 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAutomated Conjecture Resolution with Formal Verification
Apr 04, 2026Recent advances in large language models have significantly improved their ability to perform mathematical reasoning, extending from elementary problem solving to increasingly capable performance on research-level problems. However, reliably solving and verifying such problems remains challenging due to the inherent ambiguity of natural language reasoning. In this paper, we propose an automated framework for tackling research-level mathematical problems that integrates natural language reasoning with formal verification, enabling end-to-end problem solving with minimal human intervention. Our framework consists of two components: an informal reasoning agent, Rethlas, and a formal verification agent, Archon. Rethlas mimics the workflow of human mathematicians by combining reasoning primitives with our theorem search engine, Matlas, to explore solution strategies and construct candidate proofs. Archon, equipped with our formal theorem search engine LeanSearch, translates informal arguments into formalized Lean 4 projects through structured task decomposition, iterative refinement, and automated proof synthesis, ensuring machine-checkable correctness. Using this framework, we automatically resolve an open problem in commutative algebra and formally verify the resulting proof in Lean 4 with essentially no human involvement. Our experiments demonstrate that strong theorem retrieval tools enable the discovery and application of cross-domain mathematical techniques, while the formal agent is capable of autonomously filling nontrivial gaps in informal arguments. More broadly, our work illustrates a promising paradigm for mathematical research in which informal and formal reasoning systems, equipped with theorem retrieval tools, operate in tandem to produce verifiable results, substantially reduce human effort, and offer a concrete instantiation of human-AI collaborative mathematical research.
GenDet: Painting Colored Bounding Boxes on Images via Diffusion Model for Object Detection
Jan 12, 2026This paper presents GenDet, a novel framework that redefines object detection as an image generation task. In contrast to traditional approaches, GenDet adopts a pioneering approach by leveraging generative modeling: it conditions on the input image and directly generates bounding boxes with semantic annotations in the original image space. GenDet establishes a conditional generation architecture built upon the large-scale pre-trained Stable Diffusion model, formulating the detection task as semantic constraints within the latent space. It enables precise control over bounding box positions and category attributes, while preserving the flexibility of the generative model. This novel methodology effectively bridges the gap between generative models and discriminative tasks, providing a fresh perspective for constructing unified visual understanding systems. Systematic experiments demonstrate that GenDet achieves competitive accuracy compared to discriminative detectors, while retaining the flexibility characteristic of generative methods.
A Vision-Language-Action Model with Visual Prompt for OFF-Road Autonomous Driving
Jan 07, 2026Efficient trajectory planning in off-road terrains presents a formidable challenge for autonomous vehicles, often necessitating complex multi-step pipelines. However, traditional approaches exhibit limited adaptability in dynamic environments. To address these limitations, this paper proposes OFF-EMMA, a novel end-to-end multimodal framework designed to overcome the deficiencies of insufficient spatial perception and unstable reasoning in visual-language-action (VLA) models for off-road autonomous driving scenarios. The framework explicitly annotates input images through the design of a visual prompt block and introduces a chain-of-thought with self-consistency (COT-SC) reasoning strategy to enhance the accuracy and robustness of trajectory planning. The visual prompt block utilizes semantic segmentation masks as visual prompts, enhancing the spatial understanding ability of pre-trained visual-language models for complex terrains. The COT- SC strategy effectively mitigates the error impact of outliers on planning performance through a multi-path reasoning mechanism. Experimental results on the RELLIS-3D off-road dataset demonstrate that OFF-EMMA significantly outperforms existing methods, reducing the average L2 error of the Qwen backbone model by 13.3% and decreasing the failure rate from 16.52% to 6.56%.
