 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFedRG: Unleashing the Representation Geometry for Federated Learning with Noisy Clients
Mar 20, 2026Federated learning (FL) suffers from performance degradation due to the inevitable presence of noisy annotations in distributed scenarios. Existing approaches have advanced in distinguishing noisy samples from the dataset for label correction by leveraging loss values. However, noisy samples recognition relying on scalar loss lacks reliability for FL under heterogeneous scenarios. In this paper, we rethink this paradigm from a representation perspective and propose \method~(\textbf{Fed}erated under \textbf{R}epresentation \textbf{G}emometry), which follows \textbf{the principle of ``representation geometry priority''} to recognize noisy labels. Firstly, \method~creates label-agnostic spherical representations by using self-supervision. It then iteratively fits a spherical von Mises-Fisher (vMF) mixture model to this geometry using previously identified clean samples to capture semantic clusters. This geometric evidence is integrated with a semantic-label soft mapping mechanism to derive a distribution divergence between the label-free and annotated label-conditioned feature space, which robustly identifies noisy samples and updates the vMF mixture model with the newly separated clean dataset. Lastly, we employ an additional personalized noise absorption matrix on noisy labels to achieve robust optimization. Extensive experimental results demonstrate that \method~significantly outperforms state-of-the-art methods for FL with data heterogeneity under diverse noisy clients scenarios.
From Scalar Rewards to Potential Trends: Shaping Potential Landscapes for Model-Based Reinforcement Learning
Feb 03, 2026Model-based reinforcement learning (MBRL) achieves high sample efficiency by simulating future trajectories with learned dynamics and reward models. However, its effectiveness is severely compromised in sparse reward settings. The core limitation lies in the standard paradigm of regressing ground-truth scalar rewards: in sparse environments, this yields a flat, gradient-free landscape that