 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe MineRL 2020 Competition on Sample Efficient Reinforcement Learning using Human Priors
Jan 26, 2021
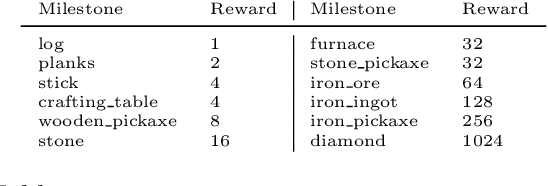
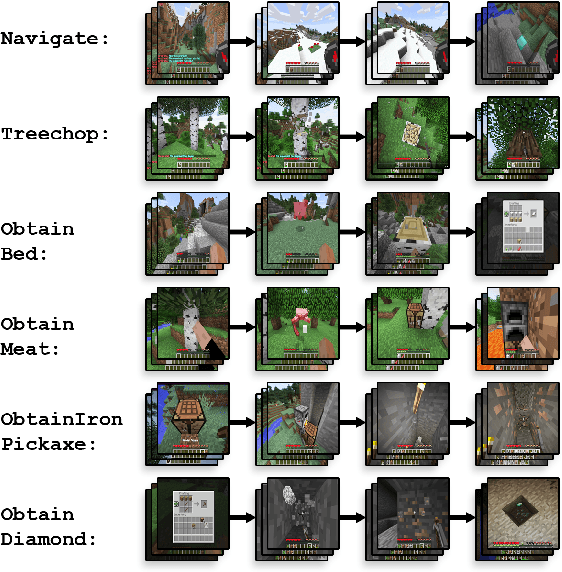
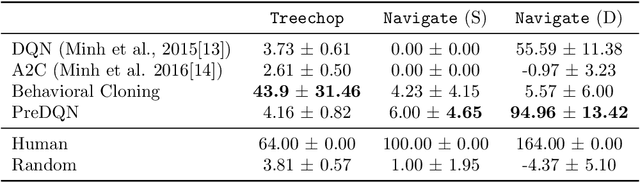
Although deep reinforcement learning has led to breakthroughs in many difficult domains, these successes have required an ever-increasing number of samples, affording only a shrinking segment of the AI community access to their development. Resolution of these limitations requires new, sample-efficient methods. To facilitate research in this direction, we propose this second iteration of the MineRL Competition. The primary goal of the competition is to foster the development of algorithms which can efficiently leverage human demonstrations to drastically reduce the number of samples needed to solve complex, hierarchical, and sparse environments. To that end, participants compete under a limited environment sample-complexity budget to develop systems which solve the MineRL ObtainDiamond task in Minecraft, a sequential decision making environment requiring long-term planning, hierarchical control, and efficient exploration methods. The competition is structured into two rounds in which competitors are provided several paired versions of the dataset and environment with different game textures and shaders. At the end of each round, competitors submit containerized versions of their learning algorithms to the AIcrowd platform where they are trained from scratch on a hold-out dataset-environment pair for a total of 4-days on a pre-specified hardware platform. In this follow-up iteration to the NeurIPS 2019 MineRL Competition, we implement new features to expand the scale and reach of the competition. In response to the feedback of the previous participants, we introduce a second minor track focusing on solutions without access to environment interactions of any kind except during test-time. Further we aim to prompt domain agnostic submissions by implementing several novel competition mechanics including action-space randomization and desemantization of observations and actions.
