tracker, using only approximately 1/10 of the AMASS dataset size, the average failure rate on the test set (2201 clips) is reduced by 45\% compared to the baseline. Finally, we conduct comprehensive ablation and comparative experiments to highlight the rationality and advantages of our framework.
HERO: Hierarchical Traversable 3D Scene Graphs for Embodied Navigation Among Movable Obstacles
Dec 17, 20253D Scene Graphs (3DSGs) constitute a powerful representation of the physical world, distinguished by their abilities to explicitly model the complex spatial, semantic, and functional relationships between entities, rendering a foundational understanding that enables agents to interact intelligently with their environment and execute versatile behaviors. Embodied navigation, as a crucial component of such capabilities, leverages the compact and expressive nature of 3DSGs to enable long-horizon reasoning and planning in complex, large-scale environments. However, prior works rely on a static-world assumption, defining traversable space solely based on static spatial layouts and thereby treating interactable obstacles as non-traversable. This fundamental limitation severely undermines their effectiveness in real-world scenarios, leading to limited reachability, low efficiency, and inferior extensibility. To address these issues, we propose HERO, a novel framework for constructing Hierarchical Traversable 3DSGs, that redefines traversability by modeling operable obstacles as pathways, capturing their physical interactivity, functional semantics, and the scene's relational hierarchy. The results show that, relative to its baseline, HERO reduces PL by 35.1% in partially obstructed environments and increases SR by 79.4% in fully obstructed ones, demonstrating substantially higher efficiency and reachability.
Adaptive Scaling of Policy Constraints for Offline Reinforcement Learning
Aug 27, 2025Offline reinforcement learning (RL) enables learning effective policies from fixed datasets without any environment interaction. Existing methods typically employ policy constraints to mitigate the distribution shift encountered during offline RL training. However, because the scale of the constraints varies across tasks and datasets of differing quality, existing methods must meticulously tune hyperparameters to match each dataset, which is time-consuming and often impractical. We propose Adaptive Scaling of Policy Constraints (ASPC), a second-order differentiable framework that dynamically balances RL and behavior cloning (BC) during training. We theoretically analyze its performance improvement guarantee. In experiments on 39 datasets across four D4RL domains, ASPC using a single hyperparameter configuration outperforms other adaptive constraint methods and state-of-the-art offline RL algorithms that require per-dataset tuning while incurring only minimal computational overhead. The code will be released at https://github.com/Colin-Jing/ASPC.
Hierarchical Multi-Label Contrastive Learning for Protein-Protein Interaction Prediction Across Organisms
Jul 03, 2025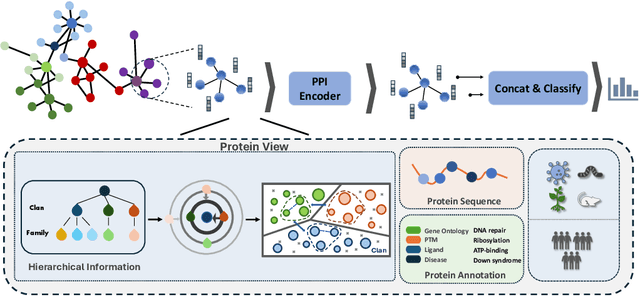
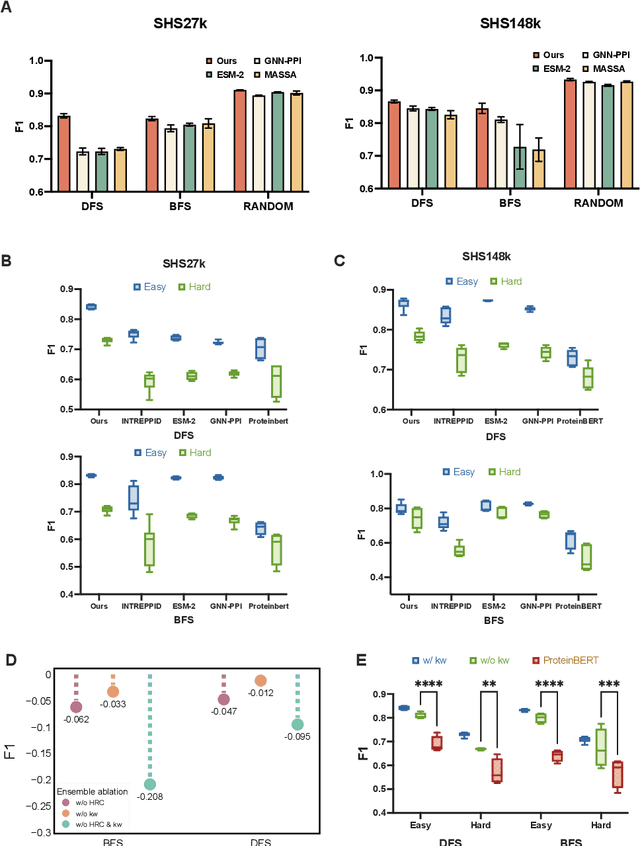
