 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAtt-Adapter: A Robust and Precise Domain-Specific Multi-Attributes T2I Diffusion Adapter via Conditional Variational Autoencoder
Mar 15, 2025

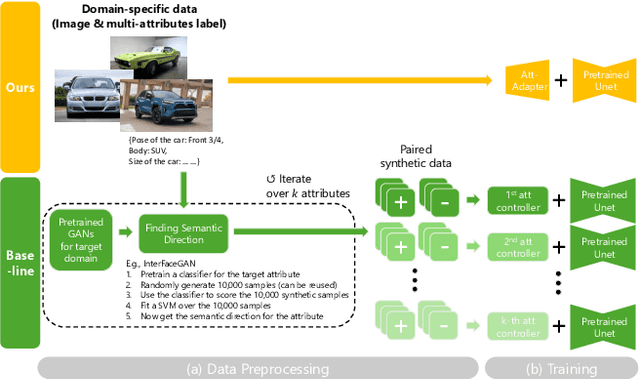

Text-to-Image (T2I) Diffusion Models have achieved remarkable performance in generating high quality images. However, enabling precise control of continuous attributes, especially multiple attributes simultaneously, in a new domain (e.g., numeric values like eye openness or car width) with text-only guidance remains a significant challenge. To address this, we introduce the Attribute (Att) Adapter, a novel plug-and-play module designed to enable fine-grained, multi-attributes control in pretrained diffusion models. Our approach learns a single control adapter from a set of sample images that can be unpaired and contain multiple visual attributes. The Att-Adapter leverages the decoupled cross attention module to naturally harmonize the multiple domain attributes with text conditioning. We further introduce Conditional Variational Autoencoder (CVAE) to the Att-Adapter to mitigate overfitting, matching the diverse nature of the visual world. Evaluations on two public datasets show that Att-Adapter outperforms all LoRA-based baselines in controlling continuous attributes. Additionally, our method enables a broader control range and also improves disentanglement across multiple attributes, surpassing StyleGAN-based techniques. Notably, Att-Adapter is flexible, requiring no paired synthetic data for training, and is easily scalable to multiple attributes within a single model.
Towards Enhanced Controllability of Diffusion Models
Mar 15, 2023Denoising Diffusion models have shown remarkable capabilities in generating realistic, high-quality and diverse images. However, the extent of controllability during generation is underexplored. Inspired by techniques based on GAN latent space for image manipulation, we train a diffusion model conditioned on two latent codes, a spatial content mask and a flattened style embedding. We rely on the inductive bias of the progressive denoising process of diffusion models to encode pose/layout information in the spatial structure mask and semantic/style information in the style code. We propose two generic sampling techniques for improving controllability. We extend composable diffusion models to allow for some dependence between conditional inputs, to improve the quality of generations while also providing control over the amount of guidance from each latent code and their joint distribution. We also propose timestep dependent weight scheduling for content and style latents to further improve the translations. We observe better controllability compared to existing methods and show that without explicit training objectives, diffusion models can be used for effective image manipulation and image translation.
Cooperative Distribution Alignment via JSD Upper Bound
Jul 05, 2022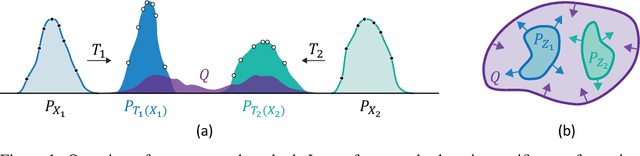

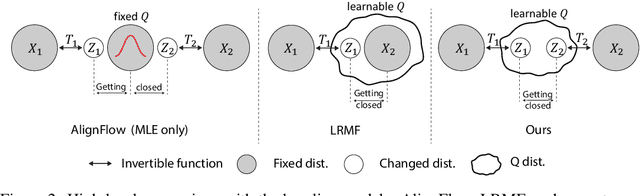
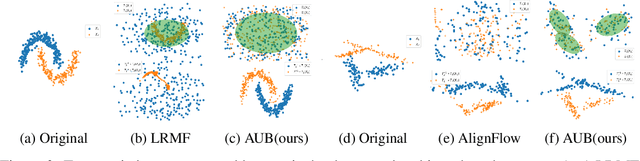
Unsupervised distribution alignment estimates a transformation that maps two or more source distributions to a shared aligned distribution given only samples from each distribution. This task has many applications including generative modeling, unsupervised domain adaptation, and socially aware learning. Most prior works use adversarial learning (i.e., min-max optimization), which can be challenging to optimize and evaluate. A few recent works explore non-adversarial flow-based (i.e., invertible) approaches, but they lack a unified perspective and are limited in efficiently aligning multiple distributions. Therefore, we propose to unify and generalize previous flow-based approaches under a single non-adversarial framework, which we prove is equivalent to minimizing an upper bound on the Jensen-Shannon Divergence (JSD). Importantly, our problem reduces to a min-min, i.e., cooperative, problem and can provide a natural evaluation metric for unsupervised distribution alignment. We present empirical results of our framework on both simulated and real-world datasets to demonstrate the benefits of our approach.
Enhanced 3DMM Attribute Control via Synthetic Dataset Creation Pipeline
Dec 11, 2020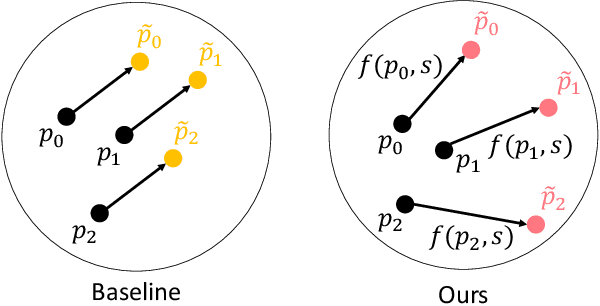