Discovering Avoidable Planner Failures of Autonomous Vehicles using Counterfactual Analysis in Behaviorally Diverse Simulation
Nov 24, 2020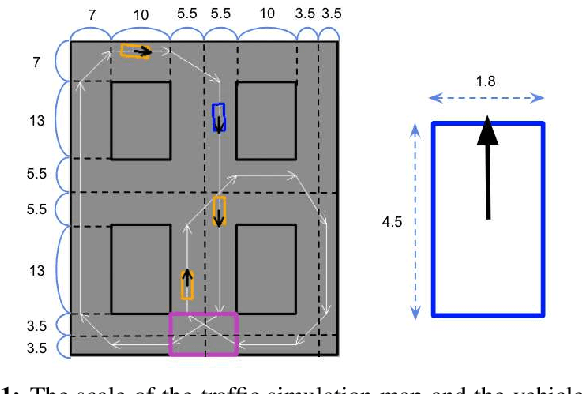
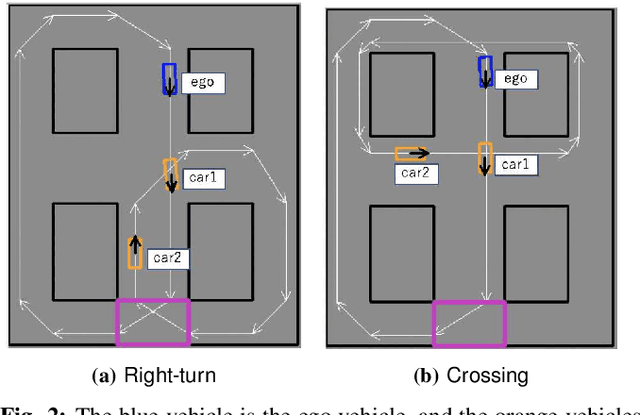
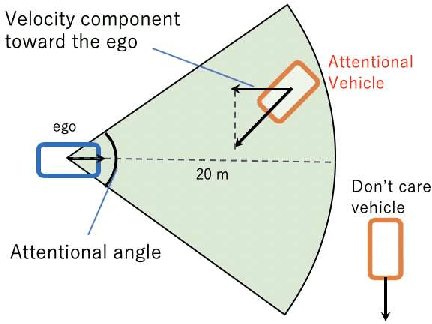
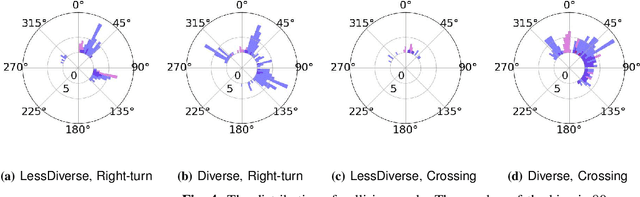
Automated Vehicles require exhaustive testing in simulation to detect as many safety-critical failures as possible before deployment on public roads. In this work, we focus on the core decision-making component of autonomous robots: their planning algorithm. We introduce a planner testing framework that leverages recent progress in simulating behaviorally diverse traffic participants. Using large scale search, we generate, detect, and characterize dynamic scenarios leading to collisions. In particular, we propose methods to distinguish between unavoidable and avoidable accidents, focusing especially on automatically finding planner-specific defects that must be corrected before deployment. Through experiments in complex multi-agent intersection scenarios, we show that our method can indeed find a wide range of critical planner failures.
* 8 pages, 8 figures
Behaviorally Diverse Traffic Simulation via Reinforcement Learning
Nov 11, 2020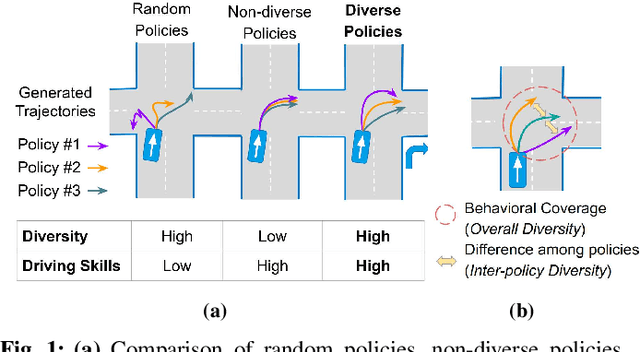


Traffic simulators are important tools in autonomous driving development. While continuous progress has been made to provide developers more options for modeling various traffic participants, tuning these models to increase their behavioral diversity while maintaining quality is often very challenging. This paper introduces an easily-tunable policy generation algorithm for autonomous driving agents. The proposed algorithm balances diversity and driving skills by leveraging the representation and exploration abilities of deep reinforcement learning via a distinct policy set selector. Moreover, we present an algorithm utilizing intrinsic rewards to widen behavioral differences in the training. To provide quantitative assessments, we develop two trajectory-based evaluation metrics which measure the differences among policies and behavioral coverage. We experimentally show the effectiveness of our methods on several challenging intersection scenes.