fails to provide directional guidance for planning. To address this challenge, we propose Shaping Landscapes with Optimistic Potential Estimates (SLOPE), a novel framework that shifts reward modeling from predicting scalars to constructing informative potential landscapes. SLOPE employs optimistic distributional regression to estimate high-confidence upper bounds, which amplifies rare success signals and ensures sufficient exploration gradients. Evaluations on 30+ tasks across 5 benchmarks demonstrate that SLOPE consistently outperforms leading baselines in fully sparse, semi-sparse, and dense rewards.
IFFair: Influence Function-driven Sample Reweighting for Fair Classification
Dec 08, 2025
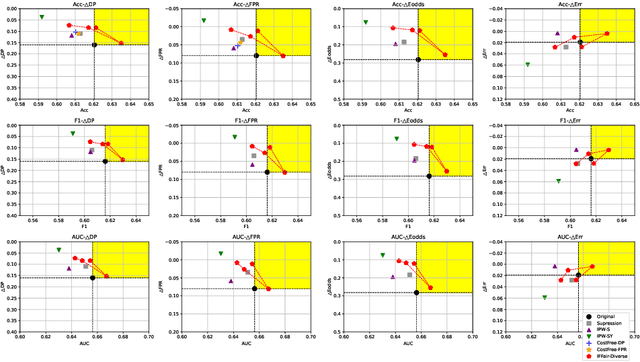
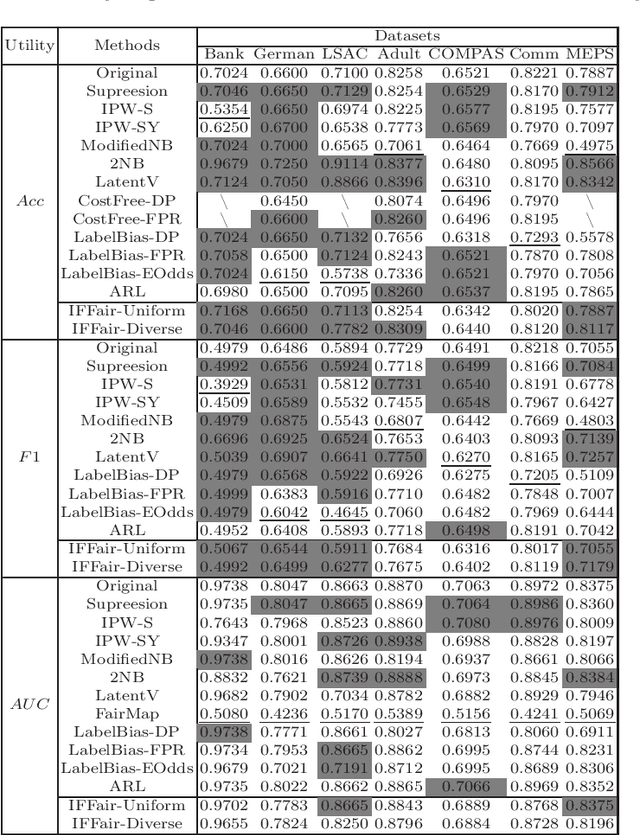
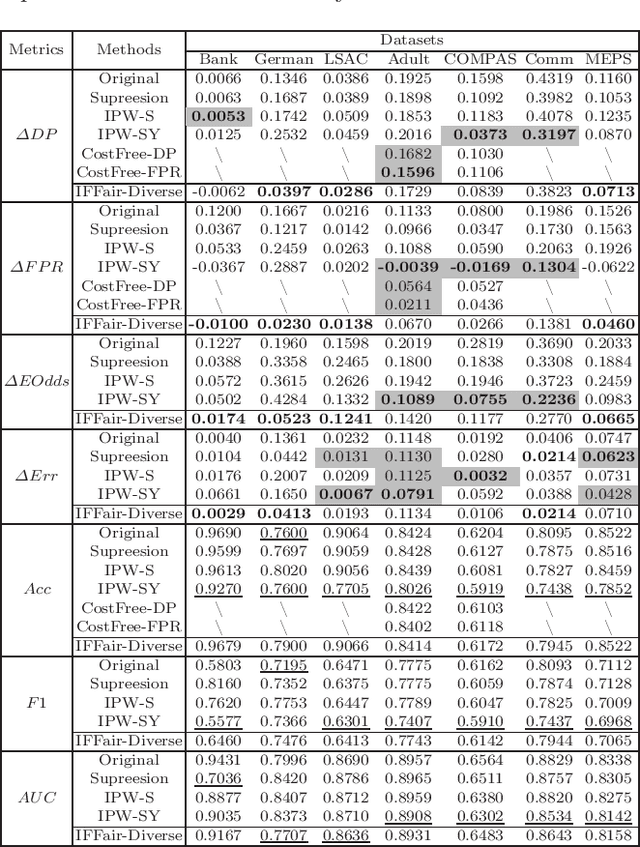
Because machine learning has significantly improved efficiency and convenience in the society, it's increasingly used to assist or replace human decision-making. However, the data-based pattern makes related algorithms learn and even exacerbate potential bias in samples, resulting in discriminatory decisions against certain unprivileged groups, depriving them of the rights to equal treatment, thus damaging the social well-being and hindering the development of related applications. Therefore, we propose a pre-processing method IFFair based on the influence function. Compared with other fairness optimization approaches, IFFair only uses the influence disparity of training samples on different groups as a guidance to dynamically adjust the sample weights during training without modifying the network structure, data features and decision boundaries. To evaluate the validity of IFFair, we conduct experiments on multiple real-world datasets and metrics. The experimental results show that our approach mitigates bias of multiple accepted metrics in the classification setting, including demographic parity, equalized odds, equality of opportunity and error rate parity without conflicts. It also demonstrates that IFFair achieves better trade-off between multiple utility and fairness metrics compared with previous pre-processing methods.
