 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLAMP: Data-Efficient Linear Affine Weight-Space Models for Parameter-Controlled 3D Shape Generation and Extrapolation
Oct 26, 2025Generating high-fidelity 3D geometries that satisfy specific parameter constraints has broad applications in design and engineering. However, current methods typically rely on large training datasets and struggle with controllability and generalization beyond the training distributions. To overcome these limitations, we introduce LAMP (Linear Affine Mixing of Parametric shapes), a data-efficient framework for controllable and interpretable 3D generation. LAMP first aligns signed distance function (SDF) decoders by overfitting each exemplar from a shared initialization, then synthesizes new geometries by solving a parameter-constrained mixing problem in the aligned weight space. To ensure robustness, we further propose a safety metric that detects geometry validity via linearity mismatch. We evaluate LAMP on two 3D parametric benchmarks: DrivAerNet++ and BlendedNet. We found that LAMP enables (i) controlled interpolation within bounds with as few as 100 samples, (ii) safe extrapolation by up to 100% parameter difference beyond training ranges, (iii) physics performance-guided optimization under fixed parameters. LAMP significantly outperforms conditional autoencoder and Deep Network Interpolation (DNI) baselines in both extrapolation and data efficiency. Our results demonstrate that LAMP advances controllable, data-efficient, and safe 3D generation for design exploration, dataset generation, and performance-driven optimization.
ShaLa: Multimodal Shared Latent Space Modelling
Aug 24, 2025This paper presents a novel generative framework for learning shared latent representations across multimodal data. Many advanced multimodal methods focus on capturing all combinations of modality-specific details across inputs, which can inadvertently obscure the high-level semantic concepts that are shared across modalities. Notably, Multimodal VAEs with low-dimensional latent variables are designed to capture shared representations, enabling various tasks such as joint multimodal synthesis and cross-modal inference. However, multimodal VAEs often struggle to design expressive joint variational posteriors and suffer from low-quality synthesis. In this work, ShaLa addresses these challenges by integrating a novel architectural inference model and a second-stage expressive diffusion prior, which not only facilitates effective inference of shared latent representation but also significantly improves the quality of downstream multimodal synthesis. We validate ShaLa extensively across multiple benchmarks, demonstrating superior coherence and synthesis quality compared to state-of-the-art multimodal VAEs. Furthermore, ShaLa scales to many more modalities while prior multimodal VAEs have fallen short in capturing the increasing complexity of the shared latent space.
Learning to Represent Individual Differences for Choice Decision Making
Mar 27, 2025Human decision making can be challenging to predict because decisions are affected by a number of complex factors. Adding to this complexity, decision-making processes can differ considerably between individuals, and methods aimed at predicting human decisions need to take individual differences into account. Behavioral science offers methods by which to measure individual differences (e.g., questionnaires, behavioral models), but these are often narrowed down to low dimensions and not tailored to specific prediction tasks. This paper investigates the use of representation learning to measure individual differences from behavioral experiment data. Representation learning offers a flexible approach to create individual embeddings from data that are both structured (e.g., demographic information) and unstructured (e.g., free text), where the flexibility provides more options for individual difference measures for personalization, e.g., free text responses may allow for open-ended questions that are less privacy-sensitive. In the current paper we use representation learning to characterize individual differences in human performance on an economic decision-making task. We demonstrate that models using representation learning to capture individual differences consistently improve decision predictions over models without representation learning, and even outperform well-known theory-based behavioral models used in these environments. Our results propose that representation learning offers a useful and flexible tool to capture individual differences.
