 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpiking Neural Network for Intra-cortical Brain Signal Decoding
Apr 12, 2025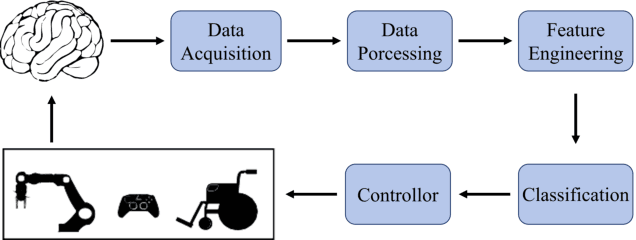
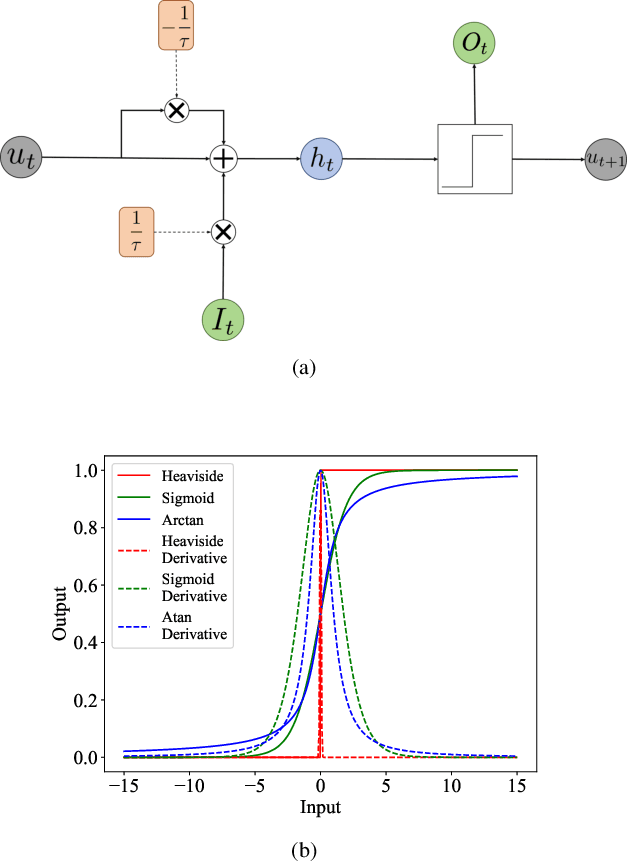
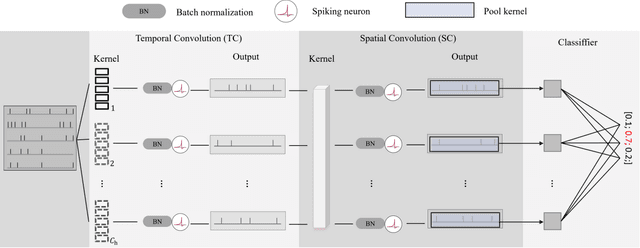
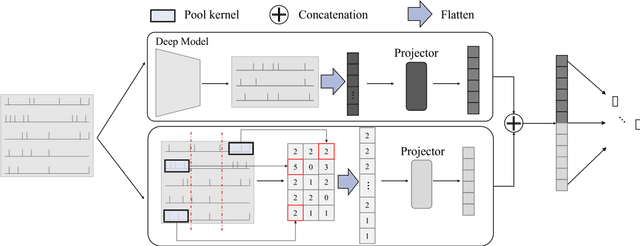
Decoding brain signals accurately and efficiently is crucial for intra-cortical brain-computer interfaces. Traditional decoding approaches based on neural activity vector features suffer from low accuracy, whereas deep learning based approaches have high computational cost. To improve both the decoding accuracy and efficiency, this paper proposes a spiking neural network (SNN) for effective and energy-efficient intra-cortical brain signal decoding. We also propose a feature fusion approach, which integrates the manually extracted neural activity vector features with those extracted by a deep neural network, to further improve the decoding accuracy. Experiments in decoding motor-related intra-cortical brain signals of two rhesus macaques demonstrated that our SNN model achieved higher accuracy than traditional artificial neural networks; more importantly, it was tens or hundreds of times more efficient. The SNN model is very suitable for high precision and low power applications like intra-cortical brain-computer interfaces.
Knowledge Retention for Continual Model-Based Reinforcement Learning
Mar 06, 2025