* 8 pages, 16 figures
Distributed Reinforcement Learning of Targeted Grasping with Active Vision for Mobile Manipulators
Jul 16, 2020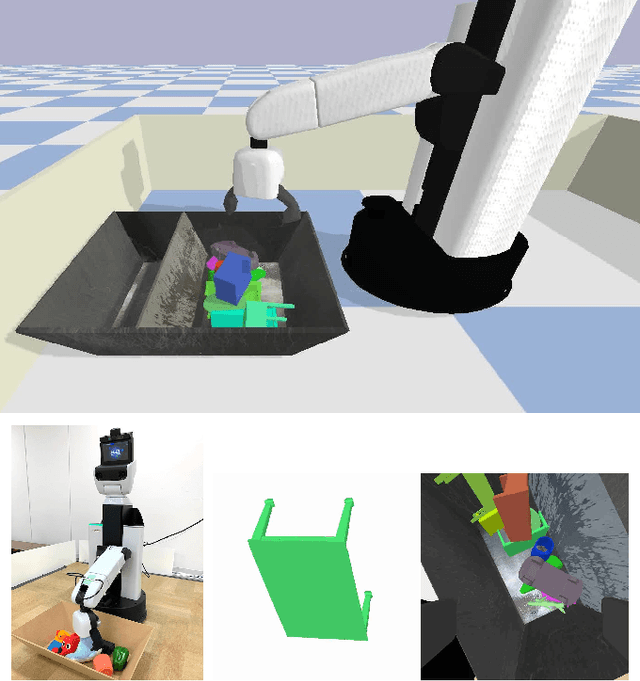
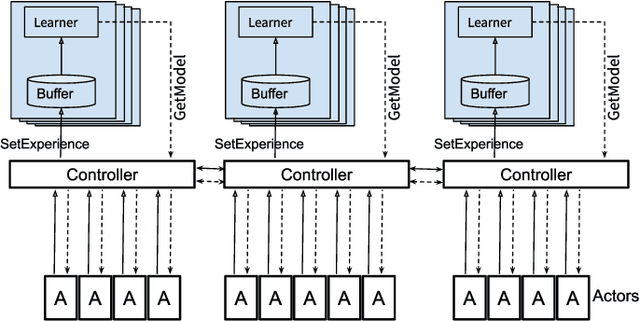
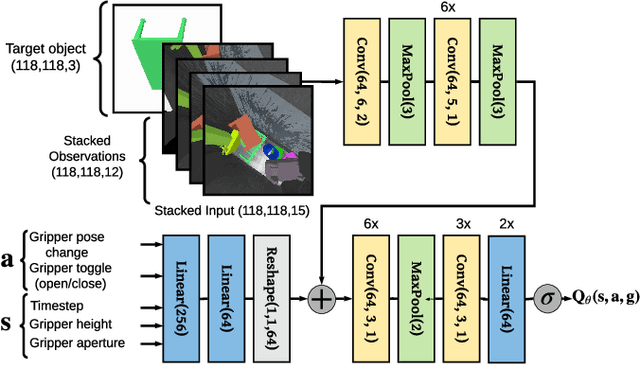
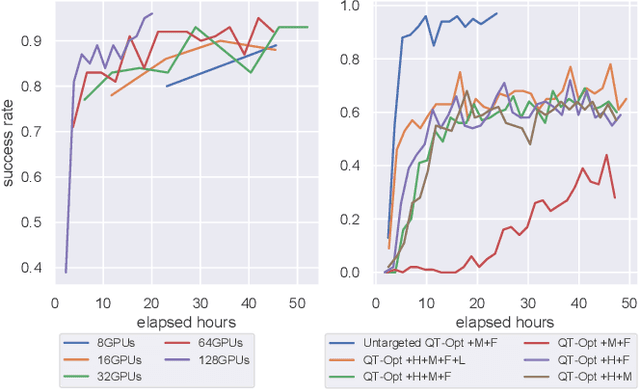
Developing personal robots that can perform a diverse range of manipulation tasks in unstructured environments necessitates solving several challenges for robotic grasping systems. We take a step towards this broader goal by presenting the first RL-based system, to our knowledge, for a mobile manipulator that can (a) achieve targeted grasping generalizing to unseen target objects, (b) learn complex grasping strategies for cluttered scenes with occluded objects, and (c) perform active vision through its movable wrist camera to better locate objects. The system is informed of the desired target object in the form of a single, arbitrary-pose RGB image of that object, enabling the system to generalize to unseen objects without retraining. To achieve such a system, we combine several advances in deep reinforcement learning and present a large-scale distributed training system using synchronous SGD that seamlessly scales to multi-node, multi-GPU infrastructure to make rapid prototyping easier. We train and evaluate our system in a simulated environment, identify key components for improving performance, analyze its behaviors, and transfer to a real-world setup.
