 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnveiling Inference Scaling for Difference-Aware User Modeling in LLM Personalization
Nov 19, 2025Large Language Models (LLMs) are increasingly integrated into users' daily lives, driving a growing demand for personalized outputs. Prior work has primarily leveraged a user's own history, often overlooking inter-user differences that are critical for effective personalization. While recent methods have attempted to model such differences, their feature extraction processes typically rely on fixed dimensions and quick, intuitive inference (System-1 thinking), limiting both the coverage and granularity of captured user differences. To address these limitations, we propose Difference-aware Reasoning Personalization (DRP), a framework that reconstructs the difference extraction mechanism by leveraging inference scaling to enhance LLM personalization. DRP autonomously identifies relevant difference feature dimensions and generates structured definitions and descriptions, enabling slow, deliberate reasoning (System-2 thinking) over user differences. Experiments on personalized review generation demonstrate that DRP consistently outperforms baseline methods across multiple metrics.
SpikingMamba: Towards Energy-Efficient Large Language Models via Knowledge Distillation from Mamba
Oct 06, 2025
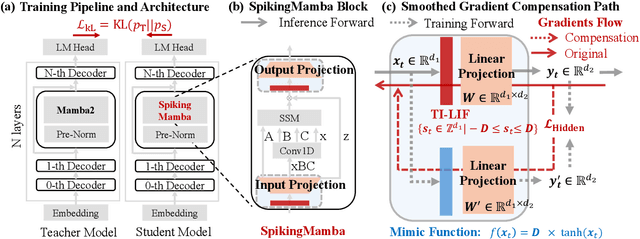


Large Language Models (LLMs) have achieved remarkable performance across tasks but remain energy-intensive due to dense matrix operations. Spiking neural networks (SNNs) improve energy efficiency by replacing dense matrix multiplications with sparse accumulations. Their sparse spike activity enables efficient LLMs deployment on edge devices. However, prior SNN-based LLMs often sacrifice performance for efficiency, and recovering accuracy typically requires full pretraining, which is costly and impractical. To address this, we propose SpikingMamba, an energy-efficient SNN-based LLMs distilled from Mamba that improves energy efficiency with minimal accuracy sacrifice. SpikingMamba integrates two key components: (a) TI-LIF, a ternary-integer spiking neuron that preserves semantic polarity through signed multi-level spike representations. (b) A training-exclusive Smoothed Gradient Compensation (SGC) path mitigating quantization loss while preserving spike-driven efficiency. We employ a single-stage distillation strategy to transfer the zero-shot ability of pretrained Mamba and further enhance it via reinforcement learning (RL). Experiments show that SpikingMamba-1.3B achieves a 4.76$\times$ energy benefit, with only a 4.78\% zero-shot accuracy gap compared to the original Mamba, and achieves a further 2.55\% accuracy improvement after RL.
ClearSight: Human Vision-Inspired Solutions for Event-Based Motion Deblurring
Jan 27, 2025



Motion deblurring addresses the challenge of image blur caused by camera or scene movement. Event cameras provide motion information that is encoded in the asynchronous event streams. To efficiently leverage the temporal information of event streams, we employ Spiking Neural Networks (SNNs) for motion feature extraction and Artificial Neural Networks (ANNs) for color information processing. Due to the non-uniform distribution and inherent redundancy of event data, existing cross-modal feature fusion methods exhibit certain limitations. Inspired by the visual attention mechanism in the human visual system, this study introduces a bioinspired dual-drive hybrid network (BDHNet). Specifically, the Neuron Configurator Module (NCM) is designed to dynamically adjusts neuron configurations based on cross-modal features, thereby focusing the spikes in blurry regions and adapting to varying blurry scenarios dynamically. Additionally, the Region of Blurry Attention Module (RBAM) is introduced to generate a blurry mask in an unsupervised manner, effectively extracting motion clues from the event features and guiding more accurate cross-modal feature fusion. Extensive subjective and objective evaluations demonstrate that our method outperforms current state-of-the-art methods on both synthetic and real-world datasets.