Enhancing Target-unspecific Tasks through a Features Matrix
May 07, 2025Recent developments in prompt learning of large vision-language models have significantly improved performance in target-specific tasks. However, these prompt optimizing methods often struggle to tackle the target-unspecific or generalizable tasks effectively. It may be attributed to the fact that overfitting training causes the model to forget its general knowledge having strong promotion on target-unspecific tasks. To alleviate this issue, we propose a novel Features Matrix (FM) regularization approach designed to enhance these models on target-unspecific tasks. Our method extracts and leverages general knowledge, shaping a Features Matrix (FM). Specifically, the FM captures the semantics of diverse inputs from a deep and fine perspective, preserving essential general knowledge, which mitigates the risk of overfitting. Representative evaluations demonstrate that: 1) the FM is compatible with existing frameworks as a generic and flexible module, and 2) the FM significantly showcases its effectiveness in enhancing target-unspecific tasks, achieving state-of-the-art performance.
* ICML 2025
Leveraging Submodule Linearity Enhances Task Arithmetic Performance in LLMs
Apr 15, 2025
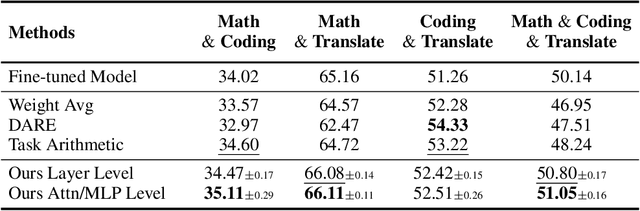

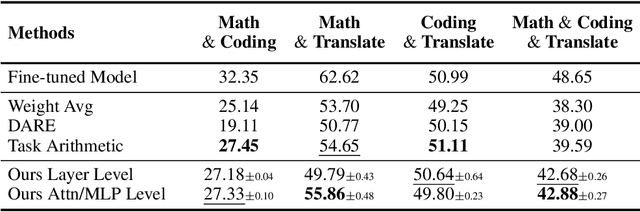
Task arithmetic is a straightforward yet highly effective strategy for model merging, enabling the resultant model to exhibit multi-task capabilities. Recent research indicates that models demonstrating linearity enhance the performance of task arithmetic. In contrast to existing methods that rely on the global linearization of the model, we argue that this linearity already exists within the model's submodules. In particular, we present a statistical analysis and show that submodules (e.g., layers, self-attentions, and MLPs) exhibit significantly higher linearity than the overall model. Based on these findings, we propose an innovative model merging strategy that independently merges these submodules. Especially, we derive a closed-form solution for optimal merging weights grounded in the linear properties of these submodules. Experimental results demonstrate that our method consistently outperforms the standard task arithmetic approach and other established baselines across different model scales and various tasks. This result highlights the benefits of leveraging the linearity of submodules and provides a new perspective for exploring solutions for effective and practical multi-task model merging.
Generalizable Prompt Learning of CLIP: A Brief Overview
Mar 03, 2025
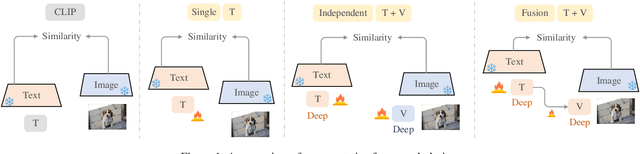

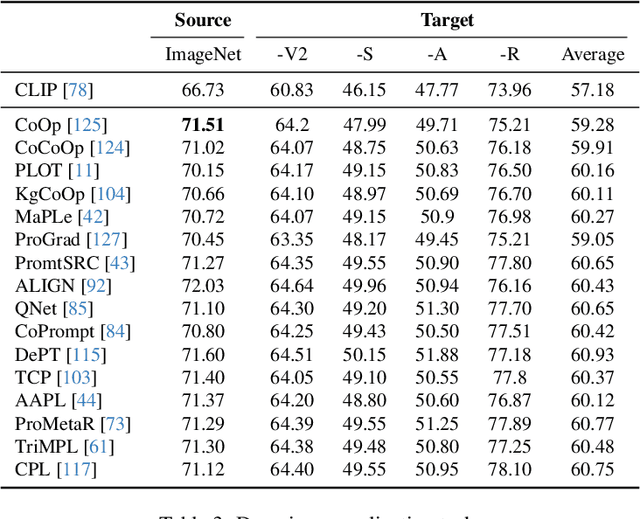
Existing vision-language models (VLMs) such as CLIP have showcased an impressive capability to generalize well across various downstream tasks. These models leverage the synergy between visual and textual information, enabling them to understand and reason about the content present in images and text in a unified manner. This article provides a brief overview of CLIP based on few-shot prompt learning, including experimental data and technical characteristics of some methods. The purpose of this review is to provide a reference for researchers who have just started their research in generalizable prompting of CLIP through few-shot training for classification across 15 datasets and also to facilitate the integration of this field by researchers in other downstream tasks.