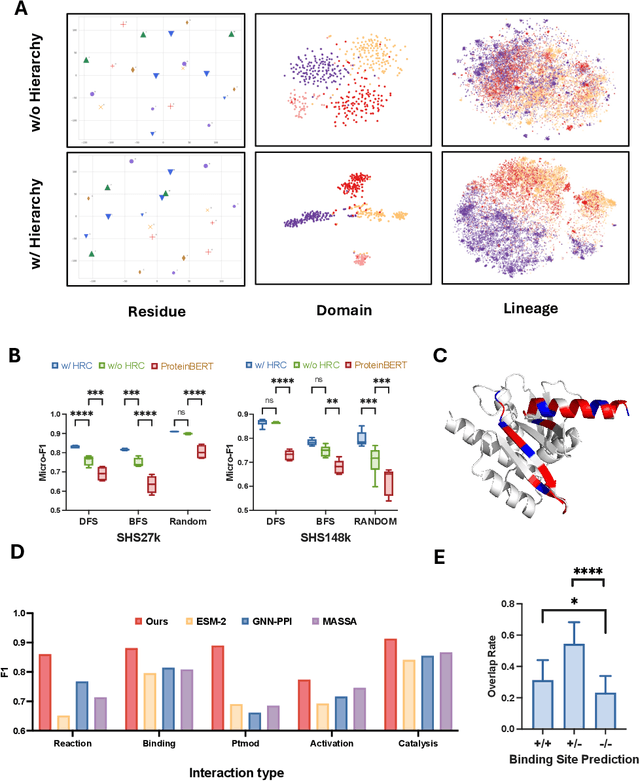
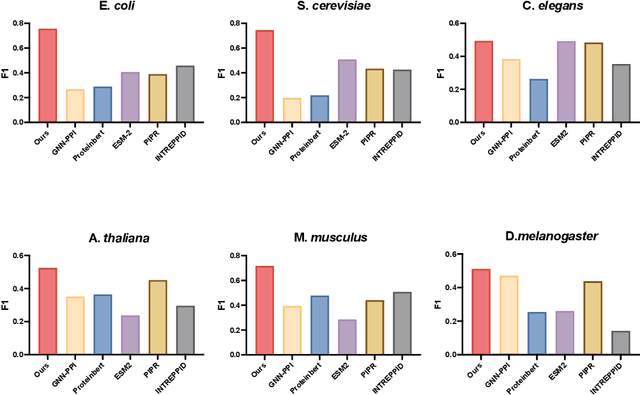
Recent advances in AI for science have highlighted the power of contrastive learning in bridging heterogeneous biological data modalities. Building on this paradigm, we propose HIPPO (HIerarchical Protein-Protein interaction prediction across Organisms), a hierarchical contrastive framework for protein-protein interaction(PPI) prediction, where protein sequences and their hierarchical attributes are aligned through multi-tiered biological representation matching. The proposed approach incorporates hierarchical contrastive loss functions that emulate the structured relationship among functional classes of proteins. The framework adaptively incorporates domain and family knowledge through a data-driven penalty mechanism, enforcing consistency between the learned embedding space and the intrinsic hierarchy of protein functions. Experiments on benchmark datasets demonstrate that HIPPO achieves state-of-the-art performance, outperforming existing methods and showing robustness in low-data regimes. Notably, the model demonstrates strong zero-shot transferability to other species without retraining, enabling reliable PPI prediction and functional inference even in less characterized or rare organisms where experimental data are limited. Further analysis reveals that hierarchical feature fusion is critical for capturing conserved interaction determinants, such as binding motifs and functional annotations. This work advances cross-species PPI prediction and provides a unified framework for interaction prediction in scenarios with sparse or imbalanced multi-species data.
Spiking Transformers Need High Frequency Information
May 24, 2025Spiking Transformers offer an energy-efficient alternative to conventional deep learning by transmitting information solely through binary (0/1) spikes. However, there remains a substantial performance gap compared to artificial neural networks. A common belief is that their binary and sparse activation transmission leads to information loss, thus degrading feature representation and accuracy. In this work, however, we reveal for the first time that spiking neurons preferentially propagate low-frequency information. We hypothesize that the rapid dissipation of high-frequency components is the primary cause of performance degradation. For example, on Cifar-100, adopting Avg-Pooling (low-pass) for token mixing lowers performance to 76.73%; interestingly, replacing it with Max-Pooling (high-pass) pushes the top-1 accuracy to 79.12%, surpassing the well-tuned Spikformer baseline by 0.97%. Accordingly, we introduce Max-Former that restores high-frequency signals through two frequency-enhancing operators: extra Max-Pooling in patch embedding and Depth-Wise Convolution in place of self-attention. Notably, our Max-Former (63.99 M) hits the top-1 accuracy of 82.39% on ImageNet, showing a +7.58% improvement over Spikformer with comparable model size (74.81%, 66.34 M). We hope this simple yet effective solution inspires future research to explore the distinctive nature of spiking neural networks, beyond the established practice in standard deep learning.