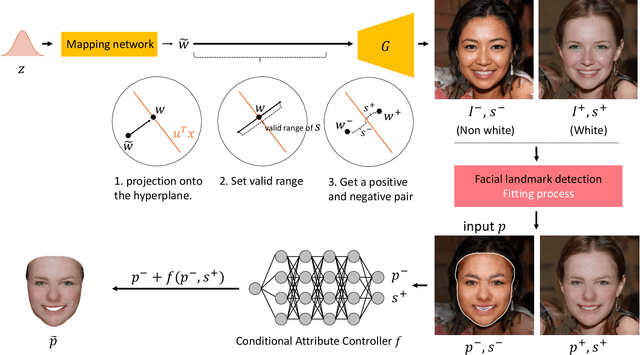

While facial attribute manipulation of 2D images via Generative Adversarial Networks (GANs) has become common in computer vision and graphics due to its many practical uses, research on 3D attribute manipulation is relatively undeveloped. Existing 3D attribute manipulation methods are limited because the same semantic changes are applied to every 3D face. The key challenge for developing better 3D attribute control methods is the lack of paired training data in which one attribute is changed while other attributes are held fixed -- e.g., a pair of 3D faces where one is male and the other is female but all other attributes, such as race and expression, are the same. To overcome this challenge, we design a novel pipeline for generating paired 3D faces by harnessing the power of GANs. On top of this pipeline, we then propose an enhanced non-linear 3D conditional attribute controller that increases the precision and diversity of 3D attribute control compared to existing methods. We demonstrate the validity of our dataset creation pipeline and the superior performance of our conditional attribute controller via quantitative and qualitative evaluations.
StyleUV: Diverse and High-fidelity UV Map Generative Model
Nov 25, 2020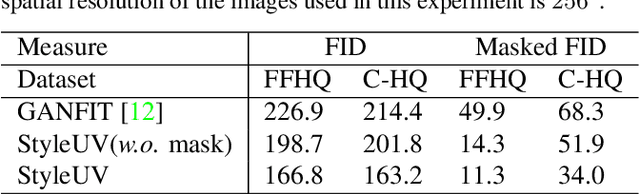
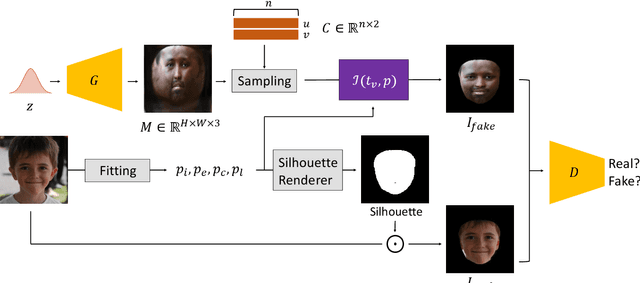


Reconstructing 3D human faces in the wild with the 3D Morphable Model (3DMM) has become popular in recent years. While most prior work focuses on estimating more robust and accurate geometry, relatively little attention has been paid to improving the quality of the texture model. Meanwhile, with the advent of Generative Adversarial Networks (GANs), there has been great progress in reconstructing realistic 2D images. Recent work demonstrates that GANs trained with abundant high-quality UV maps can produce high-fidelity textures superior to those produced by existing methods. However, acquiring such high-quality UV maps is difficult because they are expensive to acquire, requiring laborious processes to refine. In this work, we present a novel UV map generative model that learns to generate diverse and realistic synthetic UV maps without requiring high-quality UV maps for training. Our proposed framework can be trained solely with in-the-wild images (i.e., UV maps are not required) by leveraging a combination of GANs and a differentiable renderer. Both quantitative and qualitative evaluations demonstrate that our proposed texture model produces more diverse and higher fidelity textures compared to existing methods.
Unpaired Image Translation via Adaptive Convolution-based Normalization
Nov 29, 2019

