 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGenerating Physically Realistic and Directable Human Motions from Multi-Modal Inputs
Feb 08, 2025This work focuses on generating realistic, physically-based human behaviors from multi-modal inputs, which may only partially specify the desired motion. For example, the input may come from a VR controller providing arm motion and body velocity, partial key-point animation, computer vision applied to videos, or even higher-level motion goals. This requires a versatile low-level humanoid controller that can handle such sparse, under-specified guidance, seamlessly switch between skills, and recover from failures. Current approaches for learning humanoid controllers from demonstration data capture some of these characteristics, but none achieve them all. To this end, we introduce the Masked Humanoid Controller (MHC), a novel approach that applies multi-objective imitation learning on augmented and selectively masked motion demonstrations. The training methodology results in an MHC that exhibits the key capabilities of catch-up to out-of-sync input commands, combining elements from multiple motion sequences, and completing unspecified parts of motions from sparse multimodal input. We demonstrate these key capabilities for an MHC learned over a dataset of 87 diverse skills and showcase different multi-modal use cases, including integration with planning frameworks to highlight MHC's ability to solve new user-defined tasks without any finetuning.
Objects With Lighting: A Real-World Dataset for Evaluating Reconstruction and Rendering for Object Relighting
Jan 17, 2024



Reconstructing an object from photos and placing it virtually in a new environment goes beyond the standard novel view synthesis task as the appearance of the object has to not only adapt to the novel viewpoint but also to the new lighting conditions and yet evaluations of inverse rendering methods rely on novel view synthesis data or simplistic synthetic datasets for quantitative analysis. This work presents a real-world dataset for measuring the reconstruction and rendering of objects for relighting. To this end, we capture the environment lighting and ground truth images of the same objects in multiple environments allowing to reconstruct the objects from images taken in one environment and quantify the quality of the rendered views for the unseen lighting environments. Further, we introduce a simple baseline composed of off-the-shelf methods and test several state-of-the-art methods on the relighting task and show that novel view synthesis is not a reliable proxy to measure performance. Code and dataset are available at https://github.com/isl-org/objects-with-lighting .
SPIGAN: Privileged Adversarial Learning from Simulation
Oct 09, 2018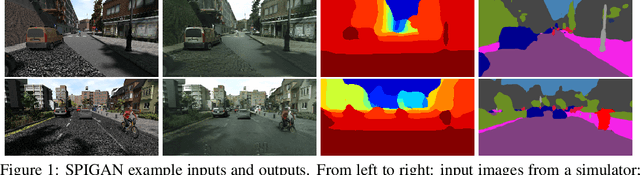
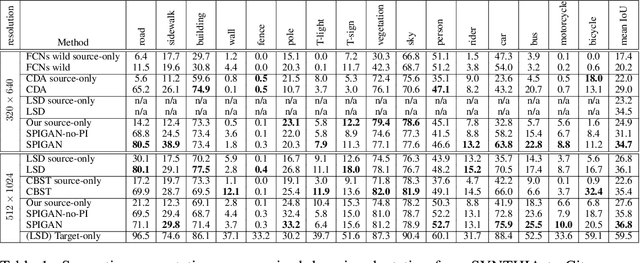
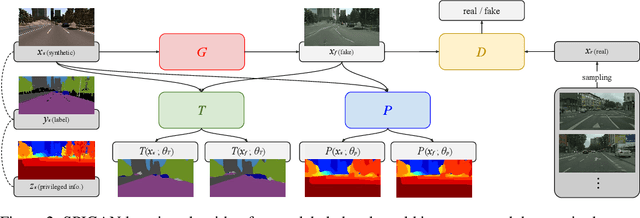
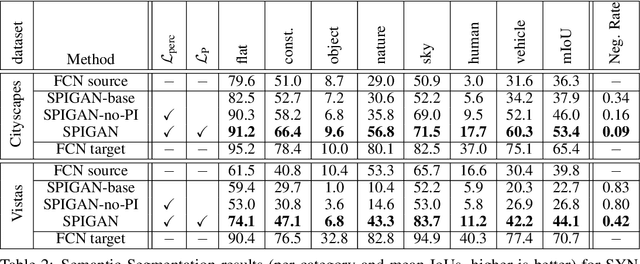
Deep Learning for Computer Vision depends mainly on the source of supervision.Photo-realistic simulators can generate large-scale automatically labeled syntheticdata, but introduce a domain gap negatively impacting performance. We propose anew unsupervised domain adaptation algorithm, called SPIGAN, relying on Sim-ulator Privileged Information (PI) and Generative Adversarial Networks (GAN).We use internal data from the simulator as PI during the training of a target tasknetwork. We experimentally evaluate our approach on semantic segmentation. Wetrain the networks on real-world Cityscapes and Vistas datasets, using only unla-beled real-world images and synthetic labeled data with z-buffer (depth) PI fromthe SYNTHIA dataset. Our method improves over no adaptation and state-of-the-art unsupervised domain adaptation techniques.