Balanced Hierarchical Contrastive Learning with Decoupled Queries for Fine-grained Object Detection in Remote Sensing Images
Dec 30, 2025Fine-grained remote sensing datasets often use hierarchical label structures to differentiate objects in a coarse-to-fine manner, with each object annotated across multiple levels. However, embedding this semantic hierarchy into the representation learning space to improve fine-grained detection performance remains challenging. Previous studies have applied supervised contrastive learning at different hierarchical levels to group objects under the same parent class while distinguishing sibling subcategories. Nevertheless, they overlook two critical issues: (1) imbalanced data distribution across the label hierarchy causes high-frequency classes to dominate the learning process, and (2) learning semantic relationships among categories interferes with class-agnostic localization. To address these issues, we propose a balanced hierarchical contrastive loss combined with a decoupled learning strategy within the detection transformer (DETR) framework. The proposed loss introduces learnable class prototypes and equilibrates gradients contributed by different classes at each hierarchical level, ensuring that each hierarchical class contributes equally to the loss computation in every mini-batch. The decoupled strategy separates DETR's object queries into classification and localization sets, enabling task-specific feature extraction and optimization. Experiments on three fine-grained datasets with hierarchical annotations demonstrate that our method outperforms state-of-the-art approaches.
Generalizable Prompt Learning of CLIP: A Brief Overview
Mar 03, 2025
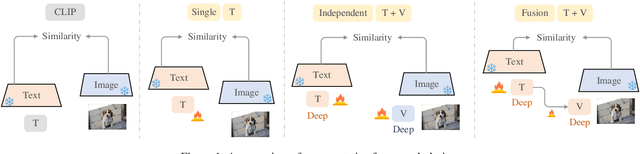

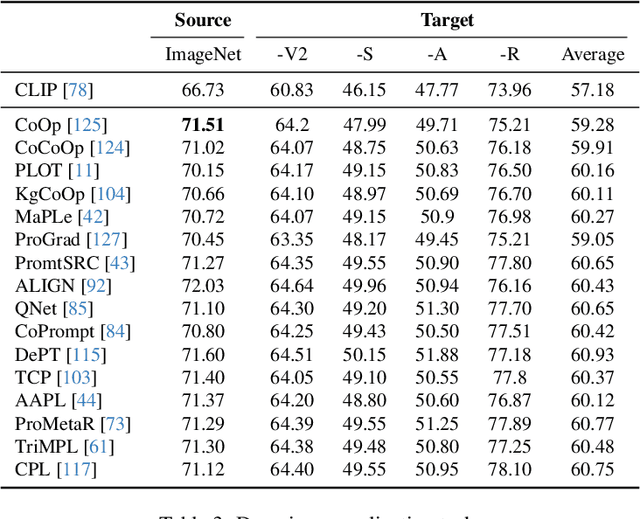
Existing vision-language models (VLMs) such as CLIP have showcased an impressive capability to generalize well across various downstream tasks. These models leverage the synergy between visual and textual information, enabling them to understand and reason about the content present in images and text in a unified manner. This article provides a brief overview of CLIP based on few-shot prompt learning, including experimental data and technical characteristics of some methods. The purpose of this review is to provide a reference for researchers who have just started their research in generalizable prompting of CLIP through few-shot training for classification across 15 datasets and also to facilitate the integration of this field by researchers in other downstream tasks.
Retrieval-Augmented Generation by Evidence Retroactivity in LLMs
Jan 07, 2025Retrieval-augmented generation has gained significant attention due to its ability to integrate relevant external knowledge, enhancing the accuracy and reliability of the LLMs' responses. Most of the existing methods apply a dynamic multiple retrieval-generating process, to address multi-hop complex questions by decomposing them into sub-problems. However, these methods rely on an unidirectional forward reasoning paradigm, where errors from insufficient reasoning steps or inherent flaws in current retrieval systems are irreversible, potentially derailing the entire reasoning chain. For the first time, this work introduces Retroactive Retrieval-Augmented Generation (RetroRAG), a novel framework to build a retroactive reasoning paradigm. RetroRAG revises and updates the evidence, redirecting the reasoning chain to the correct direction. RetroRAG constructs an evidence-collation-discovery framework to search, generate, and refine credible evidence. It synthesizes inferential evidence related to the key entities in the question from the existing source knowledge and formulates search queries to uncover additional information. As new evidence is found, RetroRAG continually updates and organizes this information, enhancing its ability to locate further necessary evidence. Paired with an Answerer to generate and evaluate outputs, RetroRAG is capable of refining its reasoning process iteratively until a reliable answer is obtained. Empirical evaluations show that RetroRAG significantly outperforms existing methods.
