 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLangForce: Bayesian Decomposition of Vision Language Action Models via Latent Action Queries
Jan 27, 2026Vision-Language-Action (VLA) models have shown promise in robot manipulation but often struggle to generalize to new instructions or complex multi-task scenarios. We identify a critical pathology in current training paradigms where goal-driven data collection creates a dataset bias. In such datasets, language instructions are highly predictable from visual observations alone, causing the conditional mutual information between instructions and actions to vanish, a phenomenon we term Information Collapse. Consequently, models degenerate into vision-only policies that ignore language constraints and fail in out-of-distribution (OOD) settings. To address this, we propose LangForce, a novel framework that enforces instruction following via Bayesian decomposition. By introducing learnable Latent Action Queries, we construct a dual-branch architecture to estimate both a vision-only prior $p(a \mid v)$ and a language-conditioned posterior $π(a \mid v, \ell)$. We then optimize the policy to maximize the conditional Pointwise Mutual Information (PMI) between actions and instructions. This objective effectively penalizes the vision shortcut and rewards actions that explicitly explain the language command. Without requiring new data, LangForce significantly improves generalization. Extensive experiments across on SimplerEnv and RoboCasa demonstrate substantial gains, including an 11.3% improvement on the challenging OOD SimplerEnv benchmark, validating the ability of our approach to robustly ground language in action.
BayesianVLA: Bayesian Decomposition of Vision Language Action Models via Latent Action Queries
Jan 21, 2026Vision-Language-Action (VLA) models have shown promise in robot manipulation but often struggle to generalize to new instructions or complex multi-task scenarios. We identify a critical pathology in current training paradigms where goal-driven data collection creates a dataset bias. In such datasets, language instructions are highly predictable from visual observations alone, causing the conditional mutual information between instructions and actions to vanish, a phenomenon we term Information Collapse. Consequently, models degenerate into vision-only policies that ignore language constraints and fail in out-of-distribution (OOD) settings. To address this, we propose BayesianVLA, a novel framework that enforces instruction following via Bayesian decomposition. By introducing learnable Latent Action Queries, we construct a dual-branch architecture to estimate both a vision-only prior $p(a \mid v)$ and a language-conditioned posterior $π(a \mid v, \ell)$. We then optimize the policy to maximize the conditional Pointwise Mutual Information (PMI) between actions and instructions. This objective effectively penalizes the vision shortcut and rewards actions that explicitly explain the language command. Without requiring new data, BayesianVLA significantly improves generalization. Extensive experiments across on SimplerEnv and RoboCasa demonstrate substantial gains, including an 11.3% improvement on the challenging OOD SimplerEnv benchmark, validating the ability of our approach to robustly ground language in action.
TwinBrainVLA: Unleashing the Potential of Generalist VLMs for Embodied Tasks via Asymmetric Mixture-of-Transformers
Jan 20, 2026Standard Vision-Language-Action (VLA) models typically fine-tune a monolithic Vision-Language Model (VLM) backbone explicitly for robotic control. However, this approach creates a critical tension between maintaining high-level general semantic understanding and learning low-level, fine-grained sensorimotor skills, often leading to "catastrophic forgetting" of the model's open-world capabilities. To resolve this conflict, we introduce TwinBrainVLA, a novel architecture that coordinates a generalist VLM retaining universal semantic understanding and a specialist VLM dedicated to embodied proprioception for joint robotic control. TwinBrainVLA synergizes a frozen "Left Brain", which retains robust general visual reasoning, with a trainable "Right Brain", specialized for embodied perception, via a novel Asymmetric Mixture-of-Transformers (AsyMoT) mechanism. This design allows the Right Brain to dynamically query semantic knowledge from the frozen Left Brain and fuse it with proprioceptive states, providing rich conditioning for a Flow-Matching Action Expert to generate precise continuous controls. Extensive experiments on SimplerEnv and RoboCasa benchmarks demonstrate that TwinBrainVLA achieves superior manipulation performance compared to state-of-the-art baselines while explicitly preserving the comprehensive visual understanding capabilities of the pre-trained VLM, offering a promising direction for building general-purpose robots that simultaneously achieve high-level semantic understanding and low-level physical dexterity.
