 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Optical Flow, Depth, and Scene Flow without Real-World Labels
Mar 28, 2022


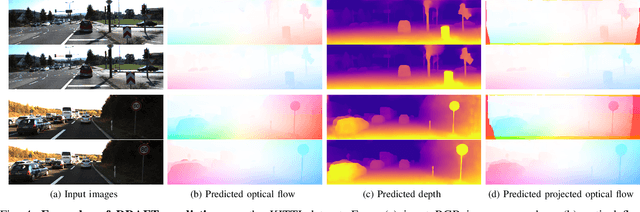
Self-supervised monocular depth estimation enables robots to learn 3D perception from raw video streams. This scalable approach leverages projective geometry and ego-motion to learn via view synthesis, assuming the world is mostly static. Dynamic scenes, which are common in autonomous driving and human-robot interaction, violate this assumption. Therefore, they require modeling dynamic objects explicitly, for instance via estimating pixel-wise 3D motion, i.e. scene flow. However, the simultaneous self-supervised learning of depth and scene flow is ill-posed, as there are infinitely many combinations that result in the same 3D point. In this paper we propose DRAFT, a new method capable of jointly learning depth, optical flow, and scene flow by combining synthetic data with geometric self-supervision. Building upon the RAFT architecture, we learn optical flow as an intermediate task to bootstrap depth and scene flow learning via triangulation. Our algorithm also leverages temporal and geometric consistency losses across tasks to improve multi-task learning. Our DRAFT architecture simultaneously establishes a new state of the art in all three tasks in the self-supervised monocular setting on the standard KITTI benchmark. Project page: https://sites.google.com/tri.global/draft.
CoCon: Cooperative-Contrastive Learning
Apr 30, 2021

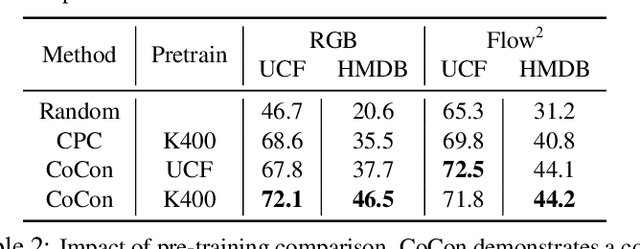
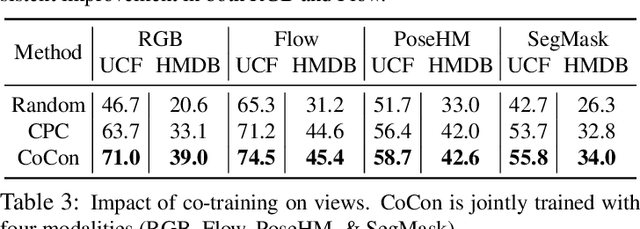
Labeling videos at scale is impractical. Consequently, self-supervised visual representation learning is key for efficient video analysis. Recent success in learning image representations suggests contrastive learning is a promising framework to tackle this challenge. However, when applied to real-world videos, contrastive learning may unknowingly lead to the separation of instances that contain semantically similar events. In our work, we introduce a cooperative variant of contrastive learning to utilize complementary information across views and address this issue. We use data-driven sampling to leverage implicit relationships between multiple input video views, whether observed (e.g. RGB) or inferred (e.g. flow, segmentation masks, poses). We are one of the firsts to explore exploiting inter-instance relationships to drive learning. We experimentally evaluate our representations on the downstream task of action recognition. Our method achieves competitive performance on standard benchmarks (UCF101, HMDB51, Kinetics400). Furthermore, qualitative experiments illustrate that our models can capture higher-order class relationships.