Att-Adapter: A Robust and Precise Domain-Specific Multi-Attributes T2I Diffusion Adapter via Conditional Variational Autoencoder
Mar 15, 2025

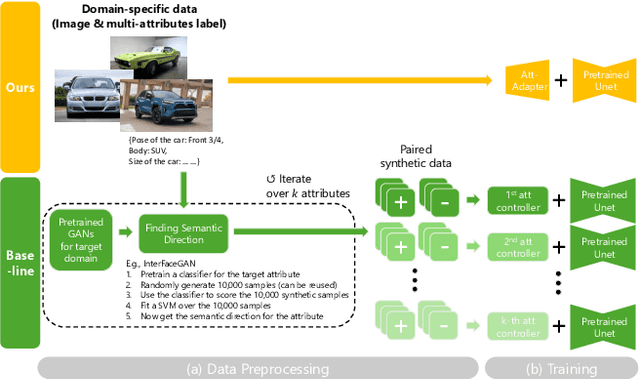

Text-to-Image (T2I) Diffusion Models have achieved remarkable performance in generating high quality images. However, enabling precise control of continuous attributes, especially multiple attributes simultaneously, in a new domain (e.g., numeric values like eye openness or car width) with text-only guidance remains a significant challenge. To address this, we introduce the Attribute (Att) Adapter, a novel plug-and-play module designed to enable fine-grained, multi-attributes control in pretrained diffusion models. Our approach learns a single control adapter from a set of sample images that can be unpaired and contain multiple visual attributes. The Att-Adapter leverages the decoupled cross attention module to naturally harmonize the multiple domain attributes with text conditioning. We further introduce Conditional Variational Autoencoder (CVAE) to the Att-Adapter to mitigate overfitting, matching the diverse nature of the visual world. Evaluations on two public datasets show that Att-Adapter outperforms all LoRA-based baselines in controlling continuous attributes. Additionally, our method enables a broader control range and also improves disentanglement across multiple attributes, surpassing StyleGAN-based techniques. Notably, Att-Adapter is flexible, requiring no paired synthetic data for training, and is easily scalable to multiple attributes within a single model.
Parametric-ControlNet: Multimodal Control in Foundation Models for Precise Engineering Design Synthesis
Dec 06, 2024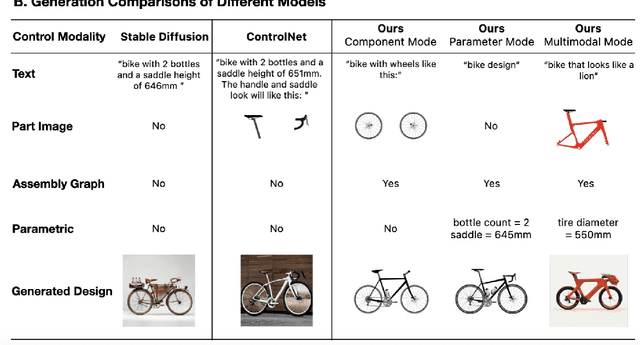

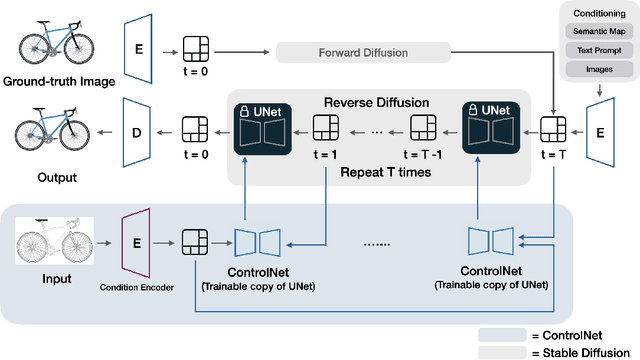
This paper introduces a generative model designed for multimodal control over text-to-image foundation generative AI models such as Stable Diffusion, specifically tailored for engineering design synthesis. Our model proposes parametric, image, and text control modalities to enhance design precision and diversity. Firstly, it handles both partial and complete parametric inputs using a diffusion model that acts as a design autocomplete co-pilot, coupled with a parametric encoder to process the information. Secondly, the model utilizes assembly graphs to systematically assemble input component images, which are then processed through a component encoder to capture essential visual data. Thirdly, textual descriptions are integrated via CLIP encoding, ensuring a comprehensive interpretation of design intent. These diverse inputs are synthesized through a multimodal fusion technique, creating a joint embedding that acts as the input to a module inspired by ControlNet. This integration allows the model to apply robust multimodal control to foundation models, facilitating the generation of complex and precise engineering designs. This approach broadens the capabilities of AI-driven design tools and demonstrates significant advancements in precise control based on diverse data modalities for enhanced design generation.
