 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpatio-Temporal Retrieval-based Priors for Adaptive Computational Teaching in Driving
Jun 23, 2026Learning-based automated coaching systems for complex motor tasks such as high-performance driving remain limited in the ability to be adaptive by their reliance only on local, context-dependent reasoning, failing to account for the long-term temporal nature of student learning and the cumulative impact of repeated teacher-student interactions. In this paper, we propose an imitation learning based computational model for adaptive teaching with a dedicated temporal reasoning module that can reason over the interaction history under low-data regimes. To compensate for limited amounts of interactive training data, and based on the repetitive nature of the teaching process, the model relies on a nearest neighbor retrieval and cross attention prior, reasoning only on a narrowed-down set of semantically similar past interactions with an encoder-decoder based concurrent teaching model. We validate our approach with (i) a novel semi-synthetic closed-loop longitudinal student-teacher interaction dataset based on Waymo Open Motion Dataset and (ii) a small-scale real-world naturalistic simulator race coaching dataset. Our results reveal the consistent advantage of our adaptive teaching model with the nearest neighbor retrieval and cross-attention prior over a non-adaptive baseline as well as a suite of adaptive models that differ in their choice of priors and temporal fusion mechanisms.
Boundary Sampling to Learn Predictive Safety Filters via Pontryagin's Maximum Principle
Apr 14, 2026Safety filters provide a practical approach for enforcing safety constraints in autonomous systems. While learning-based tools scale to high-dimensional systems, their performance depends on informative data that includes states likely to lead to constraint violation, which can be difficult to efficiently sample in complex, high-dimensional systems. In this work, we characterize trajectories that barely avoid safety violations using the Pontryagin Maximum Principle. These boundary trajectories are used to guide data collection for learned Hamilton-Jacobi Reachability, concentrating learning efforts near safety-critical states to improve efficiency. The learned Control Barrier Value Function is then used directly for safety filtering. Simulations and experimental validation on a shared-control automotive racing application demonstrate PMP sampling improves learning efficiency, yielding faster convergence, reduced failure rates, and improved safe set reconstruction, with wall times around 3ms.
On the Strengths and Weaknesses of Data for Open-set Embodied Assistance
Mar 05, 2026Embodied foundation models are increasingly performant in real-world domains such as robotics or autonomous driving. These models are often deployed in interactive or assistive settings, where it is important that these assistive models generalize to new users and new tasks. Diverse interactive data generation offers a promising avenue for providing data-efficient generalization capabilities for interactive embodied foundation models. In this paper, we investigate the generalization capabilities of a multimodal foundation model fine-tuned on diverse interactive assistance data in a synthetic domain. We explore generalization along two axes: a) assistance with unseen categories of user behavior and b) providing guidance in new configurations not encountered during training. We study a broad capability called \textbf{Open-Set Corrective Assistance}, in which the model needs to inspect lengthy user behavior and provide assistance through either corrective actions or language-based feedback. This task remains unsolved in prior work, which typically assumes closed corrective categories or relies on external planners, making it a challenging testbed for evaluating the limits of assistive data. To support this task, we generate synthetic assistive datasets in Overcooked and fine-tune a LLaMA-based model to evaluate generalization to novel tasks and user behaviors. Our approach provides key insights into the nature of assistive datasets required to enable open-set assistive intelligence. In particular, we show that performant models benefit from datasets that cover different aspects of assistance, including multimodal grounding, defect inference, and exposure to diverse scenarios.
Learning to Plan, Planning to Learn: Adaptive Hierarchical RL-MPC for Sample-Efficient Decision Making
Dec 18, 2025We propose a new approach for solving planning problems with a hierarchical structure, fusing reinforcement learning and MPC planning. Our formulation tightly and elegantly couples the two planning paradigms. It leverages reinforcement learning actions to inform the MPPI sampler, and adaptively aggregates MPPI samples to inform the value estimation. The resulting adaptive process leverages further MPPI exploration where value estimates are uncertain, and improves training robustness and the overall resulting policies. This results in a robust planning approach that can handle complex planning problems and easily adapts to different applications, as demonstrated over several domains, including race driving, modified Acrobot, and Lunar Lander with added obstacles. Our results in these domains show better data efficiency and overall performance in terms of both rewards and task success, with up to a 72% increase in success rate compared to existing approaches, as well as accelerated convergence (x2.1) compared to non-adaptive sampling.
