 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUHD Image Deblurring via Autoregressive Flow with Ill-conditioned Constraints
Mar 11, 2026Ultra-high-definition (UHD) image deblurring poses significant challenges for UHD restoration methods, which must balance fine-grained detail recovery and practical inference efficiency. Although prominent discriminative and generative methods have achieved remarkable results, a trade-off persists between computational cost and the ability to generate fine-grained detail for UHD image deblurring tasks. To further alleviate these issues, we propose a novel autoregressive flow method for UHD image deblurring with an ill-conditioned constraint. Our core idea is to decompose UHD restoration into a progressive, coarse-to-fine process: at each scale, the sharp estimate is formed by upsampling the previous-scale result and adding a current-scale residual, enabling stable, stage-wise refinement from low to high resolution. We further introduce Flow Matching to model residual generation as a conditional vector field and perform few-step ODE sampling with efficient Euler/Heun solvers, enriching details while keeping inference affordable. Since multi-step generation at UHD can be numerically unstable, we propose an ill-conditioning suppression scheme by imposing condition-number regularization on a feature-induced attention matrix, improving convergence and cross-scale consistency. Our method demonstrates promising performance on blurred images at 4K (3840$\times$2160) or higher resolutions.
GenDet: Painting Colored Bounding Boxes on Images via Diffusion Model for Object Detection
Jan 12, 2026This paper presents GenDet, a novel framework that redefines object detection as an image generation task. In contrast to traditional approaches, GenDet adopts a pioneering approach by leveraging generative modeling: it conditions on the input image and directly generates bounding boxes with semantic annotations in the original image space. GenDet establishes a conditional generation architecture built upon the large-scale pre-trained Stable Diffusion model, formulating the detection task as semantic constraints within the latent space. It enables precise control over bounding box positions and category attributes, while preserving the flexibility of the generative model. This novel methodology effectively bridges the gap between generative models and discriminative tasks, providing a fresh perspective for constructing unified visual understanding systems. Systematic experiments demonstrate that GenDet achieves competitive accuracy compared to discriminative detectors, while retaining the flexibility characteristic of generative methods.
Autonomous Driving in Unstructured Environments: How Far Have We Come?
Oct 10, 2024

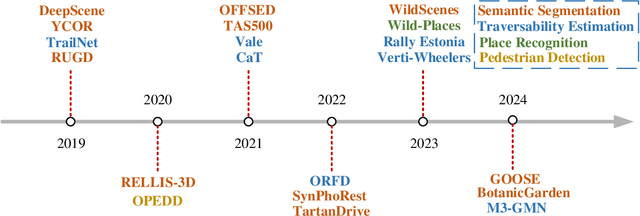

Research on autonomous driving in unstructured outdoor environments is less advanced than in structured urban settings due to challenges like environmental diversities and scene complexity. These environments-such as rural areas and rugged terrains-pose unique obstacles that are not common in structured urban areas. Despite these difficulties, autonomous driving in unstructured outdoor environments is crucial for applications in agriculture, mining, and military operations. Our survey reviews over 250 papers for autonomous driving in unstructured outdoor environments, covering offline mapping, pose estimation, environmental perception, path planning, end-to-end autonomous driving, datasets, and relevant challenges. We also discuss emerging trends and future research directions. This review aims to consolidate knowledge and encourage further research for autonomous driving in unstructured environments. To support ongoing work, we maintain an active repository with up-to-date literature and open-source projects at: https://github.com/chaytonmin/Survey-Autonomous-Driving-in-Unstructured-Environments.
DriveWorld: 4D Pre-trained Scene Understanding via World Models for Autonomous Driving
May 07, 2024Vision-centric autonomous driving has recently raised wide attention due to its lower cost. Pre-training is essential for extracting a universal representation. However, current vision-centric pre-training typically relies on either 2D or 3D pre-text tasks, overlooking the temporal characteristics of autonomous driving as a 4D scene understanding task. In this paper, we address this challenge by introducing a world model-based autonomous driving 4D representation learning framework, dubbed \emph{DriveWorld}, which is capable of pre-training from multi-camera driving videos in a spatio-temporal fashion. Specifically, we propose a Memory State-Space Model for spatio-temporal modelling, which consists of a Dynamic Memory Bank module for learning temporal-aware latent dynamics to predict future changes and a Static Scene Propagation module for learning spatial-aware latent statics to offer comprehensive scene contexts. We additionally introduce a Task Prompt to decouple task-aware features for various downstream tasks. The experiments demonstrate that DriveWorld delivers promising results on various autonomous driving tasks. When pre-trained with the OpenScene dataset, DriveWorld achieves a 7.5% increase in mAP for 3D object detection, a 3.0% increase in IoU for online mapping, a 5.0% increase in AMOTA for multi-object tracking, a 0.1m decrease in minADE for motion forecasting, a 3.0% increase in IoU for occupancy prediction, and a 0.34m reduction in average L2 error for planning.