Physical Representation-based Predicate Optimization for a Visual Analytics Database
Sep 10, 2018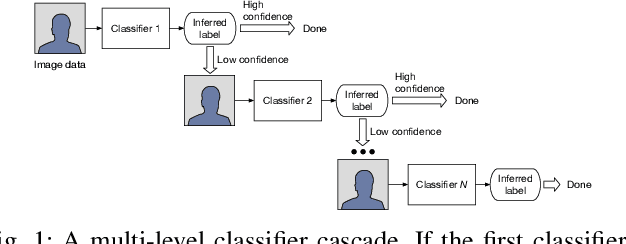

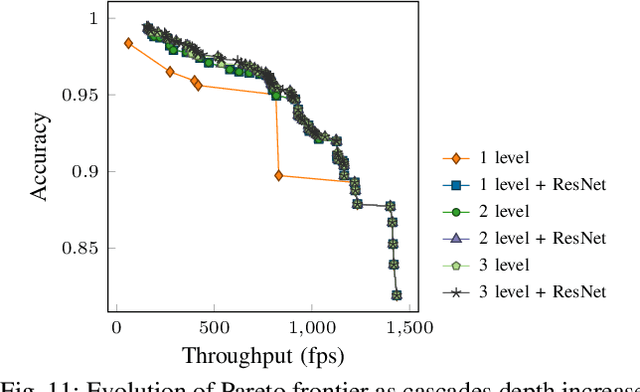
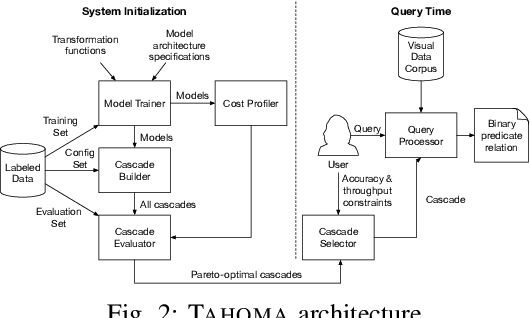
Querying the content of images, video, and other non-textual data sources requires expensive content extraction methods. Modern extraction techniques are based on deep convolutional neural networks (CNNs) and can classify objects within images with astounding accuracy. Unfortunately, these methods are slow: processing a single image can take about 10 milliseconds on modern GPU-based hardware. As massive video libraries become ubiquitous, running a content-based query over millions of video frames is prohibitive. One promising approach to reduce the runtime cost of queries of visual content is to use a hierarchical model, such as a cascade, where simple cases are handled by an inexpensive classifier. Prior work has sought to design cascades that optimize the computational cost of inference by, for example, using smaller CNNs. However, we observe that there are critical factors besides the inference time that dramatically impact the overall query time. Notably, by treating the physical representation of the input image as part of our query optimization---that is, by including image transforms, such as resolution scaling or color-depth reduction, within the cascade---we can optimize data handling costs and enable drastically more efficient classifier cascades. In this paper, we propose Tahoma, which generates and evaluates many potential classifier cascades that jointly optimize the CNN architecture and input data representation. Our experiments on a subset of ImageNet show that Tahoma's input transformations speed up cascades by up to 35 times. We also find up to a 98x speedup over the ResNet50 classifier with no loss in accuracy, and a 280x speedup if some accuracy is sacrificed.