Estimating cognitive biases with attention-aware inverse planning
Oct 29, 2025



People's goal-directed behaviors are influenced by their cognitive biases, and autonomous systems that interact with people should be aware of this. For example, people's attention to objects in their environment will be biased in a way that systematically affects how they perform everyday tasks such as driving to work. Here, building on recent work in computational cognitive science, we formally articulate the attention-aware inverse planning problem, in which the goal is to estimate a person's attentional biases from their actions. We demonstrate how attention-aware inverse planning systematically differs from standard inverse reinforcement learning and how cognitive biases can be inferred from behavior. Finally, we present an approach to attention-aware inverse planning that combines deep reinforcement learning with computational cognitive modeling. We use this approach to infer the attentional strategies of RL agents in real-life driving scenarios selected from the Waymo Open Dataset, demonstrating the scalability of estimating cognitive biases with attention-aware inverse planning.
Timing the Message: Language-Based Notifications for Time-Critical Assistive Settings
Sep 09, 2025In time-critical settings such as assistive driving, assistants often rely on alerts or haptic signals to prompt rapid human attention, but these cues usually leave humans to interpret situations and decide responses independently, introducing potential delays or ambiguity in meaning. Language-based assistive systems can instead provide instructions backed by context, offering more informative guidance. However, current approaches (e.g., social assistive robots) largely prioritize content generation while overlooking critical timing factors such as verbal conveyance duration, human comprehension delays, and subsequent follow-through duration. These timing considerations are crucial in time-critical settings, where even minor delays can substantially affect outcomes. We aim to study this inherent trade-off between timeliness and informativeness by framing the challenge as a sequential decision-making problem using an augmented-state Markov Decision Process. We design a framework combining reinforcement learning and a generated offline taxonomy dataset, where we balance the trade-off while enabling a scalable taxonomy dataset generation pipeline. Empirical evaluation with synthetic humans shows our framework improves success rates by over 40% compared to methods that ignore time delays, while effectively balancing timeliness and informativeness. It also exposes an often-overlooked trade-off between these two factors, opening new directions for optimizing communication in time-critical human-AI assistance.
Dreaming to Assist: Learning to Align with Human Objectives for Shared Control in High-Speed Racing
Oct 14, 2024Tight coordination is required for effective human-robot teams in domains involving fast dynamics and tactical decisions, such as multi-car racing. In such settings, robot teammates must react to cues of a human teammate's tactical objective to assist in a way that is consistent with the objective (e.g., navigating left or right around an obstacle). To address this challenge, we present Dream2Assist, a framework that combines a rich world model able to infer human objectives and value functions, and an assistive agent that provides appropriate expert assistance to a given human teammate. Our approach builds on a recurrent state space model to explicitly infer human intents, enabling the assistive agent to select actions that align with the human and enabling a fluid teaming interaction. We demonstrate our approach in a high-speed racing domain with a population of synthetic human drivers pursuing mutually exclusive objectives, such as "stay-behind" and "overtake". We show that the combined human-robot team, when blending its actions with those of the human, outperforms the synthetic humans alone as well as several baseline assistance strategies, and that intent-conditioning enables adherence to human preferences during task execution, leading to improved performance while satisfying the human's objective.
