 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOcc-BEV: Multi-Camera Unified Pre-training via 3D Scene Reconstruction
Jun 07, 2023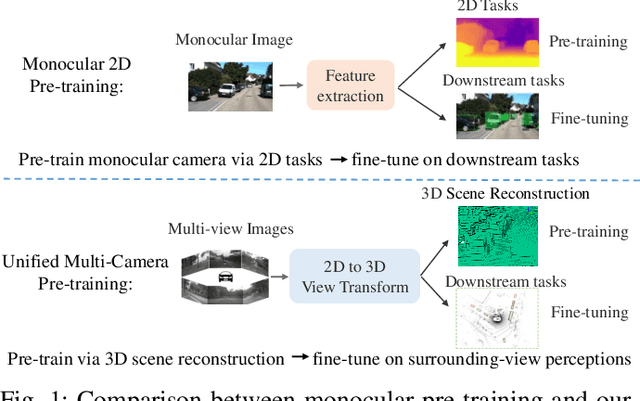



Multi-camera 3D perception has emerged as a prominent research field in autonomous driving, offering a viable and cost-effective alternative to LiDAR-based solutions. However, existing multi-camera algorithms primarily rely on monocular image pre-training, which overlooks the spatial and temporal correlations among different camera views. To address this limitation, we propose the first multi-camera unified pre-training framework called Occ-BEV, which involves initially reconstructing the 3D scene as the foundational stage and subsequently fine-tuning the model on downstream tasks. Specifically, a 3D decoder is designed for leveraging Bird's Eye View (BEV) features from multi-view images to predict the 3D geometric occupancy to enable the model to capture a more comprehensive understanding of the 3D environment. A significant benefit of Occ-BEV is its capability of utilizing a considerable volume of unlabeled image-LiDAR pairs for pre-training purposes. The proposed multi-camera unified pre-training framework demonstrates promising results in key tasks such as multi-camera 3D object detection and surrounding semantic scene completion. When compared to monocular pre-training methods on the nuScenes dataset, Occ-BEV shows a significant improvement of about 2.0% in mAP and 2.0% in NDS for multi-camera 3D object detection, as well as a 3% increase in mIoU for surrounding semantic scene completion. Codes are publicly available at https://github.com/chaytonmin/Occ-BEV.
Adversarial and Random Transformations for Robust Domain Adaptation and Generalization
Nov 13, 2022Data augmentation has been widely used to improve generalization in training deep neural networks. Recent works show that using worst-case transformations or adversarial augmentation strategies can significantly improve the accuracy and robustness. However, due to the non-differentiable properties of image transformations, searching algorithms such as reinforcement learning or evolution strategy have to be applied, which are not computationally practical for large scale problems. In this work, we show that by simply applying consistency training with random data augmentation, state-of-the-art results on domain adaptation (DA) and generalization (DG) can be obtained. To further improve the accuracy and robustness with adversarial examples, we propose a differentiable adversarial data augmentation method based on spatial transformer networks (STN). The combined adversarial and random transformations based method outperforms the state-of-the-art on multiple DA and DG benchmark datasets. Besides, the proposed method shows desirable robustness to corruption, which is also validated on commonly used datasets.
ORFD: A Dataset and Benchmark for Off-Road Freespace Detection
Jun 26, 2022



Freespace detection is an essential component of autonomous driving technology and plays an important role in trajectory planning. In the last decade, deep learning-based free space detection methods have been proved feasible. However, these efforts were focused on urban road environments and few deep learning-based methods were specifically designed for off-road free space detection due to the lack of off-road benchmarks. In this paper, we present the ORFD dataset, which, to our knowledge, is the first off-road free space detection dataset. The dataset was collected in different scenes (woodland, farmland, grassland, and countryside), different weather conditions (sunny, rainy, foggy, and snowy), and different light conditions (bright light, daylight, twilight, darkness), which totally contains 12,198 LiDAR point cloud and RGB image pairs with the traversable area, non-traversable area and unreachable area annotated in detail. We propose a novel network named OFF-Net, which unifies Transformer architecture to aggregate local and global information, to meet the requirement of large receptive fields for free space detection tasks. We also propose the cross-attention to dynamically fuse LiDAR and RGB image information for accurate off-road free space detection. Dataset and code are publicly available athttps://github.com/chaytonmin/OFF-Net.
