 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOPRO: Orthogonal Panel-Relative Operators for Panel-Aware In-Context Image Generation
Mar 29, 2026We introduce a parameter-efficient adaptation method for panel-aware in-context image generation with pre-trained diffusion transformers. The key idea is to compose learnable, panel-specific orthogonal operators onto the backbone's frozen positional encodings. This design provides two desirable properties: (1) isometry, which preserves the geometry of internal features, and (2) same-panel invariance, which maintains the model's pre-trained intra-panel synthesis behavior. Through controlled experiments, we demonstrate that the effectiveness of our adaptation method is not tied to a specific positional encoding design but generalizes across diverse positional encoding regimes. By enabling effective panel-relative conditioning, the proposed method consistently improves in-context image-based instructional editing pipelines, including state-of-the-art approaches.
Training Spatial-Frequency Visual Prompts and Probabilistic Clusters for Accurate Black-Box Transfer Learning
Aug 15, 2024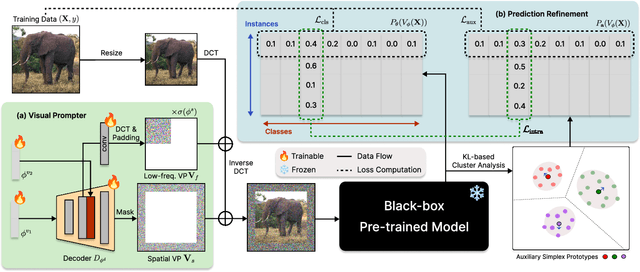
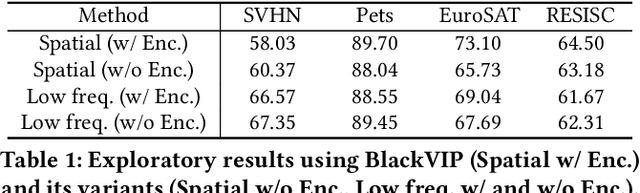


Despite the growing prevalence of black-box pre-trained models (PTMs) such as prediction API services, there remains a significant challenge in directly applying general models to real-world scenarios due to the data distribution gap. Considering a data deficiency and constrained computational resource scenario, this paper proposes a novel parameter-efficient transfer learning framework for vision recognition models in the black-box setting. Our framework incorporates two novel training techniques. First, we align the input space (i.e., image) of PTMs to the target data distribution by generating visual prompts of spatial and frequency domain. Along with the novel spatial-frequency hybrid visual prompter, we design a novel training technique based on probabilistic clusters, which can enhance class separation in the output space (i.e., prediction probabilities). In experiments, our model demonstrates superior performance in a few-shot transfer learning setting across extensive visual recognition datasets, surpassing state-of-the-art baselines. Additionally, we show that the proposed method efficiently reduces computational costs for training and inference phases.
Layout-and-Retouch: A Dual-stage Framework for Improving Diversity in Personalized Image Generation
Jul 13, 2024
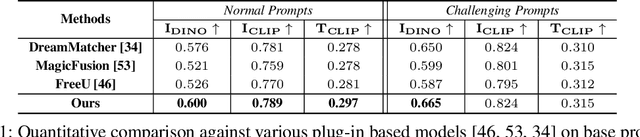
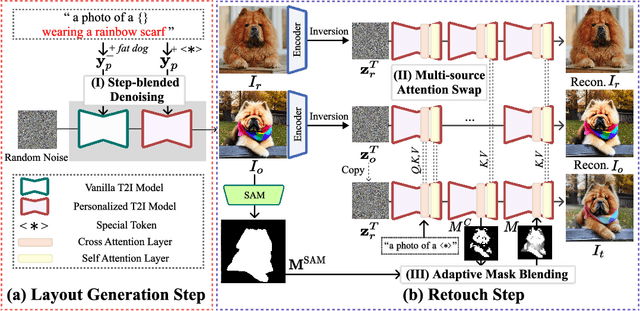
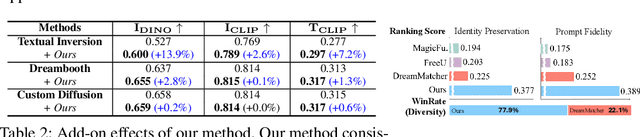
Personalized text-to-image (P-T2I) generation aims to create new, text-guided images featuring the personalized subject with a few reference images. However, balancing the trade-off relationship between prompt fidelity and identity preservation remains a critical challenge. To address the issue, we propose a novel P-T2I method called Layout-and-Retouch, consisting of two stages: 1) layout generation and 2) retouch. In the first stage, our step-blended inference utilizes the inherent sample diversity of vanilla T2I models to produce diversified layout images, while also enhancing prompt fidelity. In the second stage, multi-source attention swapping integrates the context image from the first stage with the reference image, leveraging the structure from the context image and extracting visual features from the reference image. This achieves high prompt fidelity while preserving identity characteristics. Through our extensive experiments, we demonstrate that our method generates a wide variety of images with diverse layouts while maintaining the unique identity features of the personalized objects, even with challenging text prompts. This versatility highlights the potential of our framework to handle complex conditions, significantly enhancing the diversity and applicability of personalized image synthesis.
iDet3D: Towards Efficient Interactive Object Detection for LiDAR Point Clouds
Dec 24, 2023



