 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnhancing Target-unspecific Tasks through a Features Matrix
May 07, 2025Recent developments in prompt learning of large vision-language models have significantly improved performance in target-specific tasks. However, these prompt optimizing methods often struggle to tackle the target-unspecific or generalizable tasks effectively. It may be attributed to the fact that overfitting training causes the model to forget its general knowledge having strong promotion on target-unspecific tasks. To alleviate this issue, we propose a novel Features Matrix (FM) regularization approach designed to enhance these models on target-unspecific tasks. Our method extracts and leverages general knowledge, shaping a Features Matrix (FM). Specifically, the FM captures the semantics of diverse inputs from a deep and fine perspective, preserving essential general knowledge, which mitigates the risk of overfitting. Representative evaluations demonstrate that: 1) the FM is compatible with existing frameworks as a generic and flexible module, and 2) the FM significantly showcases its effectiveness in enhancing target-unspecific tasks, achieving state-of-the-art performance.
* ICML 2025
Generalizable Prompt Learning of CLIP: A Brief Overview
Mar 03, 2025
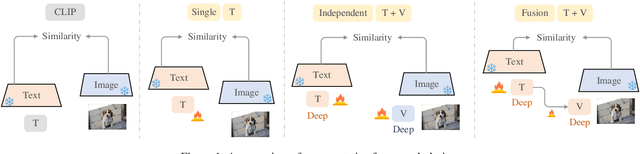

Existing vision-language models (VLMs) such as CLIP have showcased an impressive capability to generalize well across various downstream tasks. These models leverage the synergy between visual and textual information, enabling them to understand and reason about the content present in images and text in a unified manner. This article provides a brief overview of CLIP based on few-shot prompt learning, including experimental data and technical characteristics of some methods. The purpose of this review is to provide a reference for researchers who have just started their research in generalizable prompting of CLIP through few-shot training for classification across 15 datasets and also to facilitate the integration of this field by researchers in other downstream tasks.
A Similarity Paradigm Through Textual Regularization Without Forgetting
Feb 20, 2025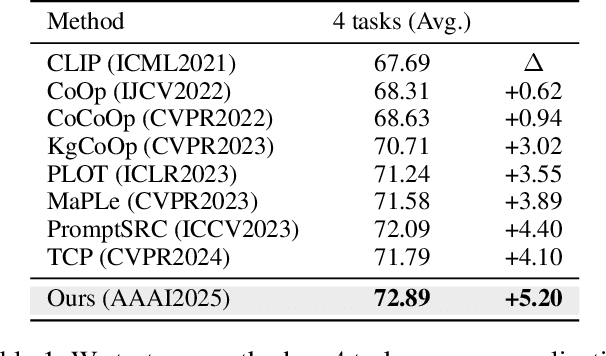
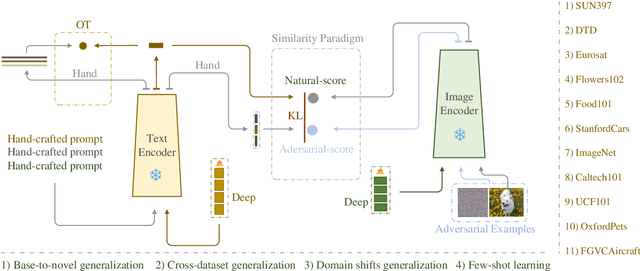
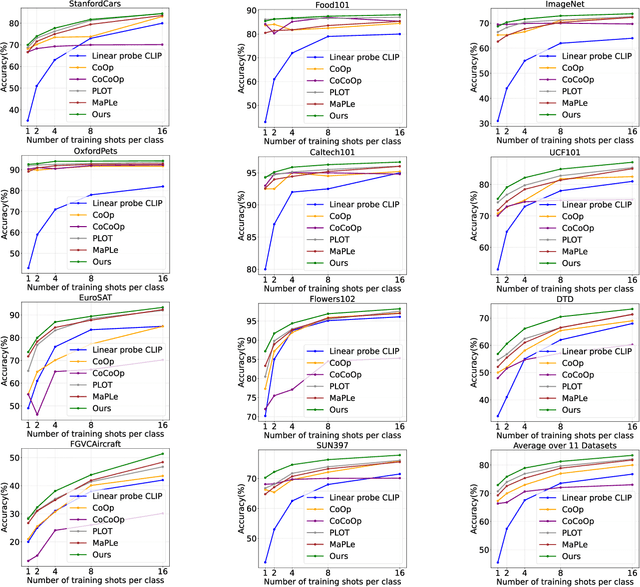
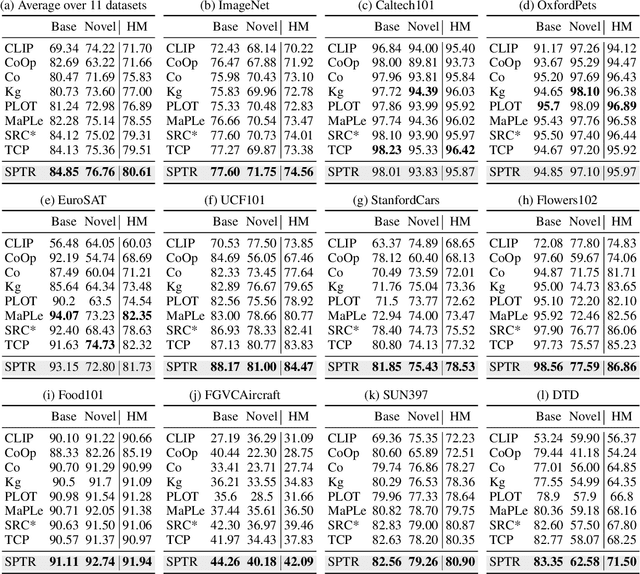
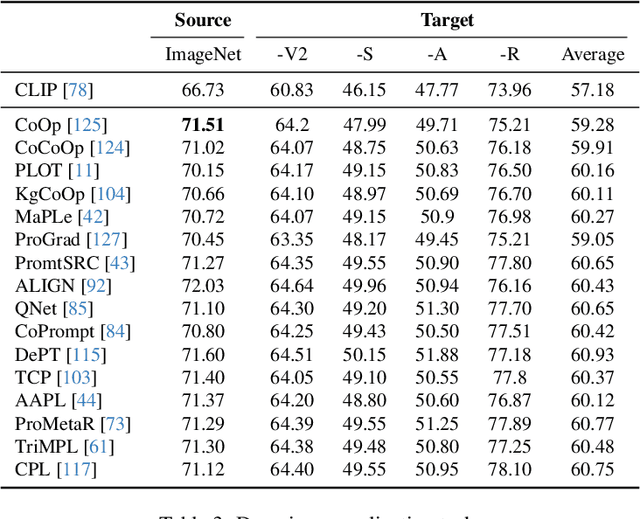