Is Sora a World Simulator? A Comprehensive Survey on General World Models and Beyond
May 06, 2024General world models represent a crucial pathway toward achieving Artificial General Intelligence (AGI), serving as the cornerstone for various applications ranging from virtual environments to decision-making systems. Recently, the emergence of the Sora model has attained significant attention due to its remarkable simulation capabilities, which exhibits an incipient comprehension of physical laws. In this survey, we embark on a comprehensive exploration of the latest advancements in world models. Our analysis navigates through the forefront of generative methodologies in video generation, where world models stand as pivotal constructs facilitating the synthesis of highly realistic visual content. Additionally, we scrutinize the burgeoning field of autonomous-driving world models, meticulously delineating their indispensable role in reshaping transportation and urban mobility. Furthermore, we delve into the intricacies inherent in world models deployed within autonomous agents, shedding light on their profound significance in enabling intelligent interactions within dynamic environmental contexts. At last, we examine challenges and limitations of world models, and discuss their potential future directions. We hope this survey can serve as a foundational reference for the research community and inspire continued innovation. This survey will be regularly updated at: https://github.com/GigaAI-research/General-World-Models-Survey.
UniWorld: Autonomous Driving Pre-training via World Models
Aug 14, 2023In this paper, we draw inspiration from Alberto Elfes' pioneering work in 1989, where he introduced the concept of the occupancy grid as World Models for robots. We imbue the robot with a spatial-temporal world model, termed UniWorld, to perceive its surroundings and predict the future behavior of other participants. UniWorld involves initially predicting 4D geometric occupancy as the World Models for foundational stage and subsequently fine-tuning on downstream tasks. UniWorld can estimate missing information concerning the world state and predict plausible future states of the world. Besides, UniWorld's pre-training process is label-free, enabling the utilization of massive amounts of image-LiDAR pairs to build a Foundational Model.The proposed unified pre-training framework demonstrates promising results in key tasks such as motion prediction, multi-camera 3D object detection, and surrounding semantic scene completion. When compared to monocular pre-training methods on the nuScenes dataset, UniWorld shows a significant improvement of about 1.5% in IoU for motion prediction, 2.0% in mAP and 2.0% in NDS for multi-camera 3D object detection, as well as a 3% increase in mIoU for surrounding semantic scene completion. By adopting our unified pre-training method, a 25% reduction in 3D training annotation costs can be achieved, offering significant practical value for the implementation of real-world autonomous driving. Codes are publicly available at https://github.com/chaytonmin/UniWorld.
Traversability Analysis for Autonomous Driving in Complex Environment: A LiDAR-based Terrain Modeling Approach
Jul 05, 2023For autonomous driving, traversability analysis is one of the most basic and essential tasks. In this paper, we propose a novel LiDAR-based terrain modeling approach, which could output stable, complete and accurate terrain models and traversability analysis results. As terrain is an inherent property of the environment that does not change with different view angles, our approach adopts a multi-frame information fusion strategy for terrain modeling. Specifically, a normal distributions transform mapping approach is adopted to accurately model the terrain by fusing information from consecutive LiDAR frames. Then the spatial-temporal Bayesian generalized kernel inference and bilateral filtering are utilized to promote the stability and completeness of the results while simultaneously retaining the sharp terrain edges. Based on the terrain modeling results, the traversability of each region is obtained by performing geometric connectivity analysis between neighboring terrain regions. Experimental results show that the proposed method could run in real-time and outperforms state-of-the-art approaches.
* accepted to Journal of Field Robotics
Occ-BEV: Multi-Camera Unified Pre-training via 3D Scene Reconstruction
Jun 07, 2023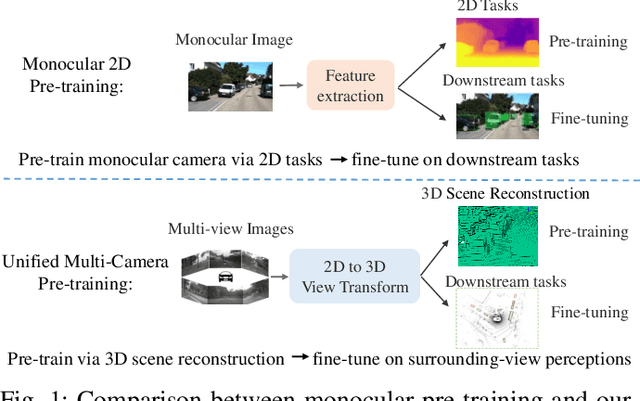



Multi-camera 3D perception has emerged as a prominent research field in autonomous driving, offering a viable and cost-effective alternative to LiDAR-based solutions. However, existing multi-camera algorithms primarily rely on monocular image pre-training, which overlooks the spatial and temporal correlations among different camera views. To address this limitation, we propose the first multi-camera unified pre-training framework called Occ-BEV, which involves initially reconstructing the 3D scene as the foundational stage and subsequently fine-tuning the model on downstream tasks. Specifically, a 3D decoder is designed for leveraging Bird's Eye View (BEV) features from multi-view images to predict the 3D geometric occupancy to enable the model to capture a more comprehensive understanding of the 3D environment. A significant benefit of Occ-BEV is its capability of utilizing a considerable volume of unlabeled image-LiDAR pairs for pre-training purposes. The proposed multi-camera unified pre-training framework demonstrates promising results in key tasks such as multi-camera 3D object detection and surrounding semantic scene completion. When compared to monocular pre-training methods on the nuScenes dataset, Occ-BEV shows a significant improvement of about 2.0% in mAP and 2.0% in NDS for multi-camera 3D object detection, as well as a 3% increase in mIoU for surrounding semantic scene completion. Codes are publicly available at https://github.com/chaytonmin/Occ-BEV.