Frequency-aware Event Cloud Network
Dec 30, 2024



Event cameras are biologically inspired sensors that emit events asynchronously with remarkable temporal resolution, garnering significant attention from both industry and academia. Mainstream methods favor frame and voxel representations, which reach a satisfactory performance while introducing time-consuming transformation, bulky models, and sacrificing fine-grained temporal information. Alternatively, Point Cloud representation demonstrates promise in addressing the mentioned weaknesses, but it ignores the polarity information, and its models have limited proficiency in abstracting long-term events' features. In this paper, we propose a frequency-aware network named FECNet that leverages Event Cloud representations. FECNet fully utilizes 2S-1T-1P Event Cloud by innovating the event-based Group and Sampling module. To accommodate the long sequence events from Event Cloud, FECNet embraces feature extraction in the frequency domain via the Fourier transform. This approach substantially extinguishes the explosion of Multiply Accumulate Operations (MACs) while effectively abstracting spatial-temporal features. We conducted extensive experiments on event-based object classification, action recognition, and human pose estimation tasks, and the results substantiate the effectiveness and efficiency of FECNet.
Event-based Motion Deblurring via Multi-Temporal Granularity Fusion
Dec 16, 2024



Conventional frame-based cameras inevitably produce blurry effects due to motion occurring during the exposure time. Event camera, a bio-inspired sensor offering continuous visual information could enhance the deblurring performance. Effectively utilizing the high-temporal-resolution event data is crucial for extracting precise motion information and enhancing deblurring performance. However, existing event-based image deblurring methods usually utilize voxel-based event representations, losing the fine-grained temporal details that are mathematically essential for fast motion deblurring. In this paper, we first introduce point cloud-based event representation into the image deblurring task and propose a Multi-Temporal Granularity Network (MTGNet). It combines the spatially dense but temporally coarse-grained voxel-based event representation and the temporally fine-grained but spatially sparse point cloud-based event. To seamlessly integrate such complementary representations, we design a Fine-grained Point Branch. An Aggregation and Mapping Module (AMM) is proposed to align the low-level point-based features with frame-based features and an Adaptive Feature Diffusion Module (AFDM) is designed to manage the resolution discrepancies between event data and image data by enriching the sparse point feature. Extensive subjective and objective evaluations demonstrate that our method outperforms current state-of-the-art approaches on both synthetic and real-world datasets.
PRF: Parallel Resonate and Fire Neuron for Long Sequence Learning in Spiking Neural Networks
Oct 04, 2024Recently, there is growing demand for effective and efficient long sequence modeling, with State Space Models (SSMs) proving to be effective for long sequence tasks. To further reduce energy consumption, SSMs can be adapted to Spiking Neural Networks (SNNs) using spiking functions. However, current spiking-formalized SSMs approaches still rely on float-point matrix-vector multiplication during inference, undermining SNNs' energy advantage. In this work, we address the efficiency and performance challenges of long sequence learning in SNNs simultaneously. First, we propose a decoupled reset method for parallel spiking neuron training, reducing the typical Leaky Integrate-and-Fire (LIF) model's training time from $O(L^2)$ to $O(L\log L)$, effectively speeding up the training by $6.57 \times$ to $16.50 \times$ on sequence lengths $1,024$ to $32,768$. To our best knowledge, this is the first time that parallel computation with a reset mechanism is implemented achieving equivalence to its sequential counterpart. Secondly, to capture long-range dependencies, we propose a Parallel Resonate and Fire (PRF) neuron, which leverages an oscillating membrane potential driven by a resonate mechanism from a differentiable reset function in the complex domain. The PRF enables efficient long sequence learning while maintaining parallel training. Finally, we demonstrate that the proposed spike-driven architecture using PRF achieves performance comparable to Structured SSMs (S4), with two orders of magnitude reduction in energy consumption, outperforming Transformer on Long Range Arena tasks.