Trajectory Prediction for Autonomous Driving with Topometric Map
May 09, 2021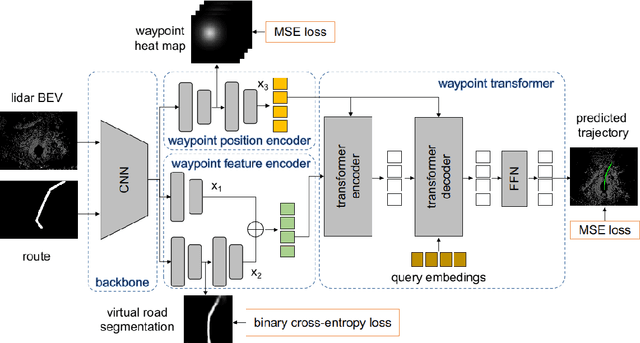
State-of-the-art autonomous driving systems rely on high definition (HD) maps for localization and navigation. However, building and maintaining HD maps is time-consuming and expensive. Furthermore, the HD maps assume structured environment such as the existence of major road and lanes, which are not present in rural areas. In this work, we propose an end-to-end transformer networks based approach for map-less autonomous driving. The proposed model takes raw LiDAR data and noisy topometric map as input and produces precise local trajectory for navigation. We demonstrate the effectiveness of our method in real-world driving data, including both urban and rural areas. The experimental results show that the proposed method outperforms state-of-the-art multimodal methods and is robust to the perturbations of the topometric map. The code of the proposed method is publicly available at \url{https://github.com/Jiaolong/trajectory-prediction}.
Attentional Graph Neural Network for Parking-slot Detection
Apr 06, 2021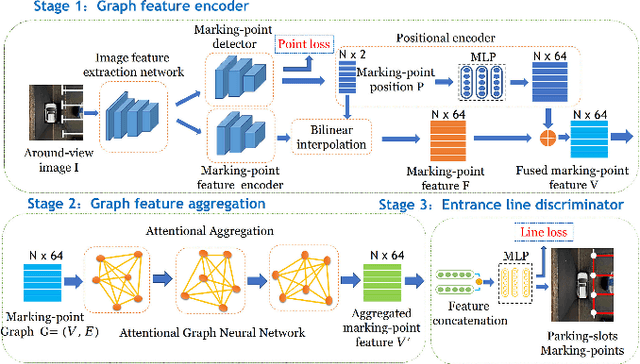
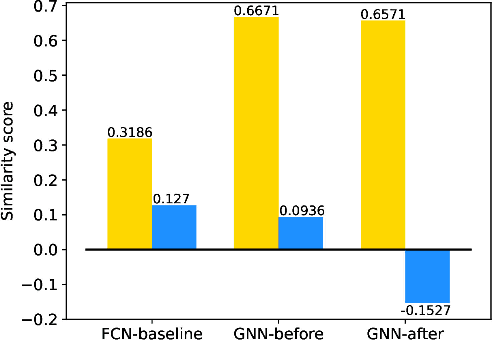

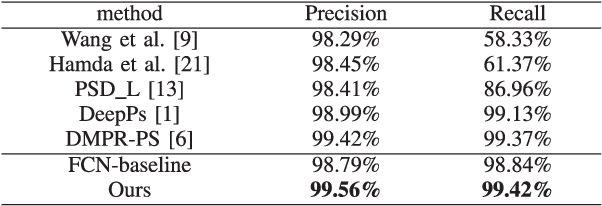
Deep learning has recently demonstrated its promising performance for vision-based parking-slot detection. However, very few existing methods explicitly take into account learning the link information of the marking-points, resulting in complex post-processing and erroneous detection. In this paper, we propose an attentional graph neural network based parking-slot detection method, which refers the marking-points in an around-view image as graph-structured data and utilize graph neural network to aggregate the neighboring information between marking-points. Without any manually designed post-processing, the proposed method is end-to-end trainable. Extensive experiments have been conducted on public benchmark dataset, where the proposed method achieves state-of-the-art accuracy. Code is publicly available at \url{https://github.com/Jiaolong/gcn-parking-slot}.