PhysBrain: Human Egocentric Data as a Bridge from Vision Language Models to Physical Intelligence
Dec 18, 2025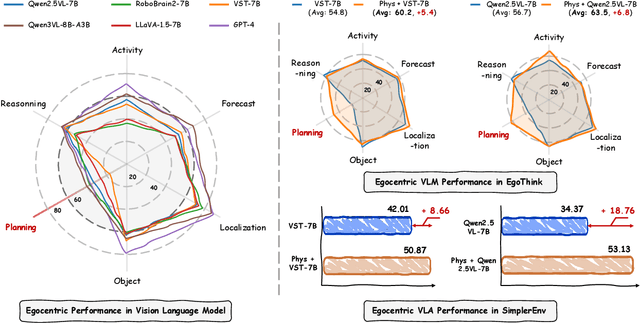
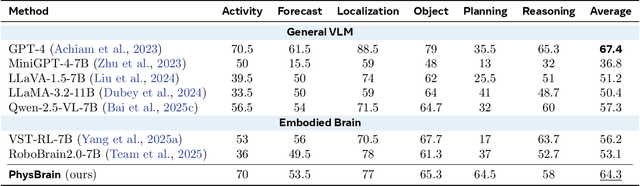
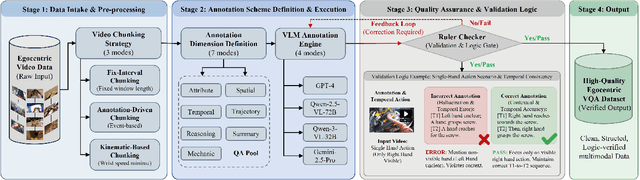
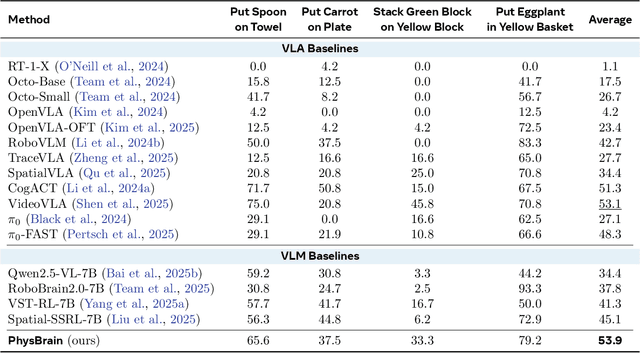
Robotic generalization relies on physical intelligence: the ability to reason about state changes, contact-rich interactions, and long-horizon planning under egocentric perception and action. However, most VLMs are trained primarily on third-person data, creating a fundamental viewpoint mismatch for humanoid robots. Scaling robot egocentric data collection remains impractical due to high cost and limited diversity, whereas large-scale human egocentric videos offer a scalable alternative that naturally capture rich interaction context and causal structure. The key challenge is to convert raw egocentric videos into structured and reliable embodiment training supervision. Accordingly, we propose an Egocentric2Embodiment translation pipeline that transforms first-person videos into multi-level, schema-driven VQA supervision with enforced evidence grounding and temporal consistency, enabling the construction of the Egocentric2Embodiment dataset (E2E-3M) at scale. An egocentric-aware embodied brain, termed PhysBrain, is obtained by training on the E2E-3M dataset. PhysBrain exhibits substantially improved egocentric understanding, particularly for planning on EgoThink. It provides an egocentric-aware initialization that enables more sample-efficient VLA fine-tuning and higher SimplerEnv success rates (53.9\%), demonstrating effective transfer from human egocentric supervision to downstream robot control.
Event-Based Eye Tracking. 2025 Event-based Vision Workshop
Apr 25, 2025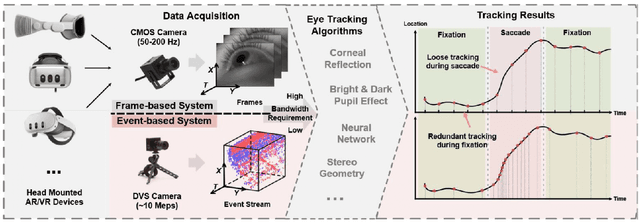
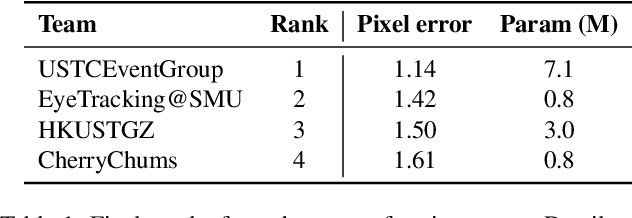

This survey serves as a review for the 2025 Event-Based Eye Tracking Challenge organized as part of the 2025 CVPR event-based vision workshop. This challenge focuses on the task of predicting the pupil center by processing event camera recorded eye movement. We review and summarize the innovative methods from teams rank the top in the challenge to advance future event-based eye tracking research. In each method, accuracy, model size, and number of operations are reported. In this survey, we also discuss event-based eye tracking from the perspective of hardware design.