Detecting Discrepancies Between AI-Generated and Natural Images Using Uncertainty
Dec 08, 2024



In this work, we propose a novel approach for detecting AI-generated images by leveraging predictive uncertainty to mitigate misuse and associated risks. The motivation arises from the fundamental assumption regarding the distributional discrepancy between natural and AI-generated images. The feasibility of distinguishing natural images from AI-generated ones is grounded in the distribution discrepancy between them. Predictive uncertainty offers an effective approach for capturing distribution shifts, thereby providing insights into detecting AI-generated images. Namely, as the distribution shift between training and testing data increases, model performance typically degrades, often accompanied by increased predictive uncertainty. Therefore, we propose to employ predictive uncertainty to reflect the discrepancies between AI-generated and natural images. In this context, the challenge lies in ensuring that the model has been trained over sufficient natural images to avoid the risk of determining the distribution of natural images as that of generated images. We propose to leverage large-scale pre-trained models to calculate the uncertainty as the score for detecting AI-generated images. This leads to a simple yet effective method for detecting AI-generated images using large-scale vision models: images that induce high uncertainty are identified as AI-generated. Comprehensive experiments across multiple benchmarks demonstrate the effectiveness of our method.
Enhancing Multiple Dimensions of Trustworthiness in LLMs via Sparse Activation Control
Nov 04, 2024



As the development and application of Large Language Models (LLMs) continue to advance rapidly, enhancing their trustworthiness and aligning them with human preferences has become a critical area of research. Traditional methods rely heavily on extensive data for Reinforcement Learning from Human Feedback (RLHF), but representation engineering offers a new, training-free approach. This technique leverages semantic features to control the representation of LLM's intermediate hidden states, enabling the model to meet specific requirements such as increased honesty or heightened safety awareness. However, a significant challenge arises when attempting to fulfill multiple requirements simultaneously. It proves difficult to encode various semantic contents, like honesty and safety, into a singular semantic feature, restricting its practicality. In this work, we address this issue through ``Sparse Activation Control''. By delving into the intrinsic mechanisms of LLMs, we manage to identify and pinpoint components that are closely related to specific tasks within the model, i.e., attention heads. These heads display sparse characteristics that allow for near-independent control over different tasks. Our experiments, conducted on the open-source Llama series models, have yielded encouraging results. The models were able to align with human preferences on issues of safety, factuality, and bias concurrently.