Joint Coarse-And-Fine Reasoning for Deep Optical Flow
Aug 22, 2018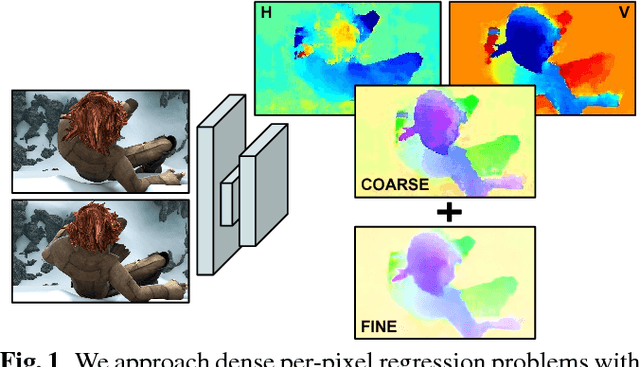
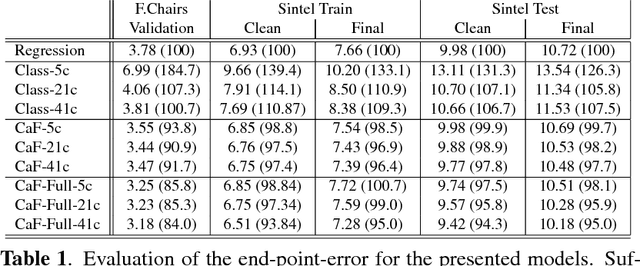
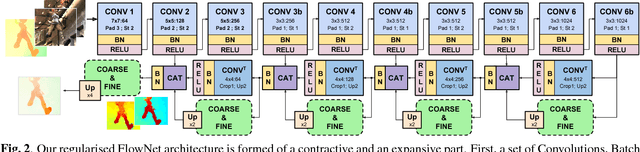
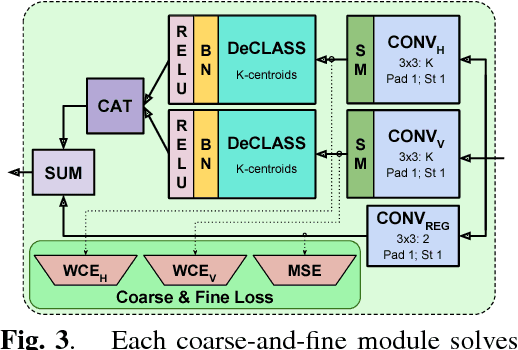
We propose a novel representation for dense pixel-wise estimation tasks using CNNs that boosts accuracy and reduces training time, by explicitly exploiting joint coarse-and-fine reasoning. The coarse reasoning is performed over a discrete classification space to obtain a general rough solution, while the fine details of the solution are obtained over a continuous regression space. In our approach both components are jointly estimated, which proved to be beneficial for improving estimation accuracy. Additionally, we propose a new network architecture, which combines coarse and fine components by treating the fine estimation as a refinement built on top of the coarse solution, and therefore adding details to the general prediction. We apply our approach to the challenging problem of optical flow estimation and empirically validate it against state-of-the-art CNN-based solutions trained from scratch and tested on large optical flow datasets.
A Dataset To Evaluate The Representations Learned By Video Prediction Models
Mar 22, 2018


We present a parameterized synthetic dataset called Moving Symbols to support the objective study of video prediction networks. Using several instantiations of the dataset in which variation is explicitly controlled, we highlight issues in an existing state-of-the-art approach and propose the use of a performance metric with greater semantic meaning to improve experimental interpretability. Our dataset provides canonical test cases that will help the community better understand, and eventually improve, the representations learned by such networks in the future. Code is available at https://github.com/rszeto/moving-symbols .
CARLA: An Open Urban Driving Simulator
Nov 10, 2017
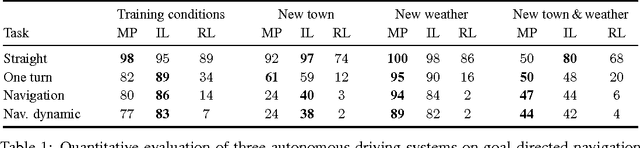

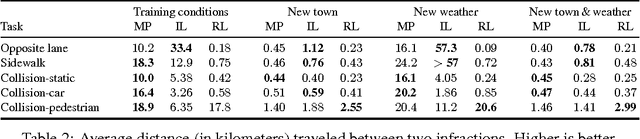