Bridging Design Gaps: A Parametric Data Completion Approach With Graph Guided Diffusion Models
Jun 17, 2024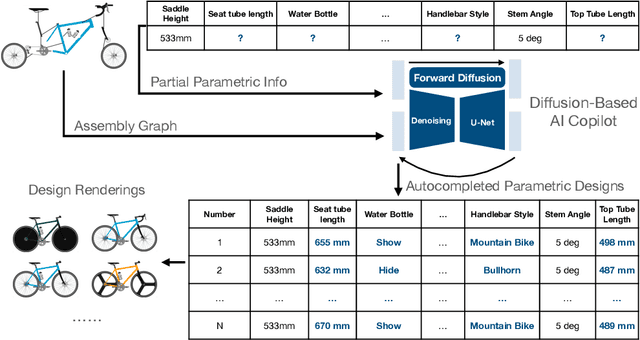

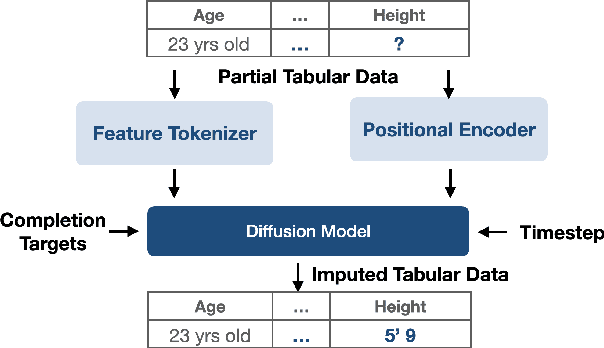
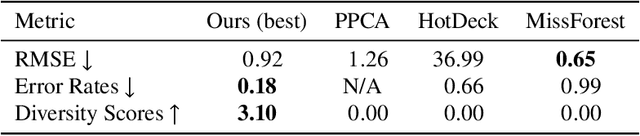
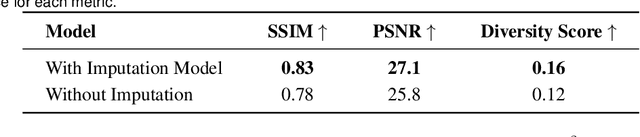
This study introduces a generative imputation model leveraging graph attention networks and tabular diffusion models for completing missing parametric data in engineering designs. This model functions as an AI design co-pilot, providing multiple design options for incomplete designs, which we demonstrate using the bicycle design CAD dataset. Through comparative evaluations, we demonstrate that our model significantly outperforms existing classical methods, such as MissForest, hotDeck, PPCA, and tabular generative method TabCSDI in both the accuracy and diversity of imputation options. Generative modeling also enables a broader exploration of design possibilities, thereby enhancing design decision-making by allowing engineers to explore a variety of design completions. The graph model combines GNNs with the structural information contained in assembly graphs, enabling the model to understand and predict the complex interdependencies between different design parameters. The graph model helps accurately capture and impute complex parametric interdependencies from an assembly graph, which is key for design problems. By learning from an existing dataset of designs, the imputation capability allows the model to act as an intelligent assistant that autocompletes CAD designs based on user-defined partial parametric design, effectively bridging the gap between ideation and realization. The proposed work provides a pathway to not only facilitate informed design decisions but also promote creative exploration in design.
GAME-UP: Game-Aware Mode Enumeration and Understanding for Trajectory Prediction
May 28, 2023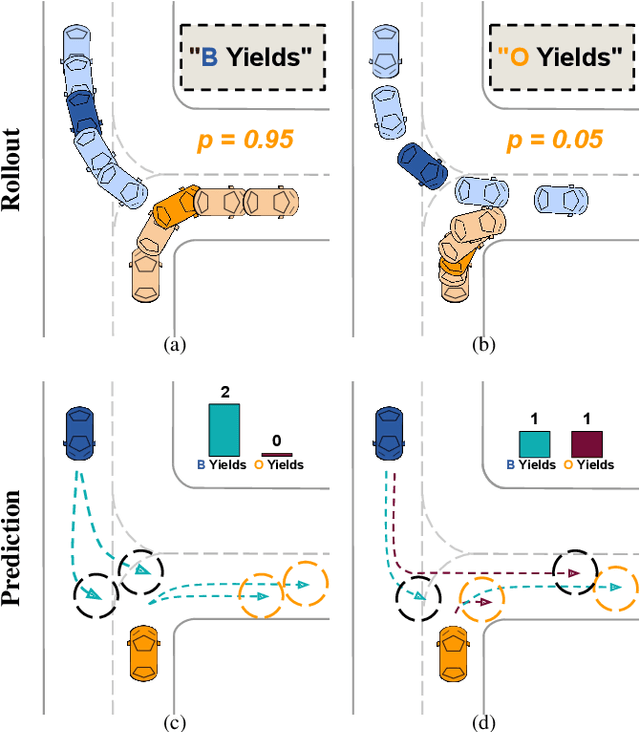

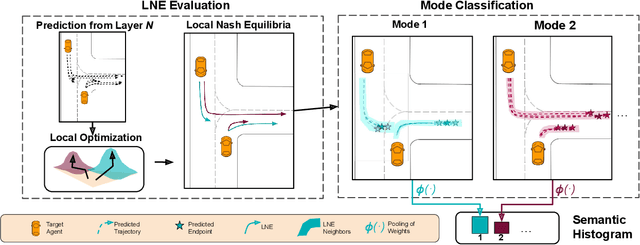
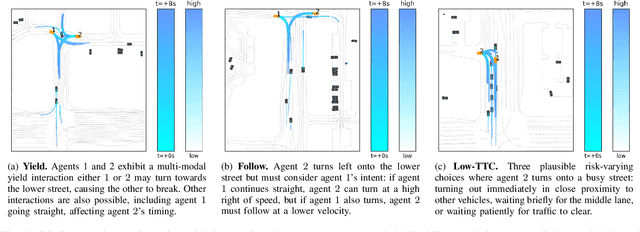
Interactions between road agents present a significant challenge in trajectory prediction, especially in cases involving multiple agents. Because existing diversity-aware predictors do not account for the interactive nature of multi-agent predictions, they may miss these important interaction outcomes. In this paper, we propose GAME-UP, a framework for trajectory prediction that leverages