 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePrefixAgent: An LLM-Powered Design Framework for Efficient Prefix Adder Optimization
Jul 08, 2025Prefix adders are fundamental arithmetic circuits, but their design space grows exponentially with bit-width, posing significant optimization challenges. Previous works face limitations in performance, generalization, and scalability. To address these challenges, we propose PrefixAgent, a large language model (LLM)-powered framework that enables efficient prefix adder optimization. Specifically, PrefixAgent reformulates the problem into subtasks including backbone synthesis and structure refinement, which effectively reduces the search space. More importantly, this new design perspective enables us to efficiently collect enormous high-quality data and reasoning traces with E-graph, which further results in an effective fine-tuning of LLM. Experimental results show that PrefixAgent synthesizes prefix adders with consistently smaller areas compared to baseline methods, while maintaining scalability and generalization in commercial EDA flows.
Rethinking Efficient and Effective Point-based Networks for Event Camera Classification and Regression: EventMamba
May 09, 2024Event cameras, drawing inspiration from biological systems, efficiently detect changes in ambient light with low latency and high dynamic range while consuming minimal power. The most current approach to processing event data often involves converting it into frame-based representations, which is well-established in traditional vision. However, this approach neglects the sparsity of event data, loses fine-grained temporal information during the transformation process, and increases the computational burden, making it ineffective for characterizing event camera properties. In contrast, Point Cloud is a popular representation for 3D processing and is better suited to match the sparse and asynchronous nature of the event camera. Nevertheless, despite the theoretical compatibility of point-based methods with event cameras, the results show a performance gap that is not yet satisfactory compared to frame-based methods. In order to bridge the performance gap, we propose EventMamba, an efficient and effective Point Cloud framework that achieves competitive results even compared to the state-of-the-art (SOTA) frame-based method in both classification and regression tasks. This notable accomplishment is facilitated by our rethinking of the distinction between Event Cloud and Point Cloud, emphasizing effective temporal information extraction through optimized network structures. Specifically, EventMamba leverages temporal aggregation and State Space Model (SSM) based Mamba boasting enhanced temporal information extraction capabilities. Through a hierarchical structure, EventMamba is adept at abstracting local and global spatial features and implicit and explicit temporal features. By adhering to the lightweight design principle, EventMamba delivers impressive results with minimal computational resource utilization, demonstrating its efficiency and effectiveness.
RL-MUL: Multiplier Design Optimization with Deep Reinforcement Learning
Mar 31, 2024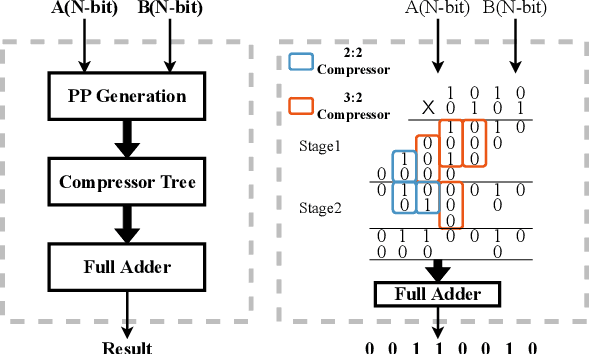
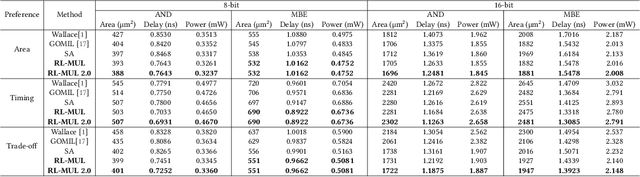
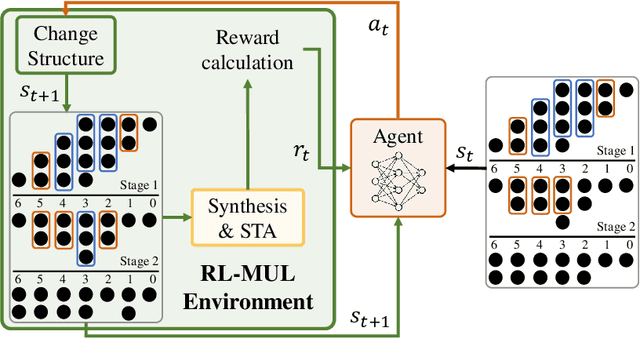

Multiplication is a fundamental operation in many applications, and multipliers are widely adopted in various circuits. However, optimizing multipliers is challenging and non-trivial due to the huge design space. In this paper, we propose RL-MUL, a multiplier design optimization framework based on reinforcement learning. Specifically, we utilize matrix and tensor representations for the compressor tree of a multiplier, based on which the convolutional neural networks can be seamlessly incorporated as the agent network. The agent can learn to optimize the multiplier structure based on a Pareto-driven reward which is customized to accommodate the trade-off between area and delay. Additionally, the capability of RL-MUL is extended to optimize the fused multiply-accumulator (MAC) designs. Experiments are conducted on different bit widths of multipliers. The results demonstrate that the multipliers produced by RL-MUL can dominate all baseline designs in terms of area and delay. The performance gain of RL-MUL is further validated by comparing the area and delay of processing element arrays using multipliers from RL-MUL and baseline approaches.
A Simple and Effective Point-based Network for Event Camera 6-DOFs Pose Relocalization
Mar 28, 2024



Event cameras exhibit remarkable attributes such as high dynamic range, asynchronicity, and low latency, making them highly suitable for vision tasks that involve high-speed motion in challenging lighting conditions. These cameras implicitly capture movement and depth information in events, making them appealing sensors for Camera Pose Relocalization (CPR) tasks. Nevertheless, existing CPR networks based on events neglect the pivotal fine-grained temporal information in events, resulting in unsatisfactory performance. Moreover, the energy-efficient features are further compromised by the use of excessively complex models, hindering efficient deployment on edge devices. In this paper, we introduce PEPNet, a simple and effective point-based network designed to regress six degrees of freedom (6-DOFs) event camera poses. We rethink the relationship between the event camera and CPR tasks, leveraging the raw Point Cloud directly as network input to harness the high-temporal resolution and inherent sparsity of events. PEPNet is adept at abstracting the spatial and implicit temporal features through hierarchical structure and explicit temporal features by Attentive Bi-directional Long Short-Term Memory (A-Bi-LSTM). By employing a carefully crafted lightweight design, PEPNet delivers state-of-the-art (SOTA) performance on both indoor and outdoor datasets with meager computational resources. Specifically, PEPNet attains a significant 38% and 33% performance improvement on the random split IJRR and M3ED datasets, respectively. Moreover, the lightweight design version PEPNet$_{tiny}$ accomplishes results comparable to the SOTA while employing a mere 0.5% of the parameters.