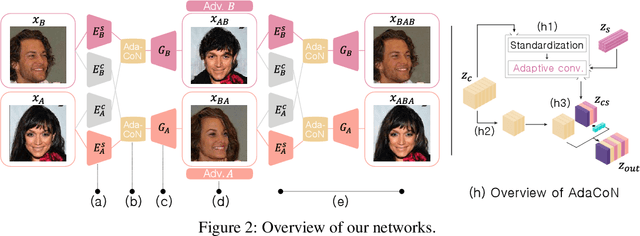
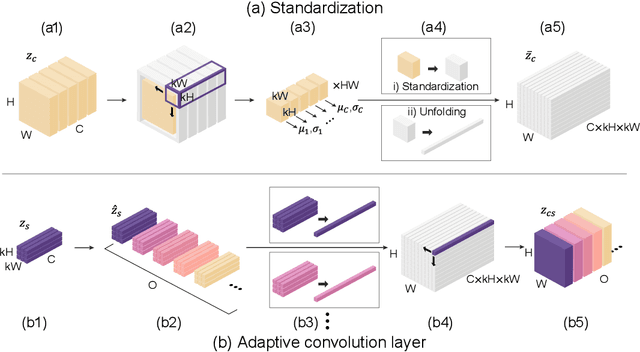
Disentangling content and style information of an image has played an important role in recent success in image translation. In this setting, how to inject given style into an input image containing its own content is an important issue, but existing methods followed relatively simple approaches, leaving room for improvement especially when incorporating significant style changes. In response, we propose an advanced normalization technique based on adaptive convolution (AdaCoN), in order to properly impose style information into the content of an input image. In detail, after locally standardizing the content representation in a channel-wise manner, AdaCoN performs adaptive convolution where the convolution filter weights are dynamically estimated using the encoded style representation. The flexibility of AdaCoN can handle complicated image translation tasks involving significant style changes. Our qualitative and quantitative experiments demonstrate the superiority of our proposed method against various existing approaches that inject the style into the content.
What and Where to Translate: Local Mask-based Image-to-Image Translation
Jun 09, 2019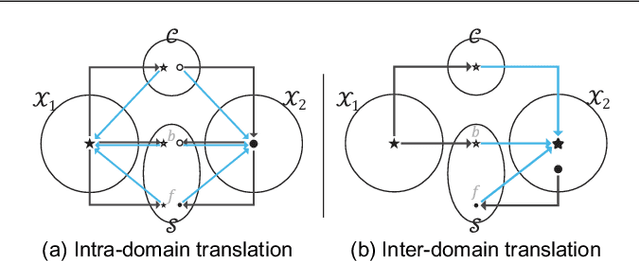
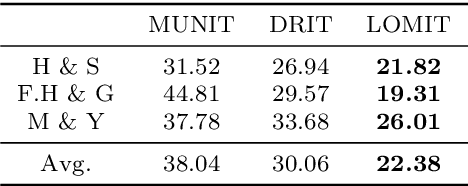
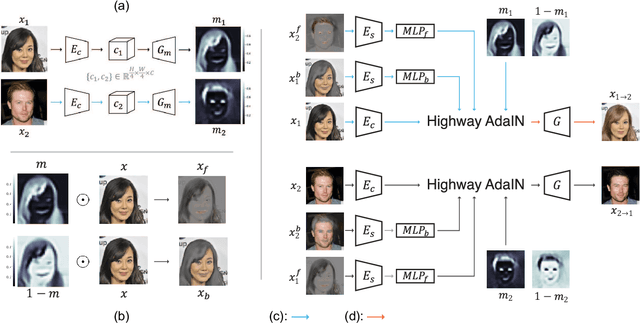