* Accepted by RAL
Self-supervised Domain Adaptation for Computer Vision Tasks
Jul 25, 2019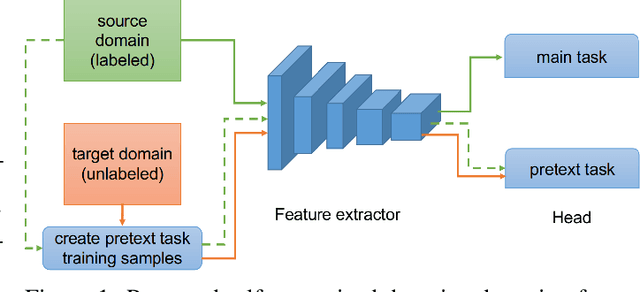
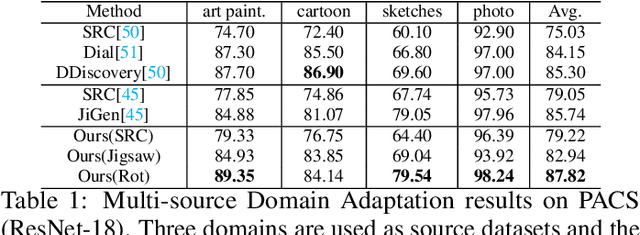

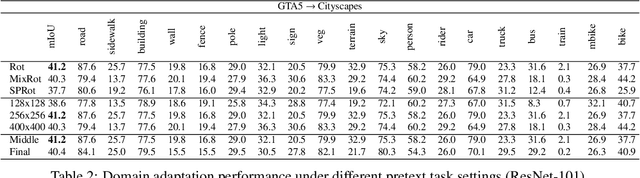
Recent progress of self-supervised visual representation learning has achieved remarkable success on many challenging computer vision benchmarks. However, whether these techniques can be used for domain adaptation has not been explored. In this work, we propose a generic method for self-supervised domain adaptation, using object recognition and semantic segmentation of urban scenes as use cases. Focusing on simple pretext/auxiliary tasks (e.g. image rotation prediction), we assess different learning strategies to improve domain adaptation effectiveness by self-supervision. Additionally, we propose two complementary strategies to further boost the domain adaptation accuracy within our method, consisting of prediction layer alignment and batch normalization calibration. For the experimental work, we focus on the relevant setting of training models using synthetic images, and adapting them to perform on real-world images. The obtained results show adaptation levels comparable to most studied domain adaptation methods, thus, bringing self-supervision as a new alternative for reaching domain adaptation. The code is available at https://github.com/Jiaolong/self-supervised-da.