game-theoretic inverse reinforcement learning to improve coverage of multi-modal predictions. We use a training-time game-theoretic numerical analysis as an auxiliary loss resulting in improved coverage and accuracy without presuming a taxonomy of actions for the agents. We demonstrate our approach on the interactive subset of Waymo Open Motion Dataset, including three subsets involving scenarios with high interaction complexity. Experiment results show that our predictor produces accurate predictions while covering twice as many possible interactions versus a baseline model.
Accelerating Understanding of Scientific Experiments with End to End Symbolic Regression
Dec 07, 2021
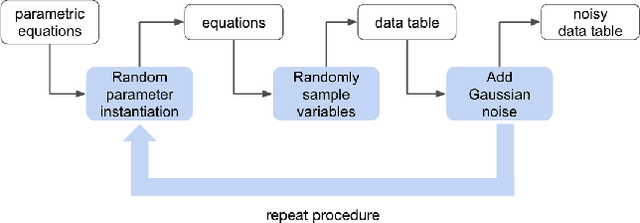
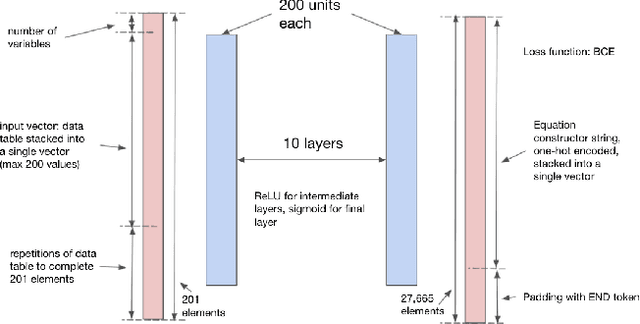
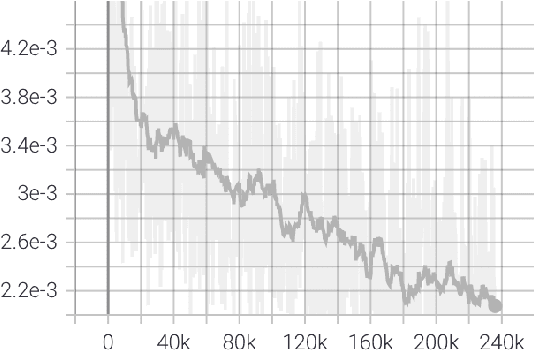
We consider the problem of learning free-form symbolic expressions from raw data, such as that produced by an experiment in any scientific domain. Accurate and interpretable models of scientific phenomena are the cornerstone of scientific research. Simple yet interpretable models, such as linear or logistic regression and decision trees often lack predictive accuracy. Alternatively, accurate blackbox models such as deep neural networks provide high predictive accuracy, but do not readily admit human understanding in a way that would enrich the scientific theory of the phenomenon. Many great breakthroughs in science revolve around the development of parsimonious equational models with high predictive accuracy, such as Newton's laws, universal gravitation, and Maxwell's equations. Previous work on automating the search of equational models from data combine domain-specific heuristics as well as computationally expensive techniques, such as genetic programming and Monte-Carlo search. We develop a deep neural network (MACSYMA) to address the symbolic regression problem as an end-to-end supervised learning problem. MACSYMA can generate symbolic expressions that describe a dataset. The computational complexity of the task is reduced to the feedforward computation of a neural network. We train our neural network on a synthetic dataset consisting of data tables of varying length and varying levels of noise, for which the neural network must learn to produce the correct symbolic expression token by token. Finally, we validate our technique by running on a public dataset from behavioral science.