We introduce CARLA, an open-source simulator for autonomous driving research. CARLA has been developed from the ground up to support development, training, and validation of autonomous urban driving systems. In addition to open-source code and protocols, CARLA provides open digital assets (urban layouts, buildings, vehicles) that were created for this purpose and can be used freely. The simulation platform supports flexible specification of sensor suites and environmental conditions. We use CARLA to study the performance of three approaches to autonomous driving: a classic modular pipeline, an end-to-end model trained via imitation learning, and an end-to-end model trained via reinforcement learning. The approaches are evaluated in controlled scenarios of increasing difficulty, and their performance is examined via metrics provided by CARLA, illustrating the platform's utility for autonomous driving research. The supplementary video can be viewed at https://youtu.be/Hp8Dz-Zek2E
From Virtual to Real World Visual Perception using Domain Adaptation -- The DPM as Example
Dec 29, 2016
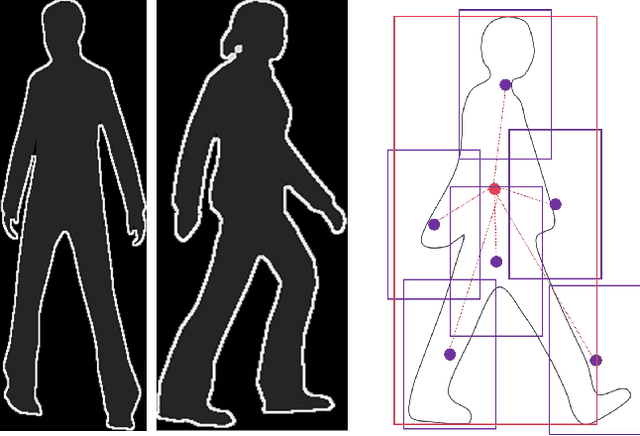
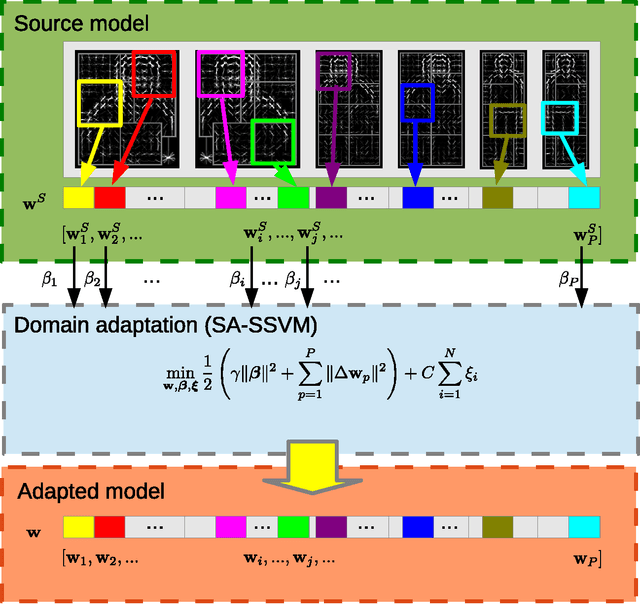

Supervised learning tends to produce more accurate classifiers than unsupervised learning in general. This implies that training data is preferred with annotations. When addressing visual perception challenges, such as localizing certain object classes within an image, the learning of the involved classifiers turns out to be a practical bottleneck. The reason is that, at least, we have to frame object examples with bounding boxes in thousands of images. A priori, the more complex the model is regarding its number of parameters, the more annotated examples are required. This annotation task is performed by human oracles, which ends up in inaccuracies and errors in the annotations (aka ground truth) since the task is inherently very cumbersome and sometimes ambiguous. As an alternative we have pioneered the use of virtual worlds for collecting such annotations automatically and with high precision. However, since the models learned with virtual data must operate in the real world, we still need to perform domain adaptation (DA). In this chapter we revisit the DA of a deformable part-based model (DPM) as an exemplifying case of virtual- to-real-world DA. As a use case, we address the challenge of vehicle detection for driver assistance, using different publicly available virtual-world data. While doing so, we investigate questions such as: how does the domain gap behave due to virtual-vs-real data with respect to dominant object appearance per domain, as well as the role of photo-realism in the virtual world.