We propose DRAGO, a novel approach for continual model-based reinforcement learning aimed at improving the incremental development of world models across a sequence of tasks that differ in their reward functions but not the state space or dynamics. DRAGO comprises two key components: Synthetic Experience Rehearsal, which leverages generative models to create synthetic experiences from past tasks, allowing the agent to reinforce previously learned dynamics without storing data, and Regaining Memories Through Exploration, which introduces an intrinsic reward mechanism to guide the agent toward revisiting relevant states from prior tasks. Together, these components enable the agent to maintain a comprehensive and continually developing world model, facilitating more effective learning and adaptation across diverse environments. Empirical evaluations demonstrate that DRAGO is able to preserve knowledge across tasks, achieving superior performance in various continual learning scenarios.
ClearSight: Human Vision-Inspired Solutions for Event-Based Motion Deblurring
Jan 27, 2025



Motion deblurring addresses the challenge of image blur caused by camera or scene movement. Event cameras provide motion information that is encoded in the asynchronous event streams. To efficiently leverage the temporal information of event streams, we employ Spiking Neural Networks (SNNs) for motion feature extraction and Artificial Neural Networks (ANNs) for color information processing. Due to the non-uniform distribution and inherent redundancy of event data, existing cross-modal feature fusion methods exhibit certain limitations. Inspired by the visual attention mechanism in the human visual system, this study introduces a bioinspired dual-drive hybrid network (BDHNet). Specifically, the Neuron Configurator Module (NCM) is designed to dynamically adjusts neuron configurations based on cross-modal features, thereby focusing the spikes in blurry regions and adapting to varying blurry scenarios dynamically. Additionally, the Region of Blurry Attention Module (RBAM) is introduced to generate a blurry mask in an unsupervised manner, effectively extracting motion clues from the event features and guiding more accurate cross-modal feature fusion. Extensive subjective and objective evaluations demonstrate that our method outperforms current state-of-the-art methods on both synthetic and real-world datasets.
Frequency-aware Event Cloud Network
Dec 30, 2024



Event cameras are biologically inspired sensors that emit events asynchronously with remarkable temporal resolution, garnering significant attention from both industry and academia. Mainstream methods favor frame and voxel representations, which reach a satisfactory performance while introducing time-consuming transformation, bulky models, and sacrificing fine-grained temporal information. Alternatively, Point Cloud representation demonstrates promise in addressing the mentioned weaknesses, but it ignores the polarity information, and its models have limited proficiency in abstracting long-term events' features. In this paper, we propose a frequency-aware network named FECNet that leverages Event Cloud representations. FECNet fully utilizes 2S-1T-1P Event Cloud by innovating the event-based Group and Sampling module. To accommodate the long sequence events from Event Cloud, FECNet embraces feature extraction in the frequency domain via the Fourier transform. This approach substantially extinguishes the explosion of Multiply Accumulate Operations (MACs) while effectively abstracting spatial-temporal features. We conducted extensive experiments on event-based object classification, action recognition, and human pose estimation tasks, and the results substantiate the effectiveness and efficiency of FECNet.
Event-based Motion Deblurring via Multi-Temporal Granularity Fusion
Dec 16, 2024



Conventional frame-based cameras inevitably produce blurry effects due to motion occurring during the exposure time. Event camera, a bio-inspired sensor offering continuous visual information could enhance the deblurring performance. Effectively utilizing the high-temporal-resolution event data is crucial for extracting precise motion information and enhancing deblurring performance. However, existing event-based image deblurring methods usually utilize voxel-based event representations, losing the fine-grained temporal details that are mathematically essential for fast motion deblurring. In this paper, we first introduce point cloud-based event representation into the image deblurring task and propose a Multi-Temporal Granularity Network (MTGNet). It combines the spatially dense but temporally coarse-grained voxel-based event representation and the temporally fine-grained but spatially sparse point cloud-based event. To seamlessly integrate such complementary representations, we design a Fine-grained Point Branch. An Aggregation and Mapping Module (AMM) is proposed to align the low-level point-based features with frame-based features and an Adaptive Feature Diffusion Module (AFDM) is designed to manage the resolution discrepancies between event data and image data by enriching the sparse point feature. Extensive subjective and objective evaluations demonstrate that our method outperforms current state-of-the-art approaches on both synthetic and real-world datasets.
PRF: Parallel Resonate and Fire Neuron for Long Sequence Learning in Spiking Neural Networks
Oct 04, 2024Recently, there is growing demand for effective and efficient long sequence modeling, with State Space Models (SSMs) proving to be effective for long sequence tasks. To further reduce energy consumption, SSMs can be adapted to Spiking Neural Networks (SNNs) using spiking functions. However, current spiking-formalized SSMs approaches still rely on float-point matrix-vector multiplication during inference, undermining SNNs' energy advantage. In this work, we address the efficiency and performance challenges of long sequence learning in SNNs simultaneously. First, we propose a decoupled reset method for parallel spiking neuron training, reducing the typical Leaky Integrate-and-Fire (LIF) model's training time from $O(L^2)$ to $O(L\log L)$, effectively speeding up the training by $6.57 \times$ to $16.50 \times$ on sequence lengths $1,024$ to $32,768$. To our best knowledge, this is the first time that parallel computation with a reset mechanism is implemented achieving equivalence to its sequential counterpart. Secondly, to capture long-range dependencies, we propose a Parallel Resonate and Fire (PRF) neuron, which leverages an oscillating membrane potential driven by a resonate mechanism from a differentiable reset function in the complex domain. The PRF enables efficient long sequence learning while maintaining parallel training. Finally, we demonstrate that the proposed spike-driven architecture using PRF achieves performance comparable to Structured SSMs (S4), with two orders of magnitude reduction in energy consumption, outperforming Transformer on Long Range Arena tasks.
EPO: Hierarchical LLM Agents with Environment Preference Optimization
Aug 28, 2024