Computational Teaching for Driving via Multi-Task Imitation Learning
Oct 02, 2024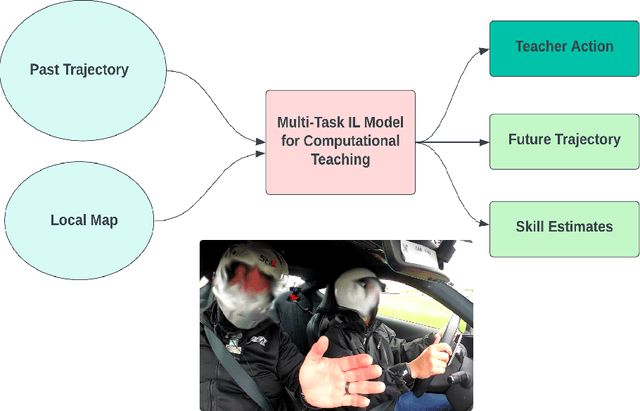
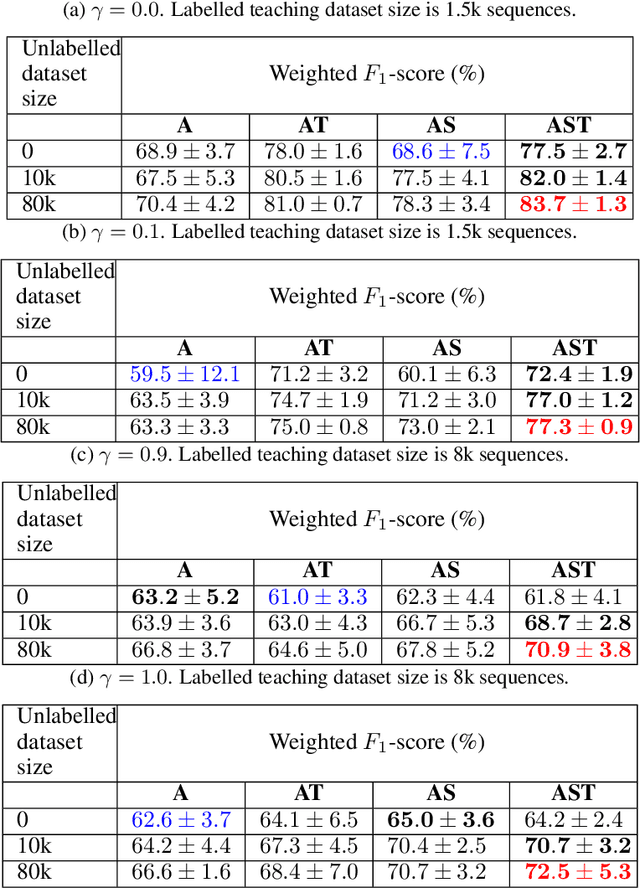
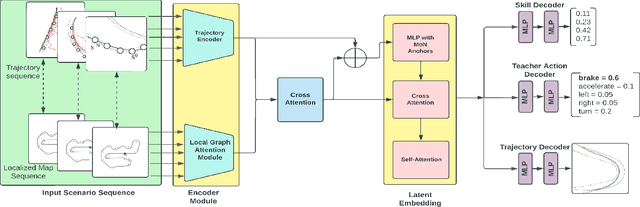
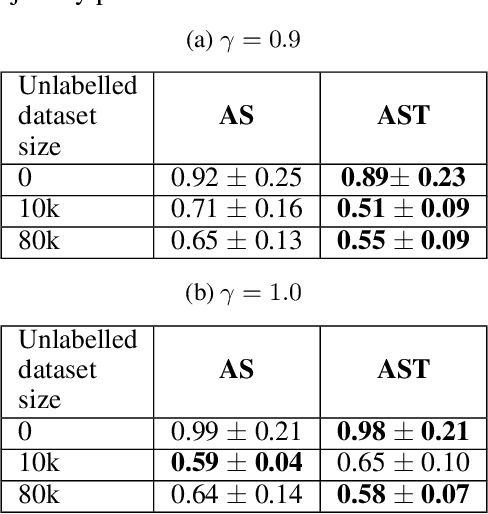
Learning motor skills for sports or performance driving is often done with professional instruction from expert human teachers, whose availability is limited. Our goal is to enable automated teaching via a learned model that interacts with the student similar to a human teacher. However, training such automated teaching systems is limited by the availability of high-quality annotated datasets of expert teacher and student interactions that are difficult to collect at scale. To address this data scarcity problem, we propose an approach for training a coaching system for complex motor tasks such as high performance driving via a Multi-Task Imitation Learning (MTIL) paradigm. MTIL allows our model to learn robust representations by utilizing self-supervised training signals from more readily available non-interactive datasets of humans performing the task of interest. We validate our approach with (1) a semi-synthetic dataset created from real human driving trajectories, (2) a professional track driving instruction dataset, (3) a track-racing driving simulator human-subject study, and (4) a system demonstration on an instrumented car at a race track. Our experiments show that the right set of auxiliary machine learning tasks improves performance in predicting teaching instructions. Moreover, in the human subjects study, students exposed to the instructions from our teaching system improve their ability to stay within track limits, and show favorable perception of the model's interaction with them, in terms of usefulness and satisfaction.
Think Deep and Fast: Learning Neural Nonlinear Opinion Dynamics from Inverse Dynamic Games for Split-Second Interactions
Jun 14, 2024



Non-cooperative interactions commonly occur in multi-agent scenarios such as car racing, where an ego vehicle can choose to overtake the rival, or stay behind it until a safe overtaking "corridor" opens. While an expert human can do well at making such time-sensitive decisions, the development of safe and efficient game-theoretic trajectory planners capable of rapidly reasoning discrete options is yet to be fully addressed. The recently developed nonlinear opinion dynamics (NOD) show promise in enabling fast opinion formation and avoiding safety-critical deadlocks. However, it remains an open challenge to determine the model parameters of NOD automatically and adaptively, accounting for the ever-changing environment of interaction. In this work, we propose for the first time a learning-based, game-theoretic approach to synthesize a Neural NOD model from expert demonstrations, given as a dataset containing (possibly incomplete) state and action trajectories of interacting agents. The learned NOD can be used by existing dynamic game solvers to plan decisively while accounting for the predicted change of other agents' intents, thus enabling situational awareness in planning. We demonstrate Neural NOD's ability to make fast and robust decisions in a simulated autonomous racing example, leading to tangible improvements in safety and overtaking performance over state-of-the-art data-driven game-theoretic planning methods.