Recently, image-to-image translation has obtained significant attention. Among many, those approaches based on an exemplar image that contains the target style information has been actively studied, due to its capability to handle multimodality as well as its applicability in practical use. However, two intrinsic problems exist in the existing methods: what and where to transfer. First, those methods extract style from an entire exemplar which includes noisy information, which impedes a translation model from properly extracting the intended style of the exemplar. That is, we need to carefully determine what to transfer from the exemplar. Second, the extracted style is applied to the entire input image, which causes unnecessary distortion in irrelevant image regions. In response, we need to decide where to transfer the extracted style. In this paper, we propose a novel approach that extracts out a local mask from the exemplar that determines what style to transfer, and another local mask from the input image that determines where to transfer the extracted style. The main novelty of this paper lies in (1) the highway adaptive instance normalization technique and (2) an end-to-end translation framework which achieves an outstanding performance in reflecting a style of an exemplar. We demonstrate the quantitative and qualitative evaluation results to confirm the advantages of our proposed approach.
Image-to-Image Translation via Group-wise Deep Whitening and Coloring Transformation
Dec 24, 2018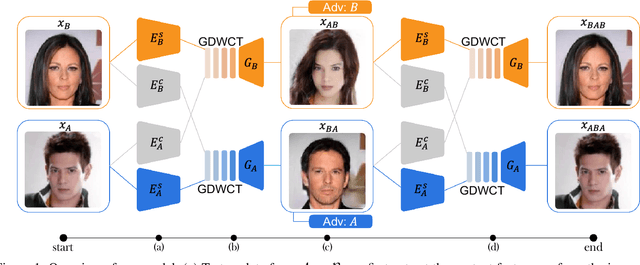
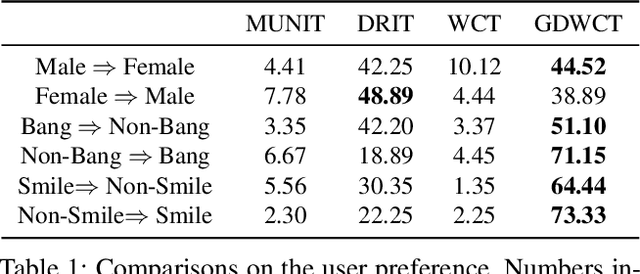
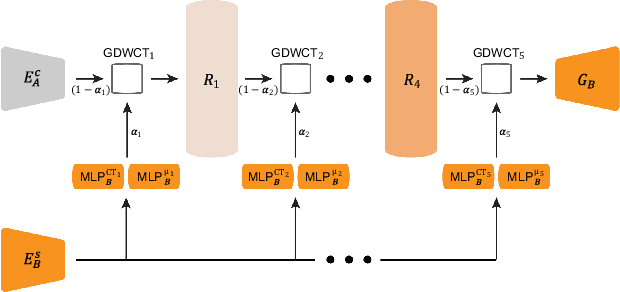
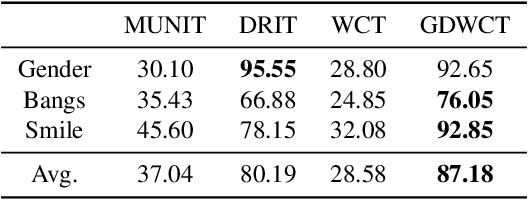
Unsupervised image translation is an active area powered by the advanced generative adversarial networks. Recently introduced models, such as DRIT or MUNIT, utilize a separate encoder in extracting the content and the style of image to successfully incorporate the multimodal nature of image translation. The existing methods, however, overlooks the role that the correlation between feature pairs plays in the overall style. The correlation between feature pairs on top of the mean and the variance of features, are important statistics that define the style of an image. In this regard, we propose an end-to-end framework tailored for image translation that leverages the covariance statistics by whitening the content of an input image followed by coloring to match the covariance statistics with an exemplar. The proposed group-wise deep whitening and coloring (GDWTC) algorithm is motivated by an earlier work of whitening and coloring transformation (WTC), but is augmented to be trained in an end-to-end manner, and with largely reduced computation costs. Our extensive qualitative and quantitative experiments demonstrate that the proposed GDWTC is fast, both in training and inference, and highly effective in reflecting the style of an exemplar.
Coloring with Words: Guiding Image Colorization Through Text-based Palette Generation
Aug 07, 2018
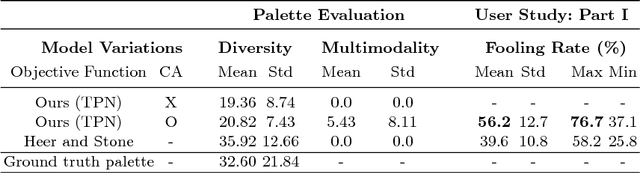


This paper proposes a novel approach to generate multiple color palettes that reflect the semantics of input text and then colorize a given grayscale image according to the generated color palette. In contrast to existing approaches, our model can understand rich text, whether it is a single word, a phrase, or a sentence, and generate multiple possible palettes from it. For this task, we introduce our manually curated dataset called Palette-and-Text (PAT). Our proposed model called Text2Colors consists of two conditional generative adversarial networks: the text-to-palette generation networks and the palette-based colorization networks. The former captures the semantics of the text input and produce relevant color palettes. The latter colorizes a grayscale image using the generated color palette. Our evaluation results show that people preferred our generated palettes over ground truth palettes and that our model can effectively reflect the given palette when colorizing an image.
* 25 pages, 22 figures