Accurately annotating multiple 3D objects in LiDAR scenes is laborious and challenging. While a few previous studies have attempted to leverage semi-automatic methods for cost-effective bounding box annotation, such methods have limitations in efficiently handling numerous multi-class objects. To effectively accelerate 3D annotation pipelines, we propose iDet3D, an efficient interactive 3D object detector. Supporting a user-friendly 2D interface, which can ease the cognitive burden of exploring 3D space to provide click interactions, iDet3D enables users to annotate the entire objects in each scene with minimal interactions. Taking the sparse nature of 3D point clouds into account, we design a negative click simulation (NCS) to improve accuracy by reducing false-positive predictions. In addition, iDet3D incorporates two click propagation techniques to take full advantage of user interactions: (1) dense click guidance (DCG) for keeping user-provided information throughout the network and (2) spatial click propagation (SCP) for detecting other instances of the same class based on the user-specified objects. Through our extensive experiments, we present that our method can construct precise annotations in a few clicks, which shows the practicality as an efficient annotation tool for 3D object detection.
Reference-based Image Composition with Sketch via Structure-aware Diffusion Model
Mar 31, 2023



Recent remarkable improvements in large-scale text-to-image generative models have shown promising results in generating high-fidelity images. To further enhance editability and enable fine-grained generation, we introduce a multi-input-conditioned image composition model that incorporates a sketch as a novel modal, alongside a reference image. Thanks to the edge-level controllability using sketches, our method enables a user to edit or complete an image sub-part with a desired structure (i.e., sketch) and content (i.e., reference image). Our framework fine-tunes a pre-trained diffusion model to complete missing regions using the reference image while maintaining sketch guidance. Albeit simple, this leads to wide opportunities to fulfill user needs for obtaining the in-demand images. Through extensive experiments, we demonstrate that our proposed method offers unique use cases for image manipulation, enabling user-driven modifications of arbitrary scenes.
Style Your Hair: Latent Optimization for Pose-Invariant Hairstyle Transfer via Local-Style-Aware Hair Alignment
Aug 16, 2022
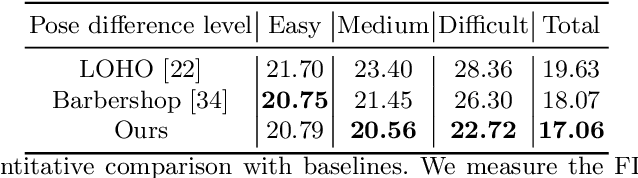
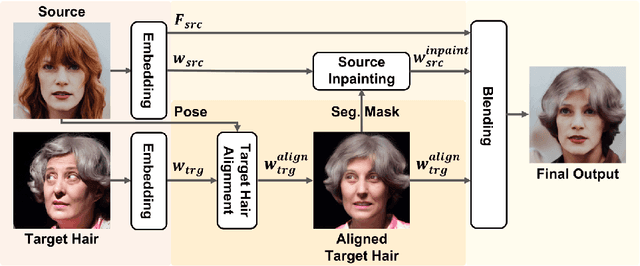

