 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGeneralizable Prompt Learning of CLIP: A Brief Overview
Mar 03, 2025

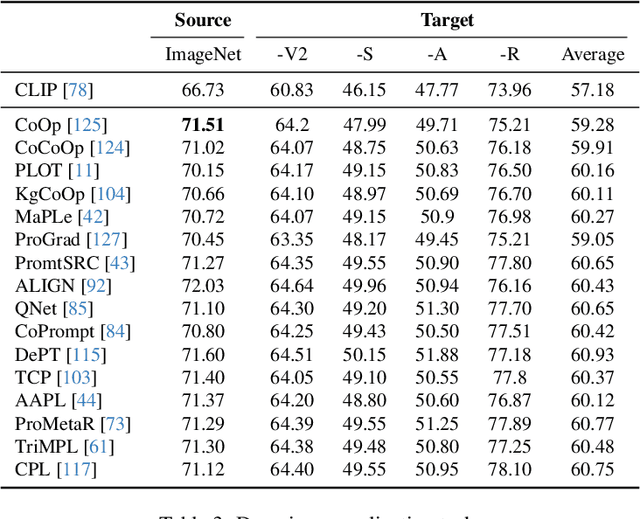
Existing vision-language models (VLMs) such as CLIP have showcased an impressive capability to generalize well across various downstream tasks. These models leverage the synergy between visual and textual information, enabling them to understand and reason about the content present in images and text in a unified manner. This article provides a brief overview of CLIP based on few-shot prompt learning, including experimental data and technical characteristics of some methods. The purpose of this review is to provide a reference for researchers who have just started their research in generalizable prompting of CLIP through few-shot training for classification across 15 datasets and also to facilitate the integration of this field by researchers in other downstream tasks.
Foodfusion: A Novel Approach for Food Image Composition via Diffusion Models
Aug 26, 2024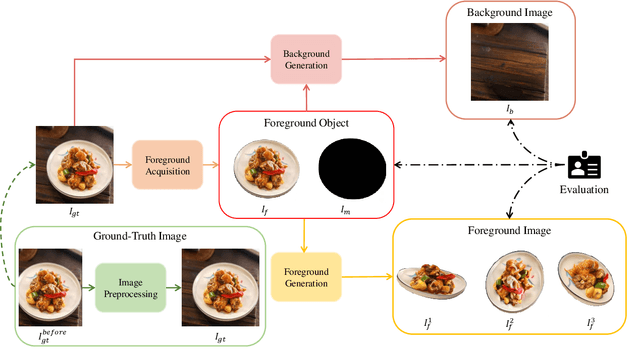
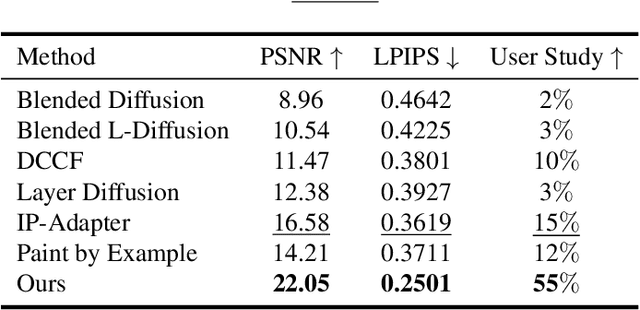

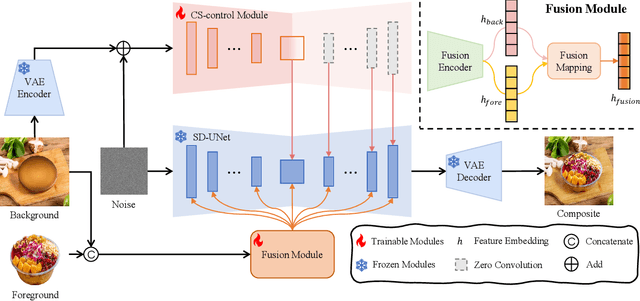
Food image composition requires the use of existing dish images and background images to synthesize a natural new image, while diffusion models have made significant advancements in image generation, enabling the construction of end-to-end architectures that yield promising results. However, existing diffusion models face challenges in processing and fusing information from multiple images and lack access to high-quality publicly available datasets, which prevents the application of diffusion models in food image composition. In this paper, we introduce a large-scale, high-quality food image composite dataset, FC22k, which comprises 22,000 foreground, background, and ground truth ternary image pairs. Additionally, we propose a novel food image composition method, Foodfusion, which leverages the capabilities of the pre-trained diffusion models and incorporates a Fusion Module for processing and integrating foreground and background information. This fused information aligns the foreground features with the background structure by merging the global structural information at the cross-attention layer of the denoising UNet. To further enhance the content and structure of the background, we also integrate a Content-Structure Control Module. Extensive experiments demonstrate the effectiveness and scalability of our proposed method.