Blending Data-Driven Priors in Dynamic Games
Feb 23, 2024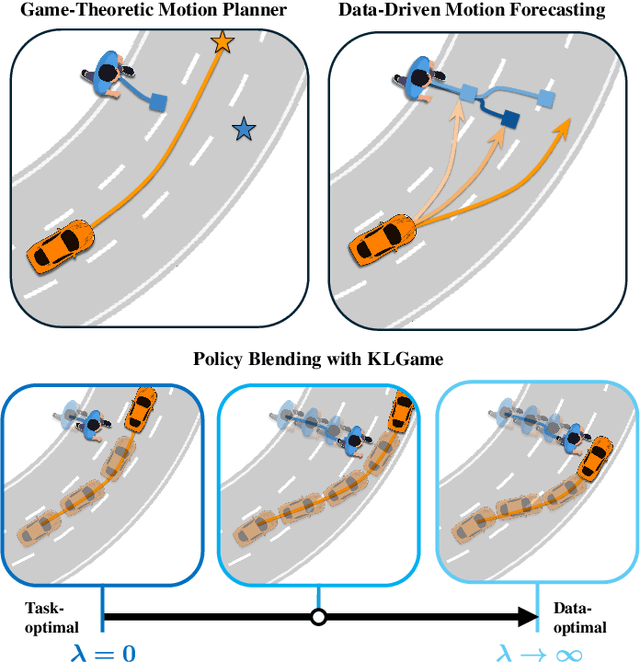
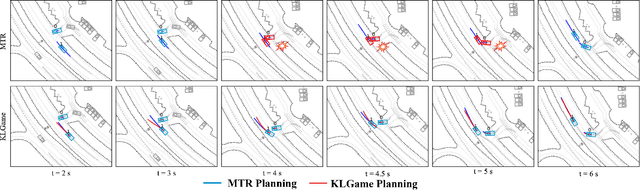
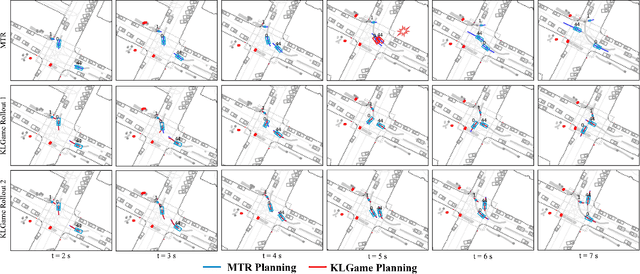
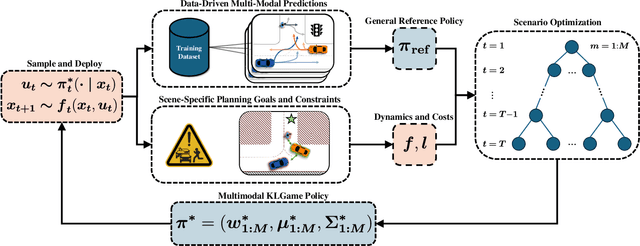
As intelligent robots like autonomous vehicles become increasingly deployed in the presence of people, the extent to which these systems should leverage model-based game-theoretic planners versus data-driven policies for safe, interaction-aware motion planning remains an open question. Existing dynamic game formulations assume all agents are task-driven and behave optimally. However, in reality, humans tend to deviate from the decisions prescribed by these models, and their behavior is better approximated under a noisy-rational paradigm. In this work, we investigate a principled methodology to blend a data-driven reference policy with an optimization-based game-theoretic policy. We formulate KLGame, a type of non-cooperative dynamic game with Kullback-Leibler (KL) regularization with respect to a general, stochastic, and possibly multi-modal reference policy. Our method incorporates, for each decision maker, a tunable parameter that permits modulation between task-driven and data-driven behaviors. We propose an efficient algorithm for computing multimodal approximate feedback Nash equilibrium strategies of KLGame in real time. Through a series of simulated and real-world autonomous driving scenarios, we demonstrate that KLGame policies can more effectively incorporate guidance from the reference policy and account for noisily-rational human behaviors versus non-regularized baselines.