Exploring Temporal Dynamics in Event-based Eye Tracker
Mar 31, 2025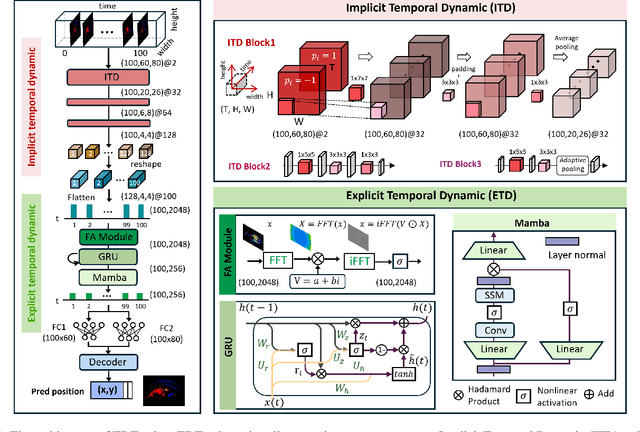
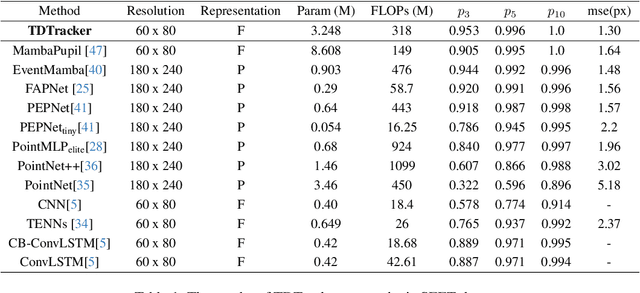
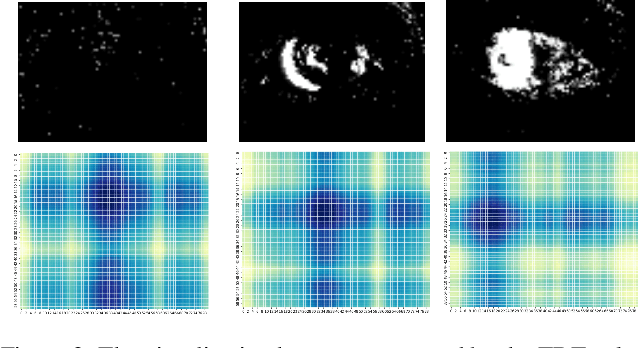

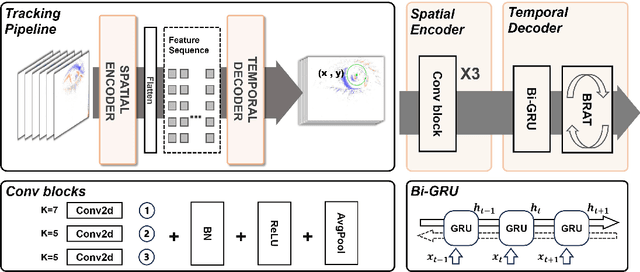
Eye-tracking is a vital technology for human-computer interaction, especially in wearable devices such as AR, VR, and XR. The realization of high-speed and high-precision eye-tracking using frame-based image sensors is constrained by their limited temporal resolution, which impairs the accurate capture of rapid ocular dynamics, such as saccades and blinks. Event cameras, inspired by biological vision systems, are capable of perceiving eye movements with extremely low power consumption and ultra-high temporal resolution. This makes them a promising solution for achieving high-speed, high-precision tracking with rich temporal dynamics. In this paper, we propose TDTracker, an effective eye-tracking framework that captures rapid eye movements by thoroughly modeling temporal dynamics from both implicit and explicit perspectives. TDTracker utilizes 3D convolutional neural networks to capture implicit short-term temporal dynamics and employs a cascaded structure consisting of a Frequency-aware Module, GRU, and Mamba to extract explicit long-term temporal dynamics. Ultimately, a prediction heatmap is used for eye coordinate regression. Experimental results demonstrate that TDTracker achieves state-of-the-art (SOTA) performance on the synthetic SEET dataset and secured Third place in the CVPR event-based eye-tracking challenge 2025. Our code is available at https://github.com/rhwxmx/TDTracker.