Editing hairstyle is unique and challenging due to the complexity and delicacy of hairstyle. Although recent approaches significantly improved the hair details, these models often produce undesirable outputs when a pose of a source image is considerably different from that of a target hair image, limiting their real-world applications. HairFIT, a pose-invariant hairstyle transfer model, alleviates this limitation yet still shows unsatisfactory quality in preserving delicate hair textures. To solve these limitations, we propose a high-performing pose-invariant hairstyle transfer model equipped with latent optimization and a newly presented local-style-matching loss. In the StyleGAN2 latent space, we first explore a pose-aligned latent code of a target hair with the detailed textures preserved based on local style matching. Then, our model inpaints the occlusions of the source considering the aligned target hair and blends both images to produce a final output. The experimental results demonstrate that our model has strengths in transferring a hairstyle under larger pose differences and preserving local hairstyle textures.
Continuous-Time Video Generation via Learning Motion Dynamics with Neural ODE
Dec 21, 2021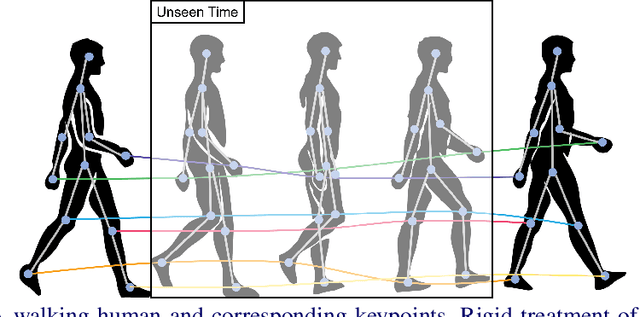
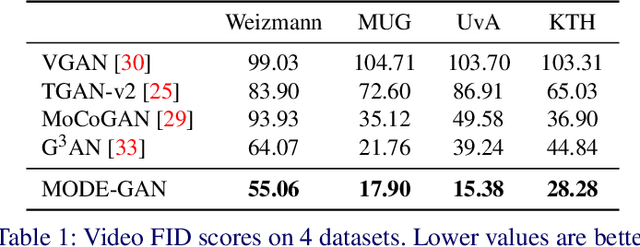
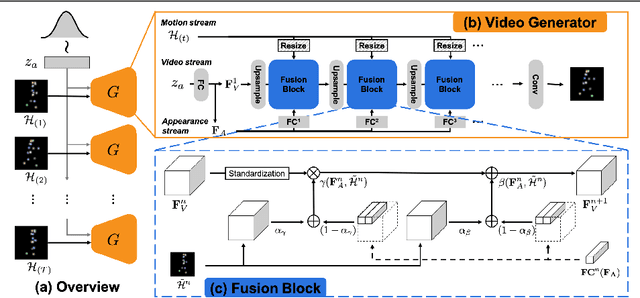

In order to perform unconditional video generation, we must learn the distribution of the real-world videos. In an effort to synthesize high-quality videos, various studies attempted to learn a mapping function between noise and videos, including recent efforts to separate motion distribution and appearance distribution. Previous methods, however, learn motion dynamics in discretized, fixed-interval timesteps, which is contrary to the continuous nature of motion of a physical body. In this paper, we propose a novel video generation approach that learns separate distributions for motion and appearance, the former modeled by neural ODE to learn natural motion dynamics. Specifically, we employ a two-stage approach where the first stage converts a noise vector to a sequence of keypoints in arbitrary frame rates, and the second stage synthesizes videos based on the given keypoints sequence and the appearance noise vector. Our model not only quantitatively outperforms recent baselines for video generation, but also demonstrates versatile functionality such as dynamic frame rate manipulation and motion transfer between two datasets, thus opening new doors to diverse video generation applications.
AnimeCeleb: Large-Scale Animation CelebFaces Dataset via Controllable 3D Synthetic Models
Nov 15, 2021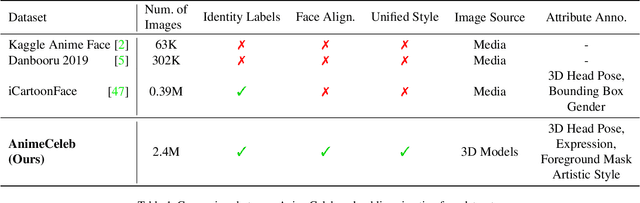
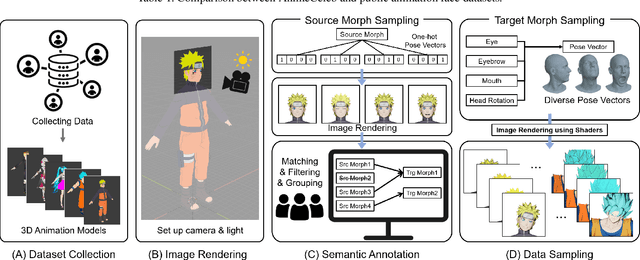
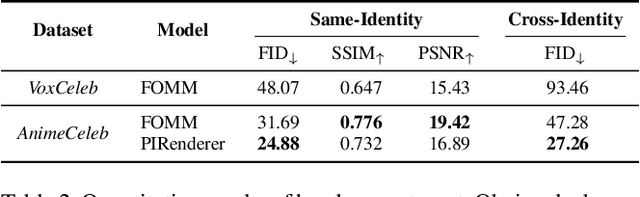