URoadNet: Dual Sparse Attentive U-Net for Multiscale Road Network Extraction
Dec 23, 2024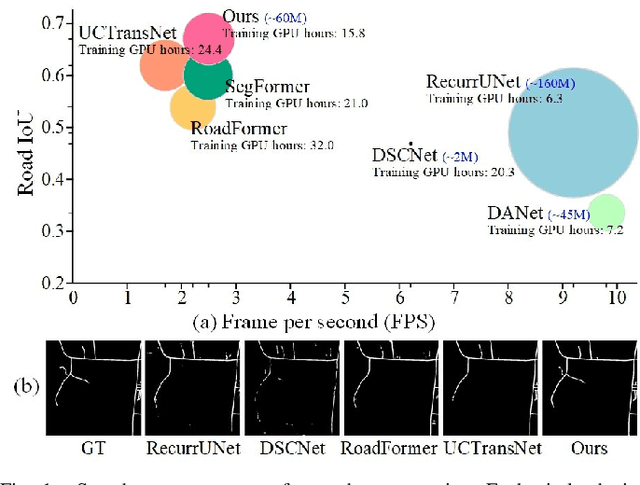
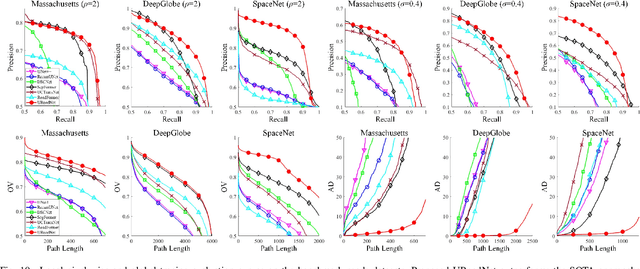
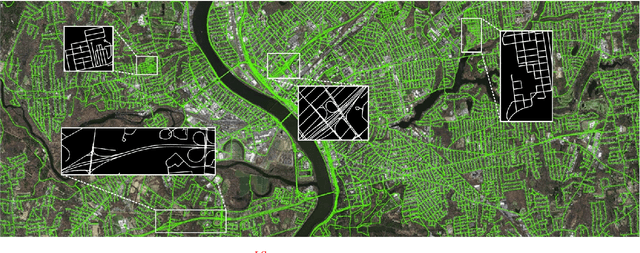
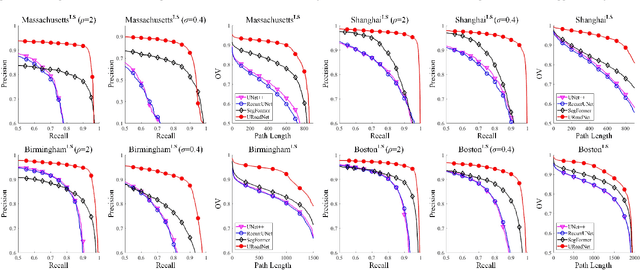
The challenges of road network segmentation demand an algorithm capable of adapting to the sparse and irregular shapes, as well as the diverse context, which often leads traditional encoding-decoding methods and simple Transformer embeddings to failure. We introduce a computationally efficient and powerful framework for elegant road-aware segmentation. Our method, called URoadNet, effectively encodes fine-grained local road connectivity and holistic global topological semantics while decoding multiscale road network information. URoadNet offers a novel alternative to the U-Net architecture by integrating connectivity attention, which can exploit intra-road interactions across multi-level sampling features with reduced computational complexity. This local interaction serves as valuable prior information for learning global interactions between road networks and the background through another integrality attention mechanism. The two forms of sparse attention are arranged alternatively and complementarily, and trained jointly, resulting in performance improvements without significant increases in computational complexity. Extensive experiments on various datasets with different resolutions, including Massachusetts, DeepGlobe, SpaceNet, and Large-Scale remote sensing images, demonstrate that URoadNet outperforms state-of-the-art techniques. Our approach represents a significant advancement in the field of road network extraction, providing a computationally feasible solution that achieves high-quality segmentation results.