IntPhys: A Framework and Benchmark for Visual Intuitive Physics Reasoning
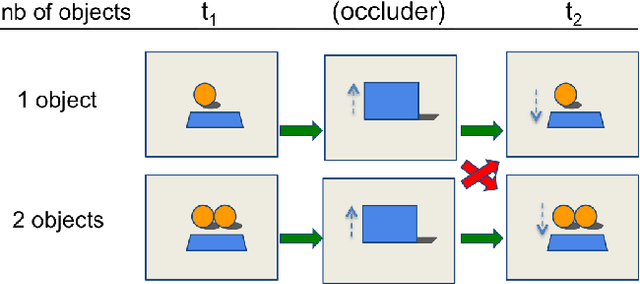
Jun 26, 2018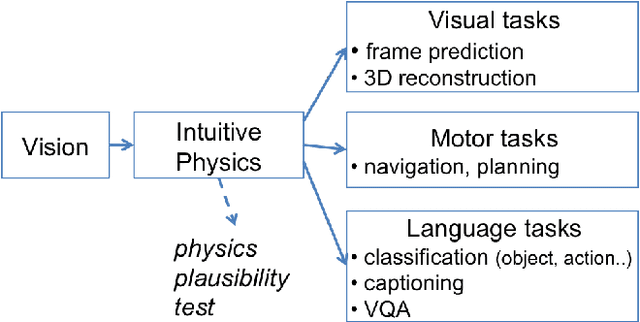

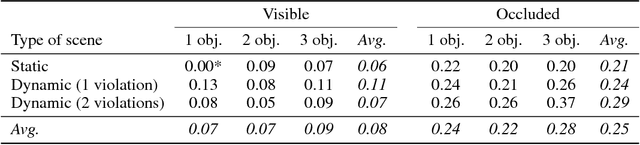
In order to reach human performance on complex visual tasks, artificial systems need to incorporate a significant amount of understanding of the world in terms of macroscopic objects, movements, forces, etc. Inspired by work on intuitive physics in infants, we propose an evaluation framework which diagnoses how much a given system understands about physics by testing whether it can tell apart well matched videos of possible versus impossible events. The test requires systems to compute a physical plausibility score over an entire video. It is free of bias and can test a range of specific physical reasoning skills. We then describe the first release of a benchmark dataset aimed at learning intuitive physics in an unsupervised way, using videos constructed with a game engine. We describe two Deep Neural Network baseline systems trained with a future frame prediction objective and tested on the possible versus impossible discrimination task. The analysis of their results compared to human data gives novel insights in the potentials and limitations of next frame prediction architectures.