Prompt learning has emerged as a promising method for adapting pre-trained visual-language models (VLMs) to a range of downstream tasks. While optimizing the context can be effective for improving performance on specific tasks, it can often lead to poor generalization performance on unseen classes or datasets sampled from different distributions. It may be attributed to the fact that textual prompts tend to overfit downstream data distributions, leading to the forgetting of generalized knowledge derived from hand-crafted prompts. In this paper, we propose a novel method called Similarity Paradigm with Textual Regularization (SPTR) for prompt learning without forgetting. SPTR is a two-pronged design based on hand-crafted prompts that is an inseparable framework. 1) To avoid forgetting general textual knowledge, we introduce the optimal transport as a textual regularization to finely ensure approximation with hand-crafted features and tuning textual features. 2) In order to continuously unleash the general ability of multiple hand-crafted prompts, we propose a similarity paradigm for natural alignment score and adversarial alignment score to improve model robustness for generalization. Both modules share a common objective in addressing generalization issues, aiming to maximize the generalization capability derived from multiple hand-crafted prompts. Four representative tasks (i.e., non-generalization few-shot learning, base-to-novel generalization, cross-dataset generalization, domain generalization) across 11 datasets demonstrate that SPTR outperforms existing prompt learning methods.
Advancing Prompt Learning through an External Layer
Jul 29, 2024



Prompt learning represents a promising method for adapting pre-trained visual-language models (VLMs) to various downstream tasks by learning a set of text embeddings. One challenge inherent to these methods is the poor generalization performance due to the invalidity of the learned text embeddings for unseen tasks. A straightforward approach to bridge this gap is to freeze the text embeddings in prompts, which results in a lack of capacity to adapt VLMs for downstream tasks. To address this dilemma, we proposeto introduce an External Layer (EnLa) of text branch and learnable visual embeddings of the visual branch for adapting VLMs to downstream tasks. The learnable external layer is built upon valid embeddings of pre-trained CLIP. This design considers the balance of learning capabilities between the two branches. To align the textual and visual features, we propose a novel two-pronged approach: i) we introduce the optimal transport as the discrepancy metric to align the vision and text modalities, and ii) we introducea novel strengthening feature to enhance the interaction between these two modalities. Extensive experiments show that our method performs favorably well on 4 types of representative tasks across 11 datasets compared to the existing prompt learning methods.