CoRe^2: Collect, Reflect and Refine to Generate Better and Faster
Mar 12, 2025Making text-to-image (T2I) generative model sample both fast and well represents a promising research direction. Previous studies have typically focused on either enhancing the visual quality of synthesized images at the expense of sampling efficiency or dramatically accelerating sampling without improving the base model's generative capacity. Moreover, nearly all inference methods have not been able to ensure stable performance simultaneously on both diffusion models (DMs) and visual autoregressive models (ARMs). In this paper, we introduce a novel plug-and-play inference paradigm, CoRe^2, which comprises three subprocesses: Collect, Reflect, and Refine. CoRe^2 first collects classifier-free guidance (CFG) trajectories, and then use collected data to train a weak model that reflects the easy-to-learn contents while reducing number of function evaluations during inference by half. Subsequently, CoRe^2 employs weak-to-strong guidance to refine the conditional output, thereby improving the model's capacity to generate high-frequency and realistic content, which is difficult for the base model to capture. To the best of our knowledge, CoRe^2 is the first to demonstrate both efficiency and effectiveness across a wide range of DMs, including SDXL, SD3.5, and FLUX, as well as ARMs like LlamaGen. It has exhibited significant performance improvements on HPD v2, Pick-of-Pic, Drawbench, GenEval, and T2I-Compbench. Furthermore, CoRe^2 can be seamlessly integrated with the state-of-the-art Z-Sampling, outperforming it by 0.3 and 0.16 on PickScore and AES, while achieving 5.64s time saving using SD3.5.Code is released at https://github.com/xie-lab-ml/CoRe/tree/main.
Optimal Brain Apoptosis
Feb 25, 2025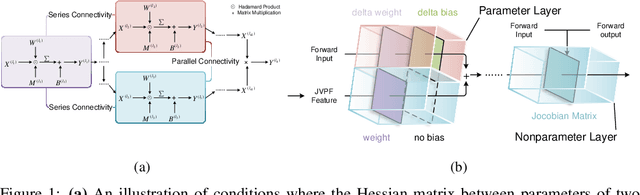
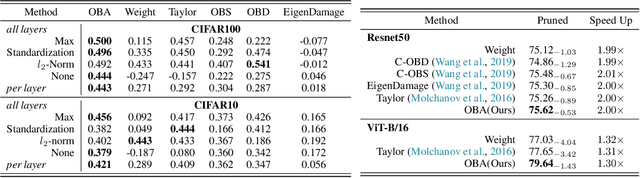
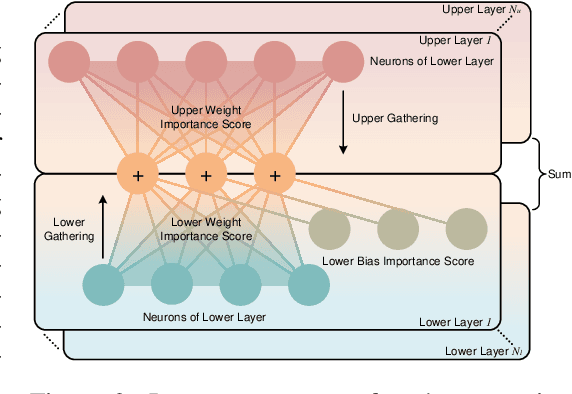
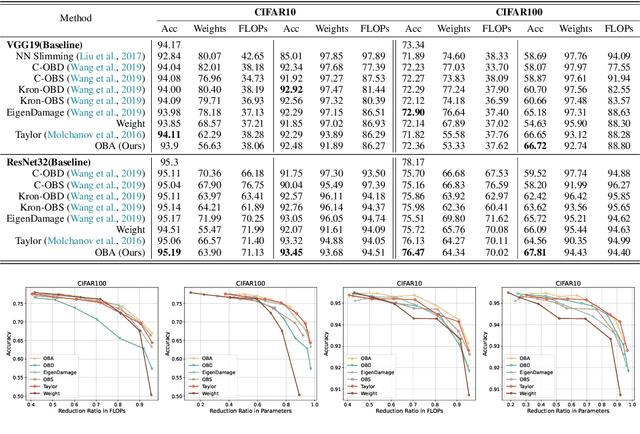
The increasing complexity and parameter count of Convolutional Neural Networks (CNNs) and Transformers pose challenges in terms of computational efficiency and resource demands. Pruning has been identified as an effective strategy to address these challenges by removing redundant elements such as neurons, channels, or connections, thereby enhancing computational efficiency without heavily compromising performance. This paper builds on the foundational work of Optimal Brain Damage (OBD) by advancing the methodology of parameter importance estimation using the Hessian matrix. Unlike previous approaches that rely on approximations, we introduce Optimal Brain Apoptosis (OBA), a novel pruning method that calculates the Hessian-vector product value directly for each parameter. By decomposing the Hessian matrix across network layers and identifying conditions under which inter-layer Hessian submatrices are non-zero, we propose a highly efficient technique for computing the second-order Taylor expansion of parameters. This approach allows for a more precise pruning process, particularly in the context of CNNs and Transformers, as validated in our experiments including VGG19, ResNet32, ResNet50, and ViT-B/16 on CIFAR10, CIFAR100 and Imagenet datasets. Our code is available at https://github.com/NEU-REAL/OBA.