Heterogeneous-Agent Trajectory Forecasting Incorporating Class Uncertainty
Apr 26, 2021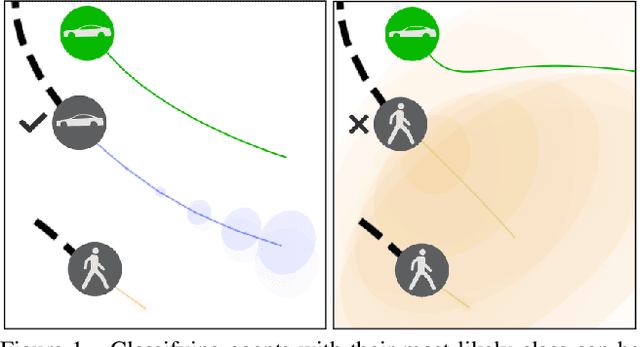
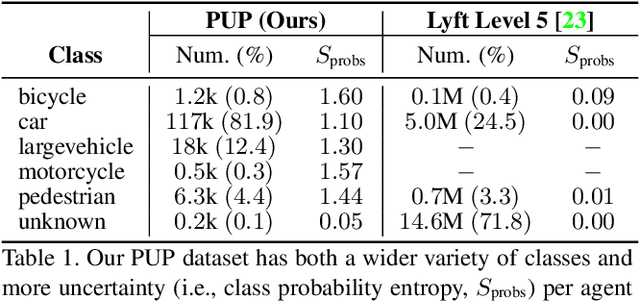
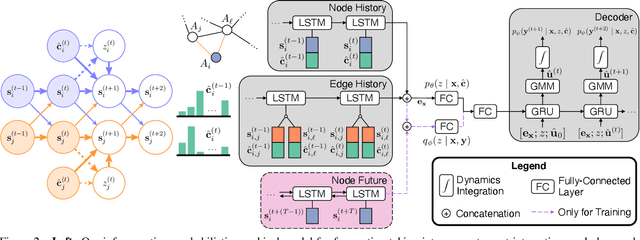

Reasoning about the future behavior of other agents is critical to safe robot navigation. The multiplicity of plausible futures is further amplified by the uncertainty inherent to agent state estimation from data, including positions, velocities, and semantic class. Forecasting methods, however, typically neglect class uncertainty, conditioning instead only on the agent's most likely class, even though perception models often return full class distributions. To exploit this information, we present HAICU, a method for heterogeneous-agent trajectory forecasting that explicitly incorporates agents' class probabilities. We additionally present PUP, a new challenging real-world autonomous driving dataset, to investigate the impact of Perceptual Uncertainty in Prediction. It contains challenging crowded scenes with unfiltered agent class probabilities that reflect the long-tail of current state-of-the-art perception systems. We demonstrate that incorporating class probabilities in trajectory forecasting significantly improves performance in the face of uncertainty, and enables new forecasting capabilities such as counterfactual predictions.
An Interaction-aware Evaluation Method for Highly Automated Vehicles
Feb 23, 2021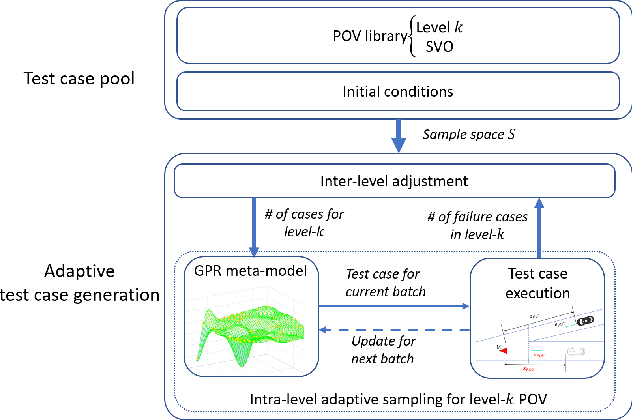
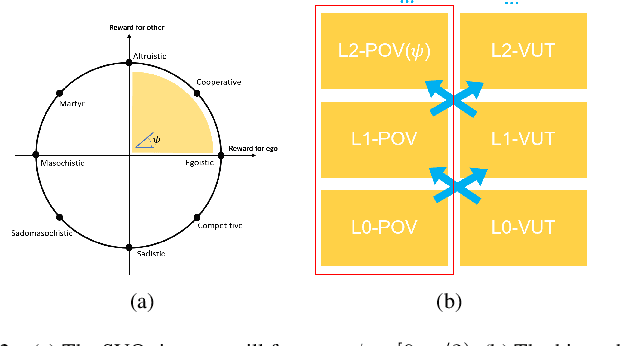
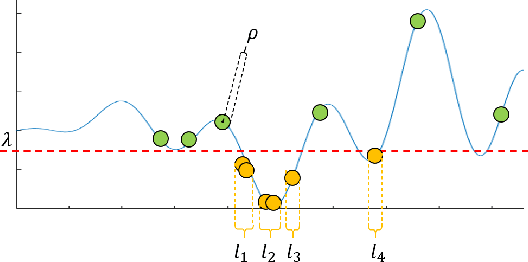
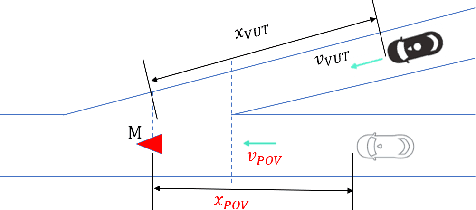