Adversarial and Random Transformations for Robust Domain Adaptation and Generalization
Nov 13, 2022Data augmentation has been widely used to improve generalization in training deep neural networks. Recent works show that using worst-case transformations or adversarial augmentation strategies can significantly improve the accuracy and robustness. However, due to the non-differentiable properties of image transformations, searching algorithms such as reinforcement learning or evolution strategy have to be applied, which are not computationally practical for large scale problems. In this work, we show that by simply applying consistency training with random data augmentation, state-of-the-art results on domain adaptation (DA) and generalization (DG) can be obtained. To further improve the accuracy and robustness with adversarial examples, we propose a differentiable adversarial data augmentation method based on spatial transformer networks (STN). The combined adversarial and random transformations based method outperforms the state-of-the-art on multiple DA and DG benchmark datasets. Besides, the proposed method shows desirable robustness to corruption, which is also validated on commonly used datasets.
Voxel-MAE: Masked Autoencoders for Pre-training Large-scale Point Clouds
Jun 27, 2022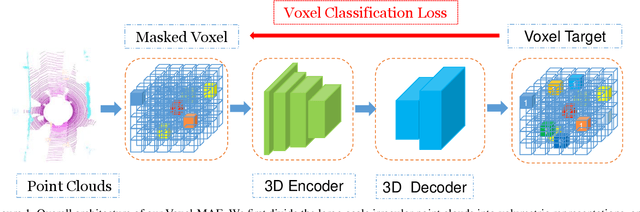
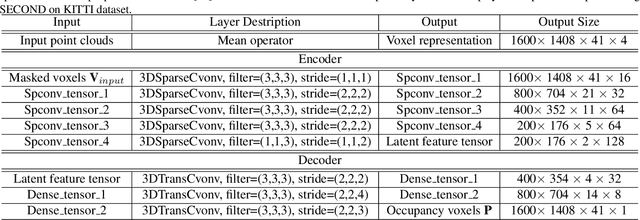
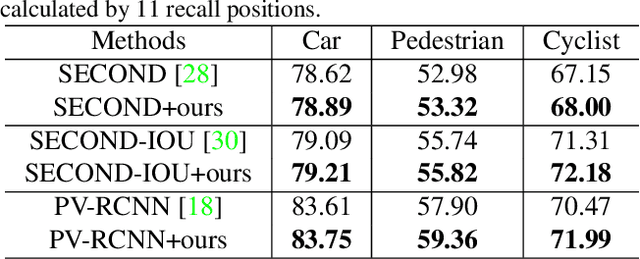
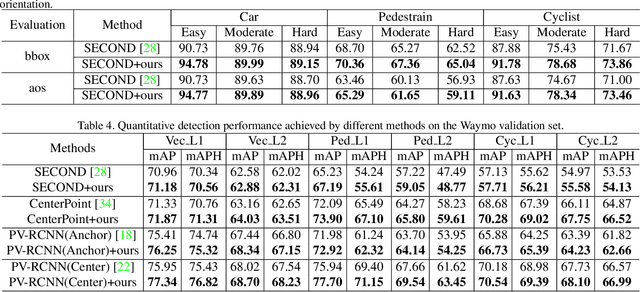
Mask-based pre-training has achieved great success for self-supervised learning in image, video, and language, without manually annotated supervision. However, it has not yet been studied about large-scale point clouds with redundant spatial information in autonomous driving. As the number of large-scale point clouds is huge, it is impossible to reconstruct the input point clouds. In this paper, we propose a mask voxel classification network for large-scale point clouds pre-training. Our key idea is to divide the point clouds into voxel representations and classify whether the voxel contains point clouds. This simple strategy makes the network to be voxel-aware of the object shape, thus improving the performance of the downstream tasks, such as 3D object detection. Our Voxel-MAE with even a 90% masking ratio can still learn representative features for the high spatial redundancy of large-scale point clouds. We also validate the effectiveness of Voxel-MAE in unsupervised domain adaptative tasks, which proves the generalization ability of Voxel-MAE. Our Voxel-MAE proves that it is feasible to pre-train large-scale point clouds without data annotations to enhance the perception ability of the autonomous vehicle. Extensive experiments show great effectiveness of our pre-trained model with 3D object detectors (SECOND, CenterPoint, and PV-RCNN) on two popular datasets (KITTI, Waymo). Codes are publicly available at https://github.com/chaytonmin/Voxel-MAE.