Training Constrained Deconvolutional Networks for Road Scene Semantic Segmentation
Apr 06, 2016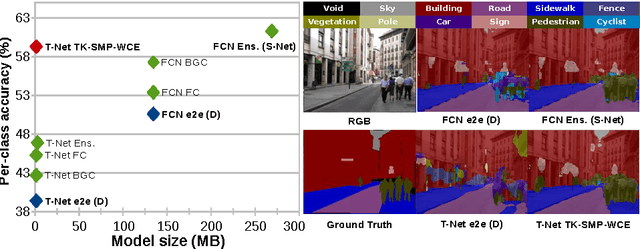
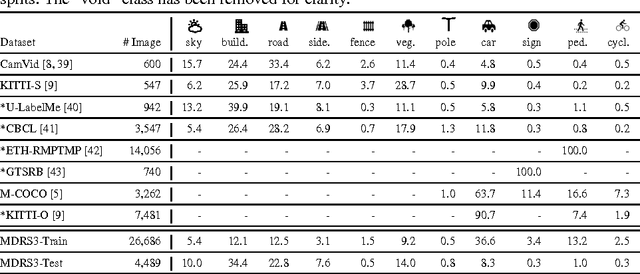

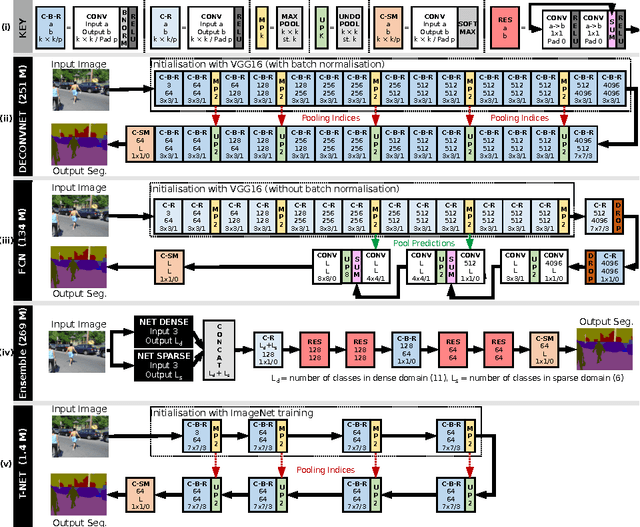
In this work we investigate the problem of road scene semantic segmentation using Deconvolutional Networks (DNs). Several constraints limit the practical performance of DNs in this context: firstly, the paucity of existing pixel-wise labelled training data, and secondly, the memory constraints of embedded hardware, which rule out the practical use of state-of-the-art DN architectures such as fully convolutional networks (FCN). To address the first constraint, we introduce a Multi-Domain Road Scene Semantic Segmentation (MDRS3) dataset, aggregating data from six existing densely and sparsely labelled datasets for training our models, and two existing, separate datasets for testing their generalisation performance. We show that, while MDRS3 offers a greater volume and variety of data, end-to-end training of a memory efficient DN does not yield satisfactory performance. We propose a new training strategy to overcome this, based on (i) the creation of a best-possible source network (S-Net) from the aggregated data, ignoring time and memory constraints; and (ii) the transfer of knowledge from S-Net to the memory-efficient target network (T-Net). We evaluate different techniques for S-Net creation and T-Net transferral, and demonstrate that training a constrained deconvolutional network in this manner can unlock better performance than existing training approaches. Specifically, we show that a target network can be trained to achieve improved accuracy versus an FCN despite using less than 1\% of the memory. We believe that our approach can be useful beyond automotive scenarios where labelled data is similarly scarce or fragmented and where practical constraints exist on the desired model size. We make available our network models and aggregated multi-domain dataset for reproducibility.
Fast and Robust Fixed-Rank Matrix Recovery
Mar 25, 2015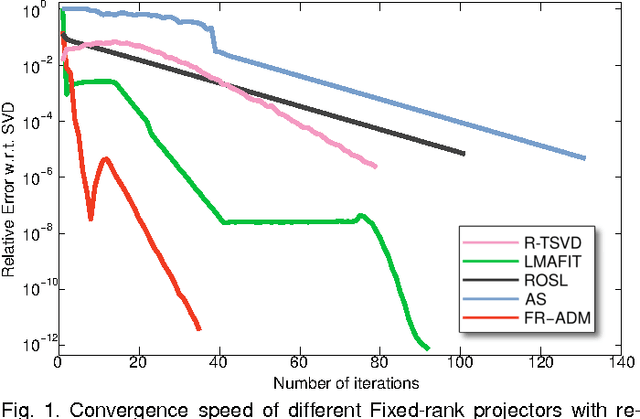



We address the problem of efficient sparse fixed-rank (S-FR) matrix decomposition, i.e., splitting a corrupted matrix $M$ into an uncorrupted matrix $L$ of rank $r$ and a sparse matrix of outliers $S$. Fixed-rank constraints are usually imposed by the physical restrictions of the system under study. Here we propose a method to perform accurate and very efficient S-FR decomposition that is more suitable for large-scale problems than existing approaches. Our method is a grateful combination of geometrical and algebraical techniques, which avoids the bottleneck caused by the Truncated SVD (TSVD). Instead, a polar factorization is used to exploit the manifold structure of fixed-rank problems as the product of two Stiefel and an SPD manifold, leading to a better convergence and stability. Then, closed-form projectors help to speed up each iteration of the method. We introduce a novel and fast projector for the $\text{SPD}$ manifold and a proof of its validity. Further acceleration is achieved using a Nystrom scheme. Extensive experiments with synthetic and real data in the context of robust photometric stereo and spectral clustering show that our proposals outperform the state of the art.