It is important to build a rigorous verification and validation (V&V) process to evaluate the safety of highly automated vehicles (HAVs) before their wide deployment on public roads. In this paper, we propose an interaction-aware framework for HAV safety evaluation which is suitable for some highly-interactive driving scenarios including highway merging, roundabout entering, etc. Contrary to existing approaches where the primary other vehicle (POV) takes predetermined maneuvers, we model the POV as a game-theoretic agent. To capture a wide variety of interactions between the POV and the vehicle under test (VUT), we characterize the interactive behavior using level-k game theory and social value orientation and train a diverse set of POVs using reinforcement learning. Moreover, we propose an adaptive test case sampling scheme based on the Gaussian process regression technique to generate customized and diverse challenging cases. The highway merging is used as the example scenario. We found the proposed method is able to capture a wide range of POV behaviors and achieve better coverage of the failure modes of the VUT compared with other evaluation approaches.
Discovering Avoidable Planner Failures of Autonomous Vehicles using Counterfactual Analysis in Behaviorally Diverse Simulation
Nov 24, 2020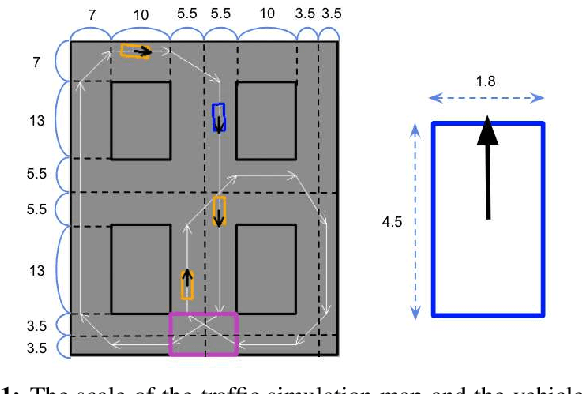
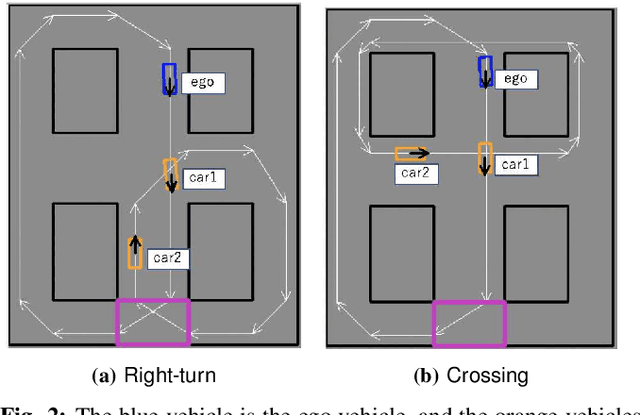
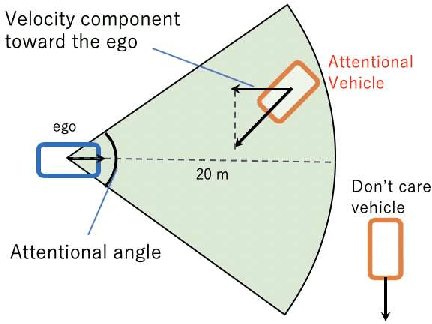
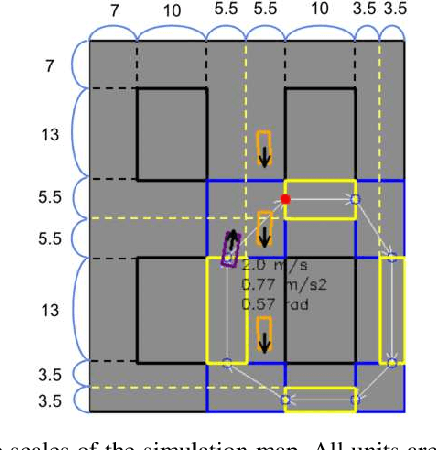
Automated Vehicles require exhaustive testing in simulation to detect as many safety-critical failures as possible before deployment on public roads. In this work, we focus on the core decision-making component of autonomous robots: their planning algorithm. We introduce a planner testing framework