 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGeneralizable Prompt Learning of CLIP: A Brief Overview
Paper and Code
Mar 03, 2025
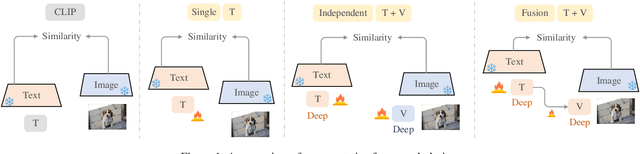

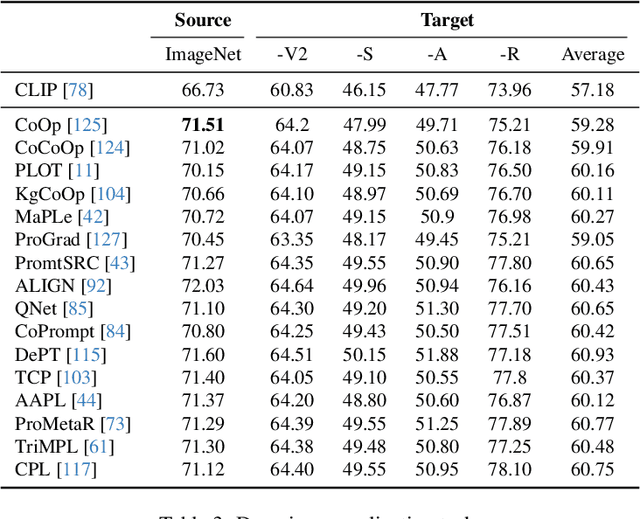
Existing vision-language models (VLMs) such as CLIP have showcased an impressive capability to generalize well across various downstream tasks. These models leverage the synergy between visual and textual information, enabling them to understand and reason about the content present in images and text in a unified manner. This article provides a brief overview of CLIP based on few-shot prompt learning, including experimental data and technical characteristics of some methods. The purpose of this review is to provide a reference for researchers who have just started their research in generalizable prompting of CLIP through few-shot training for classification across 15 datasets and also to facilitate the integration of this field by researchers in other downstream tasks.