Training a Binary Weight Object Detector by Knowledge Transfer for Autonomous Driving
Apr 17, 2018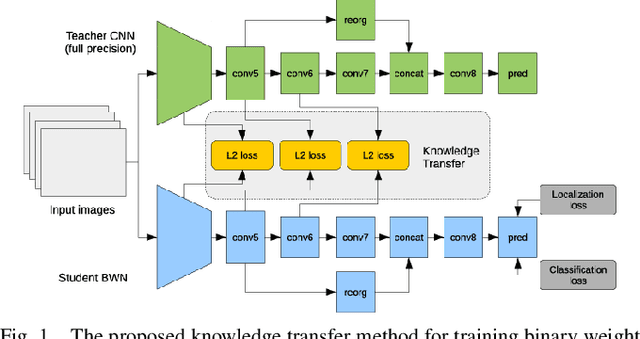
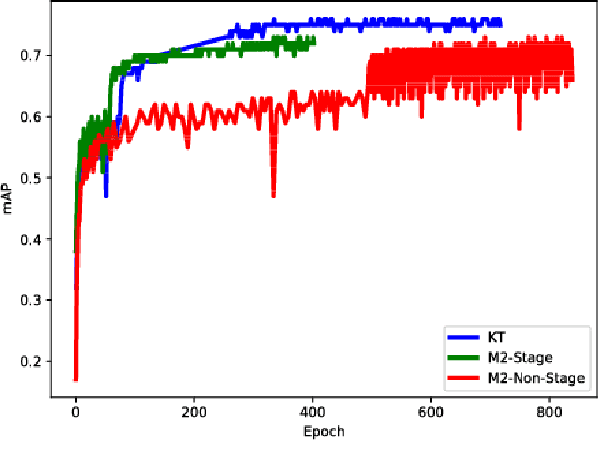

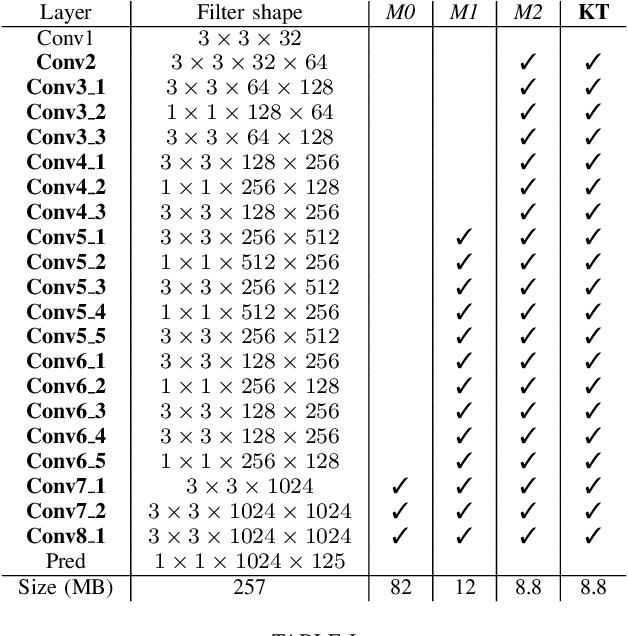
Autonomous driving has harsh requirements of small model size and energy efficiency, in order to enable the embedded system to achieve real-time on-board object detection. Recent deep convolutional neural network based object detectors have achieved state-of-the-art accuracy. However, such models are trained with numerous parameters and their high computational costs and large storage prohibit the deployment to memory and computation resource limited systems. Low-precision neural networks are popular techniques for reducing the computation requirements and memory footprint. Among them, binary weight neural network (BWN) is the extreme case which quantizes the float-point into just $1$ bit. BWNs are difficult to train and suffer from accuracy deprecation due to the extreme low-bit representation. To address this problem, we propose a knowledge transfer (KT) method to aid the training of BWN using a full-precision teacher network. We built DarkNet- and MobileNet-based binary weight YOLO-v2 detectors and conduct experiments on KITTI benchmark for car, pedestrian and cyclist detection. The experimental results show that the proposed method maintains high detection accuracy while reducing the model size of DarkNet-YOLO from 257 MB to 8.8 MB and MobileNet-YOLO from 193 MB to 7.9 MB.