that leverages recent progress in simulating behaviorally diverse traffic participants. Using large scale search, we generate, detect, and characterize dynamic scenarios leading to collisions. In particular, we propose methods to distinguish between unavoidable and avoidable accidents, focusing especially on automatically finding planner-specific defects that must be corrected before deployment. Through experiments in complex multi-agent intersection scenarios, we show that our method can indeed find a wide range of critical planner failures.
* 8 pages, 8 figures
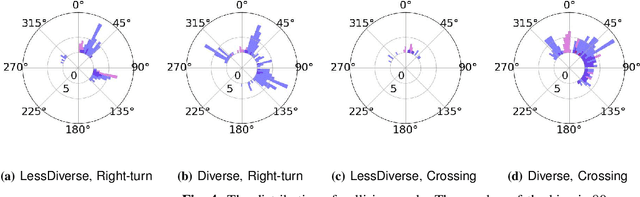
Behaviorally Diverse Traffic Simulation via Reinforcement Learning
Nov 11, 2020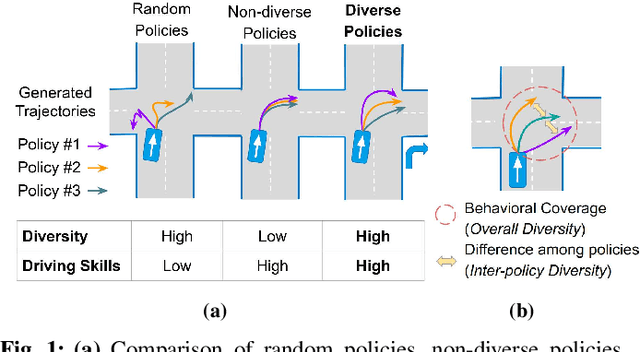


Traffic simulators are important tools in autonomous driving development. While continuous progress has been made to provide developers more options for modeling various traffic participants, tuning these models to increase their behavioral diversity while maintaining quality is often very challenging. This paper introduces an easily-tunable policy generation algorithm for autonomous driving agents. The proposed algorithm balances diversity and driving skills by leveraging the representation and exploration abilities of deep reinforcement learning via a distinct policy set selector. Moreover, we present an algorithm utilizing intrinsic rewards to widen behavioral differences in the training. To provide quantitative assessments, we develop two trajectory-based evaluation metrics which measure the differences among policies and behavioral coverage. We experimentally show the effectiveness of our methods on several challenging intersection scenes.