A 7K Parameter Model for Underwater Image Enhancement based on Transmission Map Prior
May 25, 2024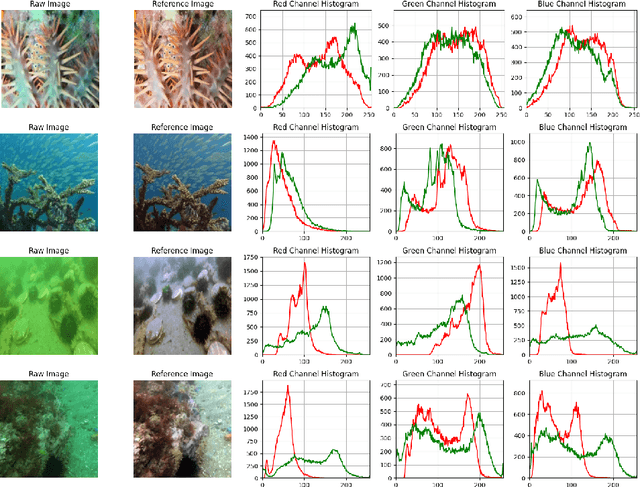
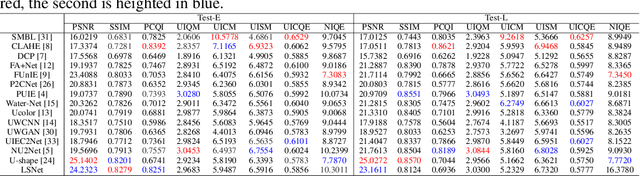
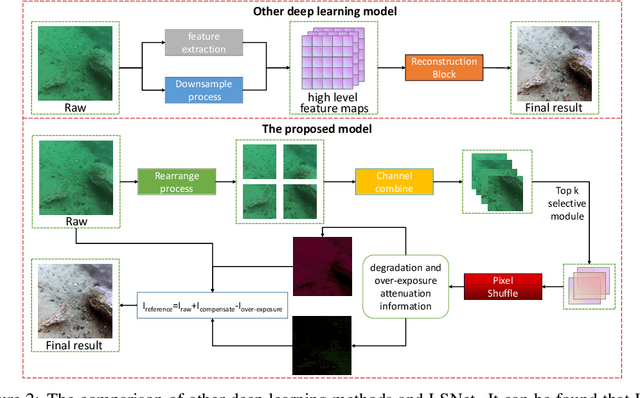
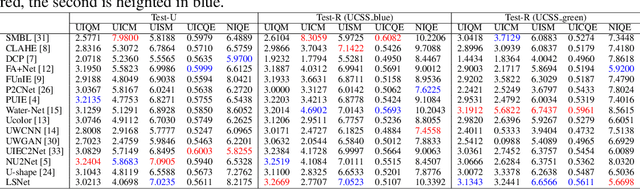
Although deep learning based models for underwater image enhancement have achieved good performance, they face limitations in both lightweight and effectiveness, which prevents their deployment and application on resource-constrained platforms. Moreover, most existing deep learning based models use data compression to get high-level semantic information in latent space instead of using the original information. Therefore, they require decoder blocks to generate the details of the output. This requires additional computational cost. In this paper, a lightweight network named lightweight selective attention network (LSNet) based on the top-k selective attention and transmission maps mechanism is proposed. The proposed model achieves a PSNR of 97\% with only 7K parameters compared to a similar attention-based model. Extensive experiments show that the proposed LSNet achieves excellent performance in state-of-the-art models with significantly fewer parameters and computational resources. The code is available at https://github.com/FuhengZhou/LSNet}{https://github.com/FuhengZhou/LSNet.