ClearSight: Human Vision-Inspired Solutions for Event-Based Motion Deblurring
Jan 27, 2025



Motion deblurring addresses the challenge of image blur caused by camera or scene movement. Event cameras provide motion information that is encoded in the asynchronous event streams. To efficiently leverage the temporal information of event streams, we employ Spiking Neural Networks (SNNs) for motion feature extraction and Artificial Neural Networks (ANNs) for color information processing. Due to the non-uniform distribution and inherent redundancy of event data, existing cross-modal feature fusion methods exhibit certain limitations. Inspired by the visual attention mechanism in the human visual system, this study introduces a bioinspired dual-drive hybrid network (BDHNet). Specifically, the Neuron Configurator Module (NCM) is designed to dynamically adjusts neuron configurations based on cross-modal features, thereby focusing the spikes in blurry regions and adapting to varying blurry scenarios dynamically. Additionally, the Region of Blurry Attention Module (RBAM) is introduced to generate a blurry mask in an unsupervised manner, effectively extracting motion clues from the event features and guiding more accurate cross-modal feature fusion. Extensive subjective and objective evaluations demonstrate that our method outperforms current state-of-the-art methods on both synthetic and real-world datasets.
Frequency-aware Event Cloud Network
Dec 30, 2024



Event cameras are biologically inspired sensors that emit events asynchronously with remarkable temporal resolution, garnering significant attention from both industry and academia. Mainstream methods favor frame and voxel representations, which reach a satisfactory performance while introducing time-consuming transformation, bulky models, and sacrificing fine-grained temporal information. Alternatively, Point Cloud representation demonstrates promise in addressing the mentioned weaknesses, but it ignores the polarity information, and its models have limited proficiency in abstracting long-term events' features. In this paper, we propose a frequency-aware network named FECNet that leverages Event Cloud representations. FECNet fully utilizes 2S-1T-1P Event Cloud by innovating the event-based Group and Sampling module. To accommodate the long sequence events from Event Cloud, FECNet embraces feature extraction in the frequency domain via the Fourier transform. This approach substantially extinguishes the explosion of Multiply Accumulate Operations (MACs) while effectively abstracting spatial-temporal features. We conducted extensive experiments on event-based object classification, action recognition, and human pose estimation tasks, and the results substantiate the effectiveness and efficiency of FECNet.
Event-based Motion Deblurring via Multi-Temporal Granularity Fusion
Dec 16, 2024



Conventional frame-based cameras inevitably produce blurry effects due to motion occurring during the exposure time. Event camera, a bio-inspired sensor offering continuous visual information could enhance the deblurring performance. Effectively utilizing the high-temporal-resolution event data is crucial for extracting precise motion information and enhancing deblurring performance. However, existing event-based image deblurring methods usually utilize voxel-based event representations, losing the fine-grained temporal details that are mathematically essential for fast motion deblurring. In this paper, we first introduce point cloud-based event representation into the image deblurring task and propose a Multi-Temporal Granularity Network (MTGNet). It combines the spatially dense but temporally coarse-grained voxel-based event representation and the temporally fine-grained but spatially sparse point cloud-based event. To seamlessly integrate such complementary representations, we design a Fine-grained Point Branch. An Aggregation and Mapping Module (AMM) is proposed to align the low-level point-based features with frame-based features and an Adaptive Feature Diffusion Module (AFDM) is designed to manage the resolution discrepancies between event data and image data by enriching the sparse point feature. Extensive subjective and objective evaluations demonstrate that our method outperforms current state-of-the-art approaches on both synthetic and real-world datasets.
PRF: Parallel Resonate and Fire Neuron for Long Sequence Learning in Spiking Neural Networks
Oct 04, 2024Recently, there is growing demand for effective and efficient long sequence modeling, with State Space Models (SSMs) proving to be effective for long sequence tasks. To further reduce energy consumption, SSMs can be adapted to Spiking Neural Networks (SNNs) using spiking functions. However, current spiking-formalized SSMs approaches still rely on float-point matrix-vector multiplication during inference, undermining SNNs' energy advantage. In this work, we address the efficiency and performance challenges of long sequence learning in SNNs simultaneously. First, we propose a decoupled reset method for parallel spiking neuron training, reducing the typical Leaky Integrate-and-Fire (LIF) model's training time from $O(L^2)$ to $O(L\log L)$, effectively speeding up the training by $6.57 \times$ to $16.50 \times$ on sequence lengths $1,024$ to $32,768$. To our best knowledge, this is the first time that parallel computation with a reset mechanism is implemented achieving equivalence to its sequential counterpart. Secondly, to capture long-range dependencies, we propose a Parallel Resonate and Fire (PRF) neuron, which leverages an oscillating membrane potential driven by a resonate mechanism from a differentiable reset function in the complex domain. The PRF enables efficient long sequence learning while maintaining parallel training. Finally, we demonstrate that the proposed spike-driven architecture using PRF achieves performance comparable to Structured SSMs (S4), with two orders of magnitude reduction in energy consumption, outperforming Transformer on Long Range Arena tasks.