Computer-aided diagnosis of lung carcinoma using deep learning - a pilot study
Mar 14, 2018
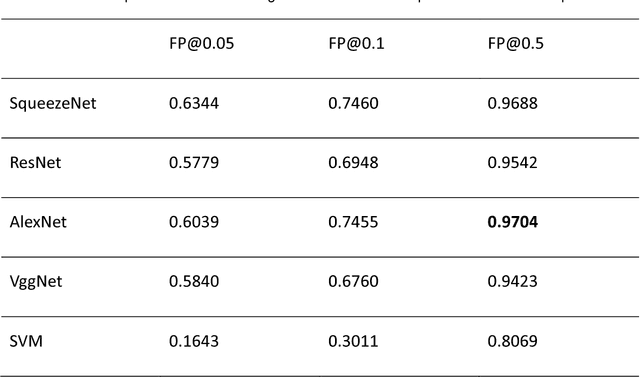
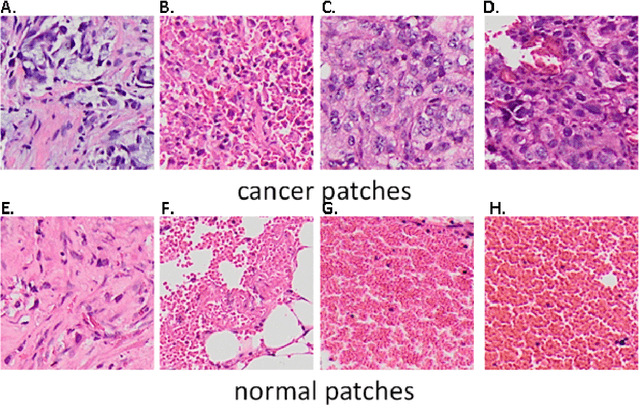
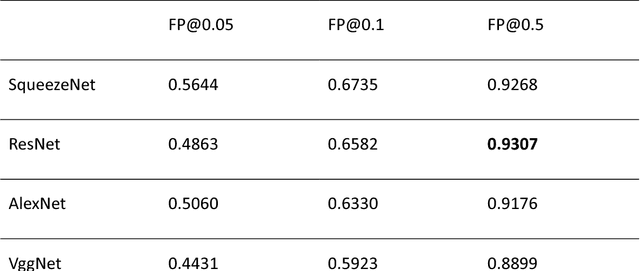
Aim: Early detection and correct diagnosis of lung cancer are the most important steps in improving patient outcome. This study aims to assess which deep learning models perform best in lung cancer diagnosis. Methods: Non-small cell lung carcinoma and small cell lung carcinoma biopsy specimens were consecutively obtained and stained. The specimen slides were diagnosed by two experienced pathologists (over 20 years). Several deep learning models were trained to discriminate cancer and non-cancer biopsies. Result: Deep learning models give reasonable AUC from 0.8810 to 0.9119. Conclusion: The deep learning analysis could help to speed up the detection process for the whole-slide image (WSI) and keep the comparable detection rate with human observer.
From Virtual to Real World Visual Perception using Domain Adaptation -- The DPM as Example
Dec 29, 2016
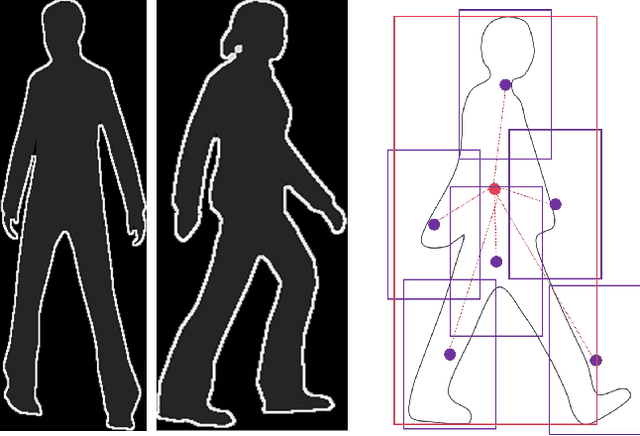

Supervised learning tends to produce more accurate classifiers than unsupervised learning in general. This implies that training data is preferred with annotations. When addressing visual perception challenges, such as localizing certain object classes within an image, the learning of the involved classifiers turns out to be a practical bottleneck. The reason is that, at least, we have to frame object examples with bounding boxes in thousands of images. A priori, the more complex the model is regarding its number of parameters, the more annotated examples are required. This annotation task is performed by human oracles, which ends up in inaccuracies and errors in the annotations (aka ground truth) since the task is inherently very cumbersome and sometimes ambiguous. As an alternative we have pioneered the use of virtual worlds for collecting such annotations automatically and with high precision. However, since the models learned with virtual data must operate in the real world, we still need to perform domain adaptation (DA). In this chapter we revisit the DA of a deformable part-based model (DPM) as an exemplifying case of virtual- to-real-world DA. As a use case, we address the challenge of vehicle detection for driver assistance, using different publicly available virtual-world data. While doing so, we investigate questions such as: how does the domain gap behave due to virtual-vs-real data with respect to dominant object appearance per domain, as well as the role of photo-realism in the virtual world.