Despite remarkable success in deep learning-based face-related models, these models are still limited to the domain of real human faces. On the other hand, the domain of animation faces has been studied less intensively due to the absence of a well-organized dataset. In this paper, we present a large-scale animation celebfaces dataset (AnimeCeleb) via controllable synthetic animation models to boost research on the animation face domain. To facilitate the data generation process, we build a semi-automatic pipeline based on an open 3D software and a developed annotation system. This leads to constructing a large-scale animation face dataset that includes multi-pose and multi-style animation faces with rich annotations. Experiments suggest that our dataset is applicable to various animation-related tasks such as head reenactment and colorization.
Vid-ODE: Continuous-Time Video Generation with Neural Ordinary Differential Equation
Oct 16, 2020
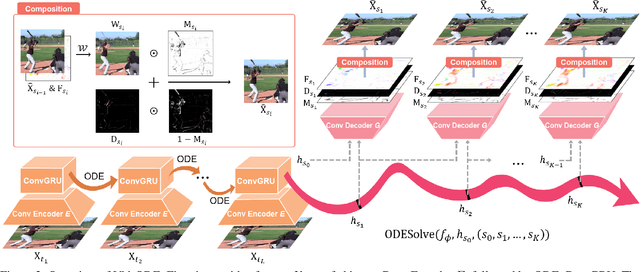
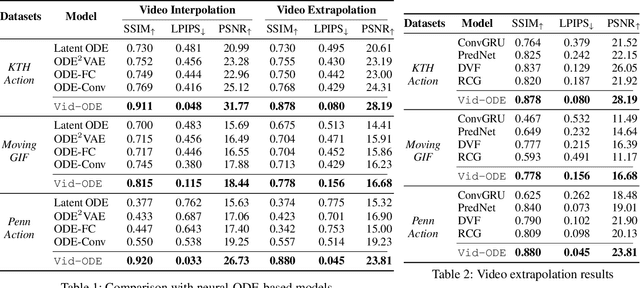

Video generation models often operate under the assumption of fixed frame rates, which leads to suboptimal performance when it comes to handling flexible frame rates (e.g., increasing the frame rate of more dynamic portion of the video as well as handling missing video frames). To resolve the restricted nature of existing video generation models' ability to handle arbitrary timesteps, we propose continuous-time video generation by combining neural ODE (Vid-ODE) with pixel-level video processing techniques. Using ODE-ConvGRU as an encoder, a convolutional version of the recently proposed neural ODE, which enables us to learn continuous-time dynamics, Vid-ODE can learn the spatio-temporal dynamics of input videos of flexible frame rates. The decoder integrates the learned dynamics function to synthesize video frames at any given timesteps, where the pixel-level composition technique is used to maintain the sharpness of individual frames. With extensive experiments on four real-world video datasets, we verify that the proposed Vid-ODE outperforms state-of-the-art approaches under various video generation settings, both within the trained time range (interpolation) and beyond the range (extrapolation). To the best of our knowledge, Vid-ODE is the first work successfully performing continuous-time video generation using real-world videos.
Unpaired Image Translation via Adaptive Convolution-based Normalization
Nov 29, 2019

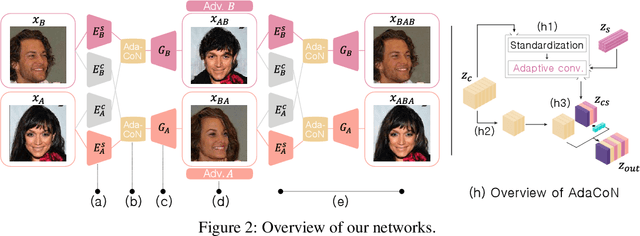
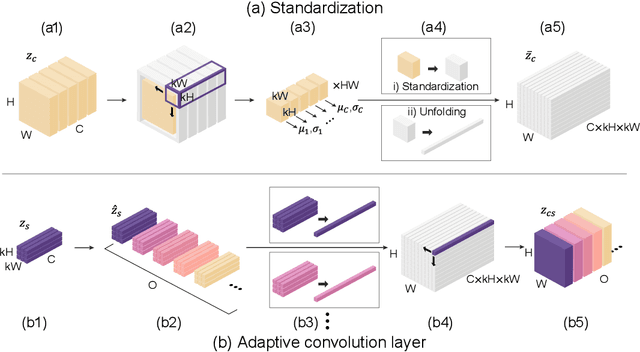
Disentangling content and style information of an image has played an important role in recent success in image translation. In this setting, how to inject given style into an input image containing its own content is an important issue, but existing methods followed relatively simple approaches, leaving room for improvement especially when incorporating significant style changes. In response, we propose an advanced normalization technique based on adaptive convolution (AdaCoN), in order to properly impose style information into the content of an input image. In detail, after locally standardizing the content representation in a channel-wise manner, AdaCoN performs adaptive convolution where the convolution filter weights are dynamically estimated using the encoded style representation. The flexibility of AdaCoN can handle complicated image translation tasks involving significant style changes. Our qualitative and quantitative experiments demonstrate the superiority of our proposed method against various existing approaches that inject the style into the content.