* 8 pages, 16 figures
PillarFlow: End-to-end Birds-eye-view Flow Estimation for Autonomous Driving
Aug 29, 2020
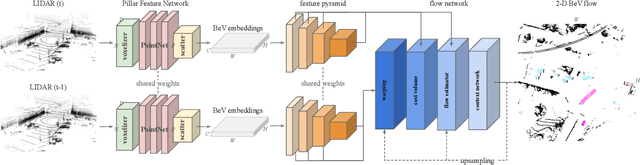

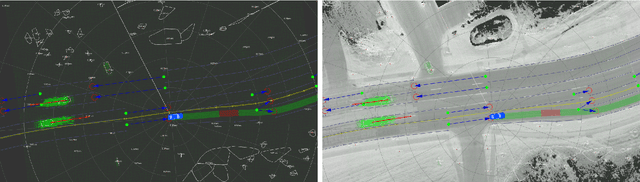
In autonomous driving, accurately estimating the state of surrounding obstacles is critical for safe and robust path planning. However, this perception task is difficult, particularly for generic obstacles/objects, due to appearance and occlusion changes. To tackle this problem, we propose an end-to-end deep learning framework for LIDAR-based flow estimation in bird's eye view (BeV). Our method takes consecutive point cloud pairs as input and produces a 2-D BeV flow grid describing the dynamic state of each cell. The experimental results show that the proposed method not only estimates 2-D BeV flow accurately but also improves tracking performance of both dynamic and static objects.
It Is Not the Journey but the Destination: Endpoint Conditioned Trajectory Prediction
Apr 04, 2020

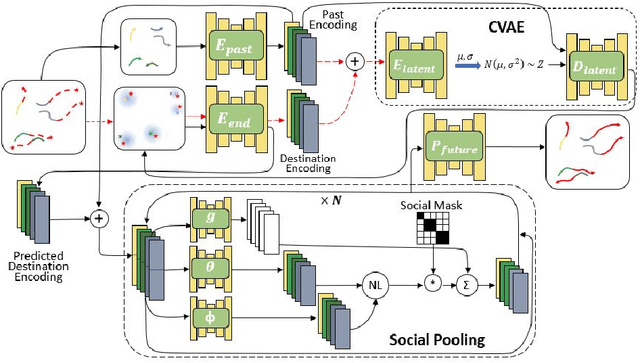
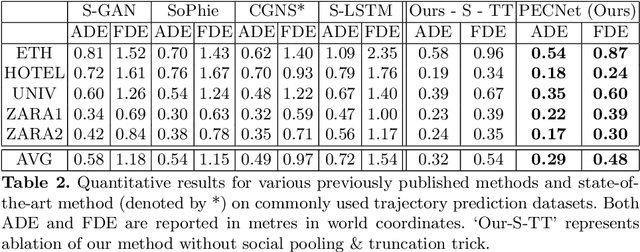
Human trajectory forecasting with multiple socially interacting agents is of critical importance for autonomous navigation in human environments, e.g., for self-driving cars and social robots. In this work, we present Predicted Endpoint Conditioned Network (PECNet) for flexible human trajectory prediction. PECNet infers distant trajectory endpoints to assist in long-range multi-modal trajectory prediction. A novel non-local social pooling layer enables PECNet to infer diverse yet socially compliant trajectories. Additionally, we present a simple "truncation-trick" for improving few-shot multi-modal trajectory prediction performance. We show that PECNet improves state-of-the-art performance on the Stanford Drone trajectory prediction benchmark by ~19.5% and on the ETH/UCY benchmark by ~40.8%.