An End-to-End Robust Point Cloud Semantic Segmentation Network with Single-Step Conditional Diffusion Models
Nov 25, 2024



Existing conditional Denoising Diffusion Probabilistic Models (DDPMs) with a Noise-Conditional Framework (NCF) remain challenging for 3D scene understanding tasks, as the complex geometric details in scenes increase the difficulty of fitting the gradients of the data distribution (the scores) from semantic labels. This also results in longer training and inference time for DDPMs compared to non-DDPMs. From a different perspective, we delve deeply into the model paradigm dominated by the Conditional Network. In this paper, we propose an end-to-end robust semantic \textbf{Seg}mentation \textbf{Net}work based on a \textbf{C}onditional-Noise Framework (CNF) of D\textbf{D}PMs, named \textbf{CDSegNet}. Specifically, CDSegNet models the Noise Network (NN) as a learnable noise-feature generator. This enables the Conditional Network (CN) to understand 3D scene semantics under multi-level feature perturbations, enhancing the generalization in unseen scenes. Meanwhile, benefiting from the noise system of DDPMs, CDSegNet exhibits strong noise and sparsity robustness in experiments. Moreover, thanks to CNF, CDSegNet can generate the semantic labels in a single-step inference like non-DDPMs, due to avoiding directly fitting the scores from semantic labels in the dominant network of CDSegNet. On public indoor and outdoor benchmarks, CDSegNet significantly outperforms existing methods, achieving state-of-the-art performance.
Autonomous Driving in Unstructured Environments: How Far Have We Come?
Oct 10, 2024

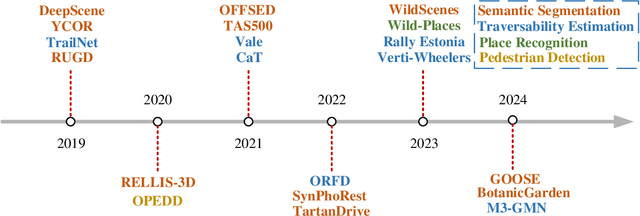

Research on autonomous driving in unstructured outdoor environments is less advanced than in structured urban settings due to challenges like environmental diversities and scene complexity. These environments-such as rural areas and rugged terrains-pose unique obstacles that are not common in structured urban areas. Despite these difficulties, autonomous driving in unstructured outdoor environments is crucial for applications in agriculture, mining, and military operations. Our survey reviews over 250 papers for autonomous driving in unstructured outdoor environments, covering offline mapping, pose estimation, environmental perception, path planning, end-to-end autonomous driving, datasets, and relevant challenges. We also discuss emerging trends and future research directions. This review aims to consolidate knowledge and encourage further research for autonomous driving in unstructured environments. To support ongoing work, we maintain an active repository with up-to-date literature and open-source projects at: https://github.com/chaytonmin/Survey-Autonomous-Driving-in-Unstructured-Environments.
TSBP: Improving Object Detection in Histology Images via Test-time Self-guided Bounding-box Propagation
Sep 25, 2024



A global threshold (e.g., 0.5) is often applied to determine which bounding boxes should be included in the final results for an object detection task. A higher threshold reduces false positives but may result in missing a significant portion of true positives. A lower threshold can increase detection recall but may also result in more false positives. Because of this, using a preset global threshold (e.g., 0.5) applied to all the bounding box candidates may lead to suboptimal solutions. In this paper, we propose a Test-time Self-guided Bounding-box Propagation (TSBP) method, leveraging Earth Mover's Distance (EMD) to enhance object detection in histology images. TSBP utilizes bounding boxes with high confidence to influence those with low confidence, leveraging visual similarities between them. This propagation mechanism enables bounding boxes to be selected in a controllable, explainable, and robust manner, which surpasses the effectiveness of using simple thresholds and uncertainty calibration methods. Importantly, TSBP does not necessitate additional labeled samples for model training or parameter estimation, unlike calibration methods. We conduct experiments on gland detection and cell detection tasks in histology images. The results show that our proposed TSBP significantly improves detection outcomes when working in conjunction with state-of-the-art deep learning-based detection networks. Compared to other methods such as uncertainty calibration, TSBP yields more robust and accurate object detection predictions while using no additional labeled samples. The code is available at https://github.com/jwhgdeu/TSBP.