Hierarchical Adaptive Structural SVM for Domain Adaptation
Aug 22, 2014

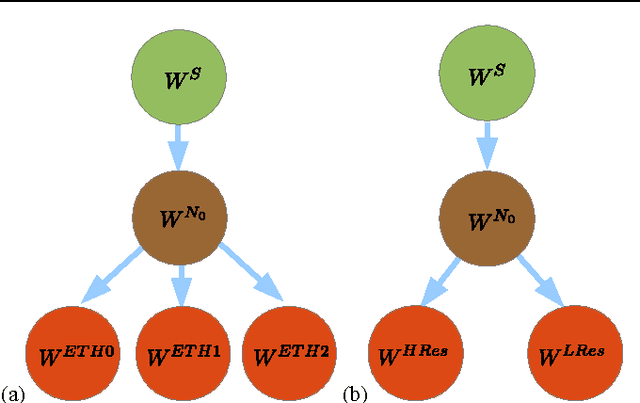
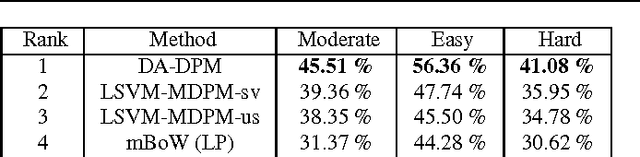
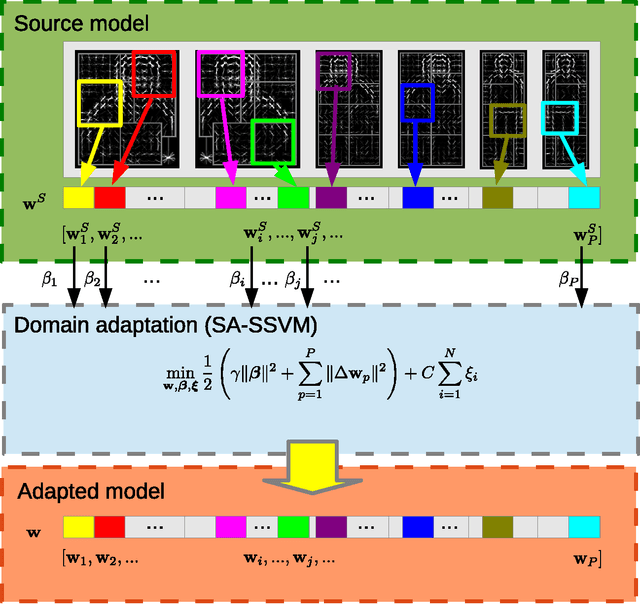
A key topic in classification is the accuracy loss produced when the data distribution in the training (source) domain differs from that in the testing (target) domain. This is being recognized as a very relevant problem for many computer vision tasks such as image classification, object detection, and object category recognition. In this paper, we present a novel domain adaptation method that leverages multiple target domains (or sub-domains) in a hierarchical adaptation tree. The core idea is to exploit the commonalities and differences of the jointly considered target domains. Given the relevance of structural SVM (SSVM) classifiers, we apply our idea to the adaptive SSVM (A-SSVM), which only requires the target domain samples together with the existing source-domain classifier for performing the desired adaptation. Altogether, we term our proposal as hierarchical A-SSVM (HA-SSVM). As proof of concept we use HA-SSVM for pedestrian detection and object category recognition. In the former we apply HA-SSVM to the deformable part-based model (DPM) while in the latter HA-SSVM is applied to multi-category classifiers. In both cases, we show how HA-SSVM is effective in increasing the detection/recognition accuracy with respect to adaptation strategies that ignore the structure of the target data. Since, the sub-domains of the target data are not always known a priori, we shown how HA-SSVM can incorporate sub-domain structure discovery for object category recognition.