Long-horizon decision-making tasks present significant challenges for LLM-based agents due to the need for extensive planning over multiple steps. In this paper, we propose a hierarchical framework that decomposes complex tasks into manageable subgoals, utilizing separate LLMs for subgoal prediction and low-level action generation. To address the challenge of creating training signals for unannotated datasets, we develop a reward model that leverages multimodal environment feedback to automatically generate reward signals. We introduce Environment Preference Optimization (EPO), a novel method that generates preference signals from the environment's feedback and uses them to train LLM-based agents. Extensive experiments on ALFRED demonstrate the state-of-the-art performance of our framework, achieving first place on the ALFRED public leaderboard and showcasing its potential to improve long-horizon decision-making in diverse environments.
Rethinking Efficient and Effective Point-based Networks for Event Camera Classification and Regression: EventMamba
May 09, 2024Event cameras, drawing inspiration from biological systems, efficiently detect changes in ambient light with low latency and high dynamic range while consuming minimal power. The most current approach to processing event data often involves converting it into frame-based representations, which is well-established in traditional vision. However, this approach neglects the sparsity of event data, loses fine-grained temporal information during the transformation process, and increases the computational burden, making it ineffective for characterizing event camera properties. In contrast, Point Cloud is a popular representation for 3D processing and is better suited to match the sparse and asynchronous nature of the event camera. Nevertheless, despite the theoretical compatibility of point-based methods with event cameras, the results show a performance gap that is not yet satisfactory compared to frame-based methods. In order to bridge the performance gap, we propose EventMamba, an efficient and effective Point Cloud framework that achieves competitive results even compared to the state-of-the-art (SOTA) frame-based method in both classification and regression tasks. This notable accomplishment is facilitated by our rethinking of the distinction between Event Cloud and Point Cloud, emphasizing effective temporal information extraction through optimized network structures. Specifically, EventMamba leverages temporal aggregation and State Space Model (SSM) based Mamba boasting enhanced temporal information extraction capabilities. Through a hierarchical structure, EventMamba is adept at abstracting local and global spatial features and implicit and explicit temporal features. By adhering to the lightweight design principle, EventMamba delivers impressive results with minimal computational resource utilization, demonstrating its efficiency and effectiveness.
Model-based Reinforcement Learning for Parameterized Action Spaces
Apr 05, 2024



We propose a novel model-based reinforcement learning algorithm -- Dynamics Learning and predictive control with Parameterized Actions (DLPA) -- for Parameterized Action Markov Decision Processes (PAMDPs). The agent learns a parameterized-action-conditioned dynamics model and plans with a modified Model Predictive Path Integral control. We theoretically quantify the difference between the generated trajectory and the optimal trajectory during planning in terms of the value they achieved through the lens of Lipschitz Continuity. Our empirical results on several standard benchmarks show that our algorithm achieves superior sample efficiency and asymptotic performance than state-of-the-art PAMDP methods.
Language-guided Skill Learning with Temporal Variational Inference
Feb 26, 2024



We present an algorithm for skill discovery from expert demonstrations. The algorithm first utilizes Large Language Models (LLMs) to propose an initial segmentation of the trajectories. Following that, a hierarchical variational inference framework incorporates the LLM-generated segmentation information to discover reusable skills by merging trajectory segments. To further control the trade-off between compression and reusability, we introduce a novel auxiliary objective based on the Minimum Description Length principle that helps guide this skill discovery process. Our results demonstrate that agents equipped with our method are able to discover skills that help accelerate learning and outperform baseline skill learning approaches on new long-horizon tasks in BabyAI, a grid world navigation environment, as well as ALFRED, a household simulation environment.