Using Sensory Time-cue to enable Unsupervised Multimodal Meta-learning
Sep 16, 2020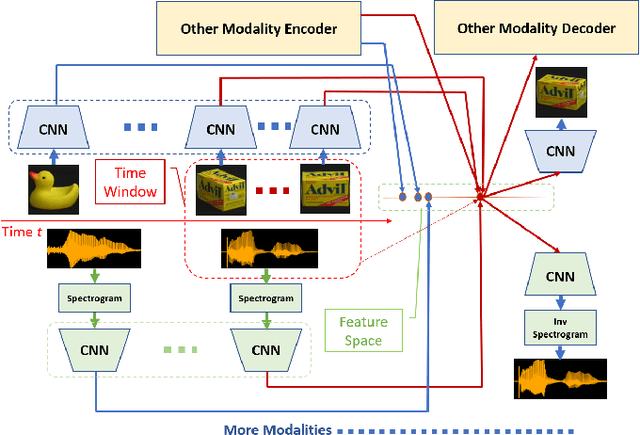
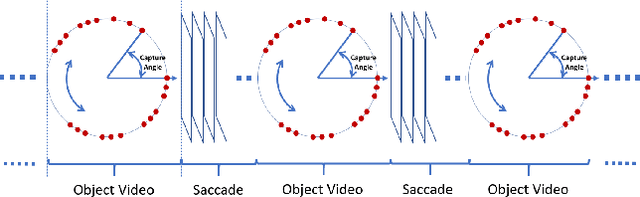
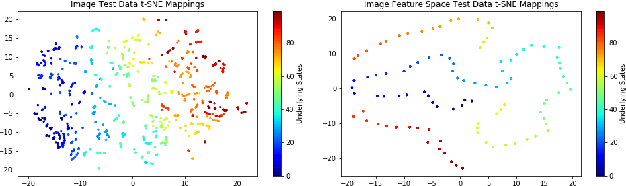
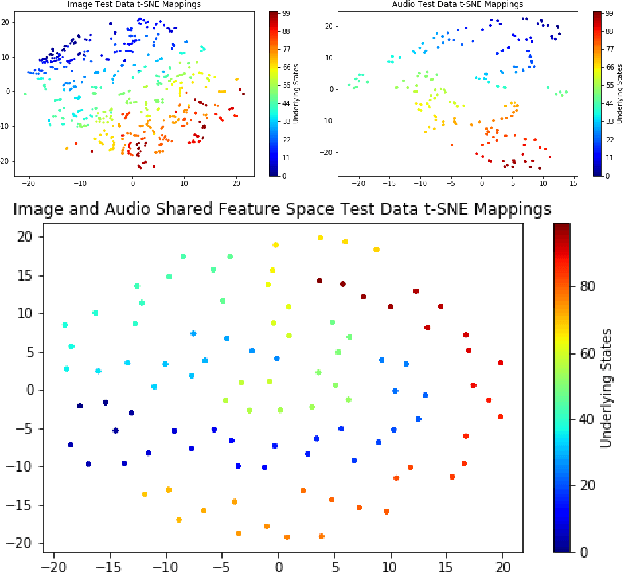
As data from IoT (Internet of Things) sensors become ubiquitous, state-of-the-art machine learning algorithms face many challenges on directly using sensor data. To overcome these challenges, methods must be designed to learn directly from sensors without manual annotations. This paper introduces Sensory Time-cue for Unsupervised Meta-learning (STUM). Different from traditional learning approaches that either heavily depend on labels or on time-independent feature extraction assumptions, such as Gaussian distribution features, the STUM system uses time relation of inputs to guide the feature space formation within and across modalities. The fact that STUM learns from a variety of small tasks may put this method in the camp of Meta-Learning. Different from existing Meta-Learning approaches, STUM learning tasks are composed within and across multiple modalities based on time-cue co-exist with the IoT streaming data. In an audiovisual learning example, because consecutive visual frames usually comprise the same object, this approach provides a unique way to organize features from the same object together. The same method can also organize visual object features with the object's spoken-name features together if the spoken name is presented with the object at about the same time. This cross-modality feature organization may further help the organization of visual features that belong to similar objects but acquired at different location and time. Promising results are achieved through evaluations.