Spatio-Temporal Graph for Video Captioning with Knowledge Distillation
Mar 31, 2020
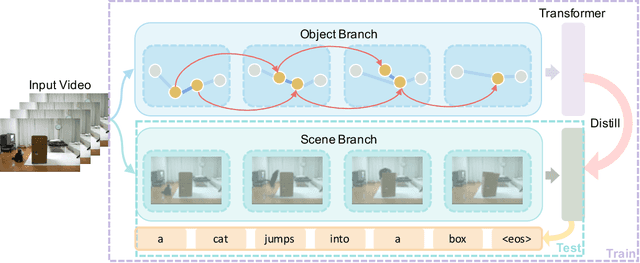
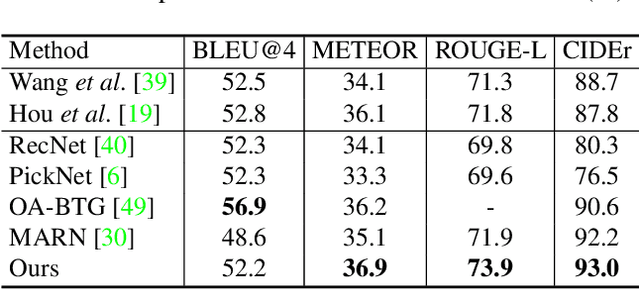

Video captioning is a challenging task that requires a deep understanding of visual scenes. State-of-the-art methods generate captions using either scene-level or object-level information but without explicitly modeling object interactions. Thus, they often fail to make visually grounded predictions, and are sensitive to spurious correlations. In this paper, we propose a novel spatio-temporal graph model for video captioning that exploits object interactions in space and time. Our model builds interpretable links and is able to provide explicit visual grounding. To avoid unstable performance caused by the variable number of objects, we further propose an object-aware knowledge distillation mechanism, in which local object information is used to regularize global scene features. We demonstrate the efficacy of our approach through extensive experiments on two benchmarks, showing our approach yields competitive performance with interpretable predictions.
Spatiotemporal Relationship Reasoning for Pedestrian Intent Prediction
Feb 20, 2020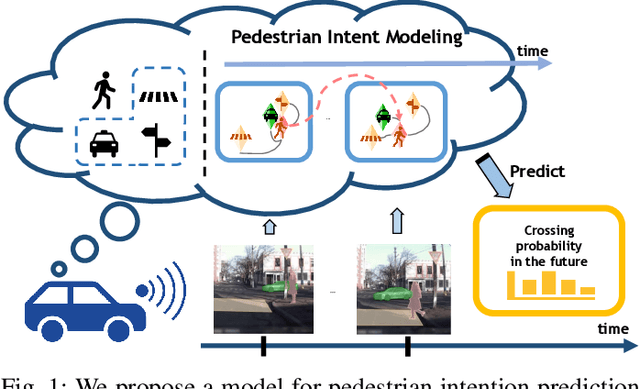
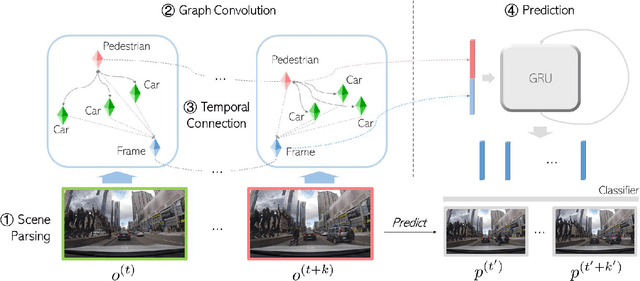


Reasoning over visual data is a desirable capability for robotics and vision-based applications. Such reasoning enables forecasting of the next events or actions in videos. In recent years, various models have been developed based on convolution operations for prediction or forecasting, but they lack the ability to reason over spatiotemporal data and infer the relationships of different objects in the scene. In this paper, we present a framework based on graph convolution to uncover the spatiotemporal relationships in the scene for reasoning about pedestrian intent. A scene graph is built on top of segmented object instances within and across video frames. Pedestrian intent, defined as the future action of crossing or not-crossing the street, is a very crucial piece of information for autonomous vehicles to navigate safely and more smoothly. We approach the problem of intent prediction from two different perspectives and anticipate the intention-to-cross within both pedestrian-centric and location-centric scenarios. In addition, we introduce a new dataset designed specifically for autonomous-driving scenarios in areas with dense pedestrian populations: the Stanford-TRI Intent Prediction (STIP) dataset. Our experiments on STIP and another benchmark dataset show that our graph modeling framework is able to predict the intention-to-cross of the pedestrians with an accuracy of 79.10% on STIP and 79.28% on \rev{Joint Attention for Autonomous Driving (JAAD) dataset up to one second earlier than when the actual crossing happens. These results outperform the baseline and previous work. Please refer to http://stip.stanford.edu/ for the dataset and code.