Rethinking Efficient and Effective Point-based Networks for Event Camera Classification and Regression: EventMamba
May 09, 2024Event cameras, drawing inspiration from biological systems, efficiently detect changes in ambient light with low latency and high dynamic range while consuming minimal power. The most current approach to processing event data often involves converting it into frame-based representations, which is well-established in traditional vision. However, this approach neglects the sparsity of event data, loses fine-grained temporal information during the transformation process, and increases the computational burden, making it ineffective for characterizing event camera properties. In contrast, Point Cloud is a popular representation for 3D processing and is better suited to match the sparse and asynchronous nature of the event camera. Nevertheless, despite the theoretical compatibility of point-based methods with event cameras, the results show a performance gap that is not yet satisfactory compared to frame-based methods. In order to bridge the performance gap, we propose EventMamba, an efficient and effective Point Cloud framework that achieves competitive results even compared to the state-of-the-art (SOTA) frame-based method in both classification and regression tasks. This notable accomplishment is facilitated by our rethinking of the distinction between Event Cloud and Point Cloud, emphasizing effective temporal information extraction through optimized network structures. Specifically, EventMamba leverages temporal aggregation and State Space Model (SSM) based Mamba boasting enhanced temporal information extraction capabilities. Through a hierarchical structure, EventMamba is adept at abstracting local and global spatial features and implicit and explicit temporal features. By adhering to the lightweight design principle, EventMamba delivers impressive results with minimal computational resource utilization, demonstrating its efficiency and effectiveness.
A Simple and Effective Point-based Network for Event Camera 6-DOFs Pose Relocalization
Mar 28, 2024



Event cameras exhibit remarkable attributes such as high dynamic range, asynchronicity, and low latency, making them highly suitable for vision tasks that involve high-speed motion in challenging lighting conditions. These cameras implicitly capture movement and depth information in events, making them appealing sensors for Camera Pose Relocalization (CPR) tasks. Nevertheless, existing CPR networks based on events neglect the pivotal fine-grained temporal information in events, resulting in unsatisfactory performance. Moreover, the energy-efficient features are further compromised by the use of excessively complex models, hindering efficient deployment on edge devices. In this paper, we introduce PEPNet, a simple and effective point-based network designed to regress six degrees of freedom (6-DOFs) event camera poses. We rethink the relationship between the event camera and CPR tasks, leveraging the raw Point Cloud directly as network input to harness the high-temporal resolution and inherent sparsity of events. PEPNet is adept at abstracting the spatial and implicit temporal features through hierarchical structure and explicit temporal features by Attentive Bi-directional Long Short-Term Memory (A-Bi-LSTM). By employing a carefully crafted lightweight design, PEPNet delivers state-of-the-art (SOTA) performance on both indoor and outdoor datasets with meager computational resources. Specifically, PEPNet attains a significant 38% and 33% performance improvement on the random split IJRR and M3ED datasets, respectively. Moreover, the lightweight design version PEPNet$_{tiny}$ accomplishes results comparable to the SOTA while employing a mere 0.5% of the parameters.
CLIF: Complementary Leaky Integrate-and-Fire Neuron for Spiking Neural Networks
Feb 08, 2024



Spiking neural networks (SNNs) are promising brain-inspired energy-efficient models. Compared to conventional deep Artificial Neural Networks (ANNs), SNNs exhibit superior efficiency and capability to process temporal information. However, it remains a challenge to train SNNs due to their undifferentiable spiking mechanism. The surrogate gradients method is commonly used to train SNNs, but often comes with an accuracy disadvantage over ANNs counterpart. We link the degraded accuracy to the vanishing of gradient on the temporal dimension through the analytical and experimental study of the training process of Leaky Integrate-and-Fire (LIF) Neuron-based SNNs. Moreover, we propose the Complementary Leaky Integrate-and-Fire (CLIF) Neuron. CLIF creates extra paths to facilitate the backpropagation in computing temporal gradient while keeping binary output. CLIF is hyperparameter-free and features broad applicability. Extensive experiments on a variety of datasets demonstrate CLIF's clear performance advantage over other neuron models. Moreover, the CLIF's performance even slightly surpasses superior ANNs with identical network structure and training conditions.