FuseFL: One-Shot Federated Learning through the Lens of Causality with Progressive Model Fusion
Oct 27, 2024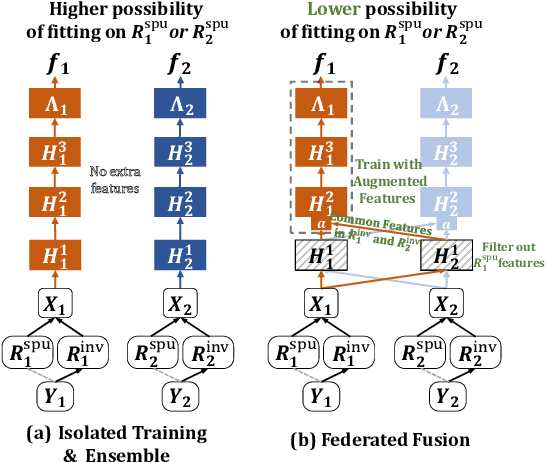
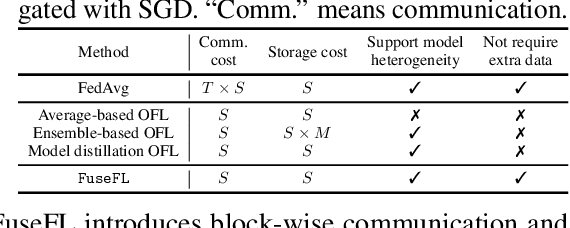
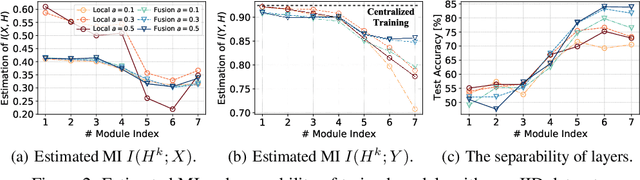
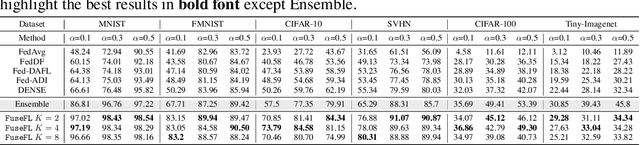
One-shot Federated Learning (OFL) significantly reduces communication costs in FL by aggregating trained models only once. However, the performance of advanced OFL methods is far behind the normal FL. In this work, we provide a causal view to find that this performance drop of OFL methods comes from the isolation problem, which means that local isolatedly trained models in OFL may easily fit to spurious correlations due to the data heterogeneity. From the causal perspective, we observe that the spurious fitting can be alleviated by augmenting intermediate features from other clients. Built upon our observation, we propose a novel learning approach to endow OFL with superb performance and low communication and storage costs, termed as FuseFL. Specifically, FuseFL decomposes neural networks into several blocks, and progressively trains and fuses each block following a bottom-up manner for feature augmentation, introducing no additional communication costs. Comprehensive experiments demonstrate that FuseFL outperforms existing OFL and ensemble FL by a significant margin. We conduct comprehensive experiments to show that FuseFL supports high scalability of clients, heterogeneous model training, and low memory costs. Our work is the first attempt using causality to analyze and alleviate data heterogeneity of OFL.
From Yes-Men to Truth-Tellers: Addressing Sycophancy in Large Language Models with Pinpoint Tuning
Sep 03, 2024



Large Language Models (LLMs) tend to prioritize adherence to user prompts over providing veracious responses, leading to the sycophancy issue. When challenged by users, LLMs tend to admit mistakes and provide inaccurate responses even if they initially provided the correct answer. Recent works propose to employ supervised fine-tuning (SFT) to mitigate the sycophancy issue, while it typically leads to the degeneration of LLMs' general capability. To address the challenge, we propose a novel supervised pinpoint tuning (SPT), where the region-of-interest modules are tuned for a given objective. Specifically, SPT first reveals and verifies a small percentage (<5%) of the basic modules, which significantly affect a particular behavior of LLMs. i.e., sycophancy. Subsequently, SPT merely fine-tunes these identified modules while freezing the rest. To verify the effectiveness of the proposed SPT, we conduct comprehensive experiments, demonstrating that SPT significantly mitigates the sycophancy issue of LLMs (even better than SFT). Moreover, SPT introduces limited or even no side effects on the general capability of LLMs. Our results shed light on how to precisely, effectively, and efficiently explain and improve the targeted ability of LLMs.